







一、认识RAG
1、简介
在自然语言处理领域,大型语言模型如GPT系列、claude系列、meta的LLama系列、谷歌的geminl和pemma以及阿里通义千问等等,已经取得了突破性的成就,并在多个基准测试中性能不错,但对行业领域或者高度专业化的知识仍存局限,有时会生成”幻觉”,知识也会落后一年左右时间。
在行业或者公司内部业务场景中,数据的持续更新至关重要,以确保信息的时效性,生成的内容需要透明目可追潮,这不仅有助于成本控制,也好保护教据隐私。
这是一篇同济大学、复旦大学等综合发表一篇RAG综述论文
Retrieval-Augmented Generation for Large Language Models: A Survey:https://arxiv.org/abs/2312.10997
github项目:https://github.com/Tongji-KGLLM/RAG-Survey
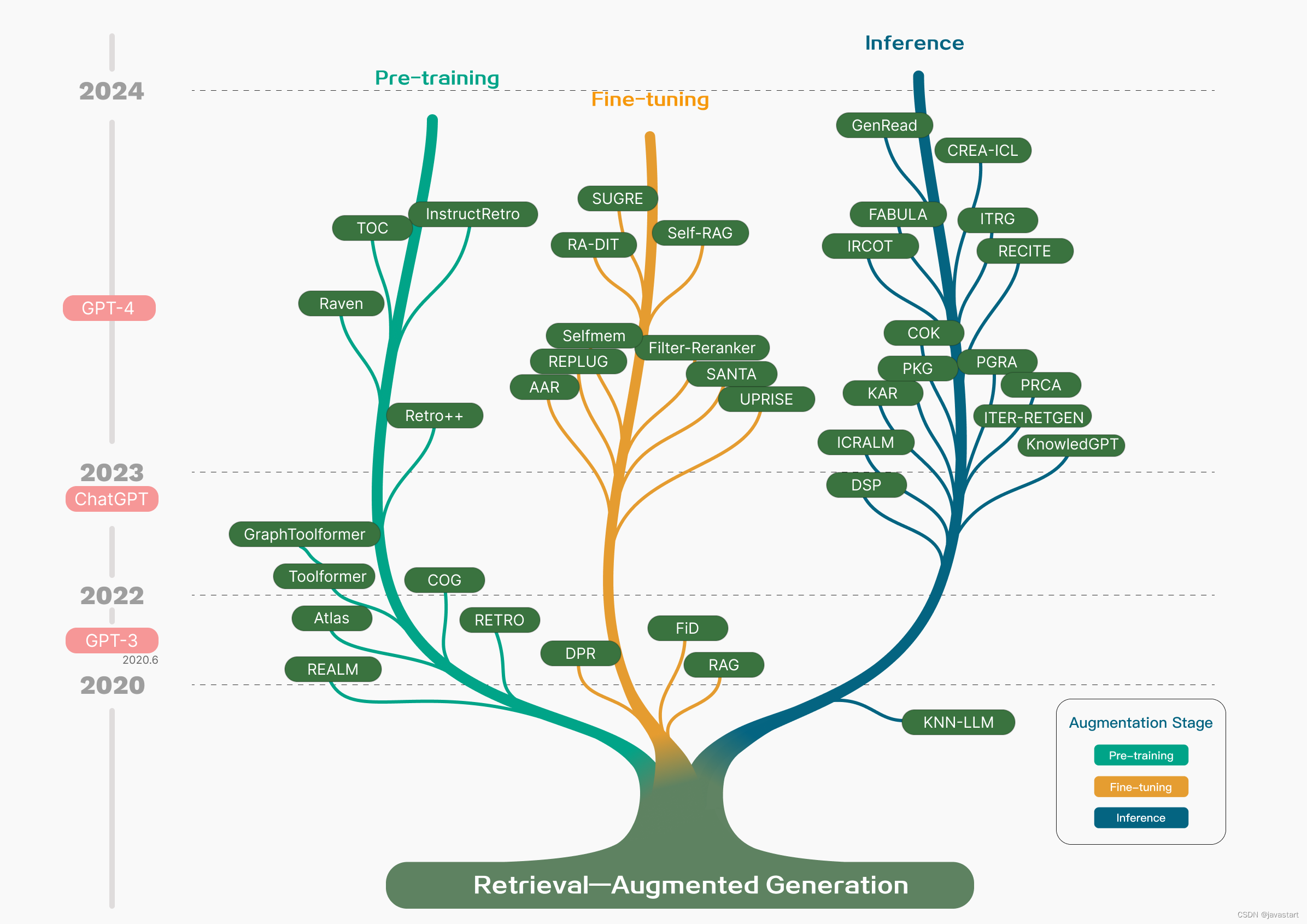
2、RAG起源
2020年左右就出现了rag技术,代表了LLM领域内增强生成任务的一种新范式。
RAG通过结合检索(Retrieval)和生成(Generation)两大核心技术,增强了大型语言模型的功能。
RAG技术在语言模型生成答案前,先从文档数据库中检索出相关信息,作为上下文被注入到LLM的提示中,然后让大模型总结生成,提高了内容准确性和相关性。
RAG技术减轻了幻觉问题,加快了知识的更新速度,并且增强了生成内容的可追溯性,从而使大型语言模型在实际应用中更加高效、可靠。
RAG技术的引入,不仅解决了生成”幻觉”的问题,而且成为行业知识A!落地,企业私有知识库,AI搜索的关键技术。
加上现在的开源模型如lama3.1,qwen2,gemma2,mistral等性能出色,RAG技术的发展成为一种混合方法,结合了RAG和微调的优势。矢量搜索领域也因RAG火热而发展迅速,像chroma,weavaite.io,pinecone等失盘数据库初创公司都以开源搜索索引(主要是faiss和nmslb)为基础基于大模型的多个著名开源库,包括LangChain,Llamalndex,AutoGen,MetaGPT等
3、RAG流程
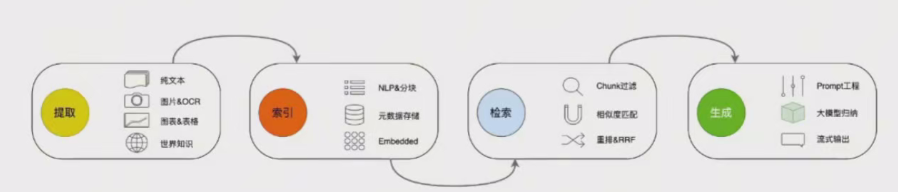
1、知识提取:首先,会从用户给定的文档、图片、表格和外部URL等资源中提取内容,涉及到pdf数据提取,表格数据提取,还有图片ocr识别后的数据提取,有网页文档数据的提取,包括结构化数据和非结构化数据。
2、知识索引:然后通过chunking(可以认为是将连续的文本分成一个个小块)进行合理切割,再使用embedding将文本变成向量教据存入向量数掘库或elasticsearch等数据库中。结合这些非结构化文件所附带的元教据(时间、文件名、作者、副标题、文件类型等)进行索引(高级索引可以是树结构、图结构等)创建。
3、知识检索:当RAG接受到用户提问内容,先将内容通过embedding转化为向量数据,然后和前面建立的索引进行相似度匹配,系统优先检素与query最相似的前K个块,比如从百万的chunks中找出匹配度较高的100个。然后再将这100个chunk进行更耗时也更精准的重排序(使用交叉熵校验的Rerank算法),将最相关的top3结果找到。
4、生成:最后RAG会用户问题、经过技术处理的top3的chunks,还有prompt,一起送入大语言模型,让它生成最终的答案。
4、RAG优缺点
(1)RAG的优势
RAG结合大语言模型,可以解决大语言模型本身存在的4个主要问题:
私有数据和时效性:大语言模型可以通过预训练和监督微调(SFT)将私有教据(如您公司的业务文件等数据)压缩到模型中。预训练和微调成本都比较高,实时性也不强,技术门楹也高不少,与企业内部最新鲜私有教据进行对话还是存在很大难度的,而RAG则是采用”外脑”的方式处理这个问题,只要用户将最新的资料进行上传,即可与这些文件进行对话,让他们告诉你想要的答案,将知识时效性快速提升。
幻觉问题:通过检索相关知识,RAG能够提供更准确、更相关的答案,减少模型的幻觉现象,在涉及到公司最新动态,或者数据权限问题的时候,可以在检索简单提供权限控制,甚至可以设置在检索召回内容质是不高的情况下,禁止大模型介入,而是直接回复“不知道”,或者没有权限。
增强可解释性:由于RAG生成的文本基于可检索的知识,因此用户可以验证答案的准确性,并增加对模型输出的信任,这在行业领域和专业领域非常必要,比如医疗健康,教育,法律,金融等。
数据安全问题:对于数据安全要求极高的企业用户,如果不想使用在线大语言模型(如ChatGPT、通义千间、文心一言等),那么可以采用完全本地化部署,RAG配合百亿级别参数的可本地部署大模型即可提供绝大多数A!服务,还让企业教据确保不出内网,另外还有一个角度就是访问权限控制,我们肯定不希望刚进来的实习生也能通过对话知道公司还未发布的财务数据,这些都是RAG作为LLM的外脑可以做到的事情。
(2)RAG缺点
1、性能和效率问题:RAG技术在实际应用中,尤其是在数据丰富且复杂的企业环境中,可能会遇到性能和效率的问题,比如检索数据量大,比较耗时,然后大模型多轮对话和评分也比较费时间。
2、低命中率问题:当用户意图明确时,RAG技术可能无法提供高召回率或精度,导致命中率较低,此外,如果用户意图不明确,RAG系统可能无法直接作答,存在语义gap,简单的检索方式难以找到答案。
3、语义搜素的不准确:语义搜索的难点在于如何理解用户的问题和文档的语义,以及如何衡量问题和文档之间的语义相似度,向量空间中的距离或相似度并不一定能反映真实的语义相似度,检索能力没有大横型的语义理解能力,导致检索出的内容相关系不强,当然比如graphRAG能缓解很多。
4、冗余和重复也是一个问题:特别是当多个检索的段落包含相似的信息时,会导致生成的响应中出现重复的内容。
5、Native Rag
RAG现在发展出三种类型:Naive RAG(朴素RAG)、Advanced RAG(高级RAG)和Moduar RAG(模块化RAG)。
RAG在成本效益上超过了原生LLM,但也表现出了几个局限性,这也更大家一个印象:入门容易,做好难。
Advanced RAG和Modular RAG的发展是为了解决Naive RAG中的缺陷。
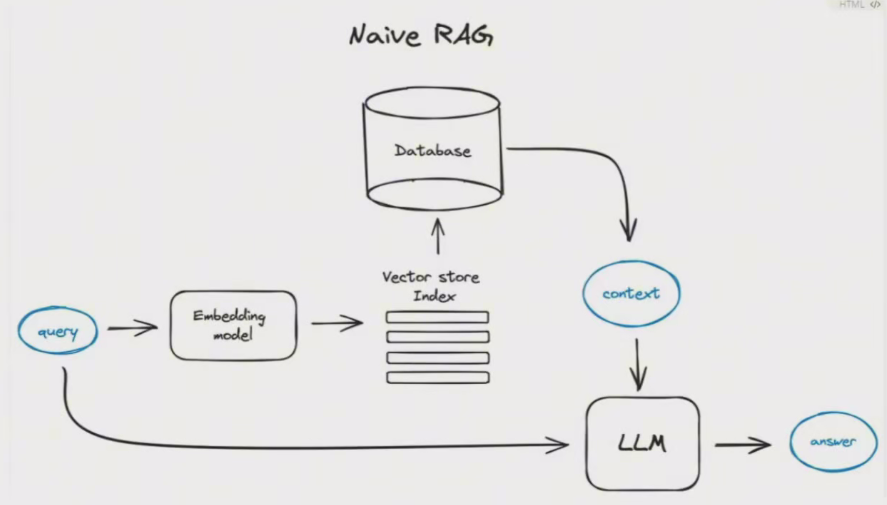
Naive RAG遵循一个传统的流程,包括索引、检索和生成。它也被称为“检索·阅读”框架。
朴素RAG的典型工作流程图:
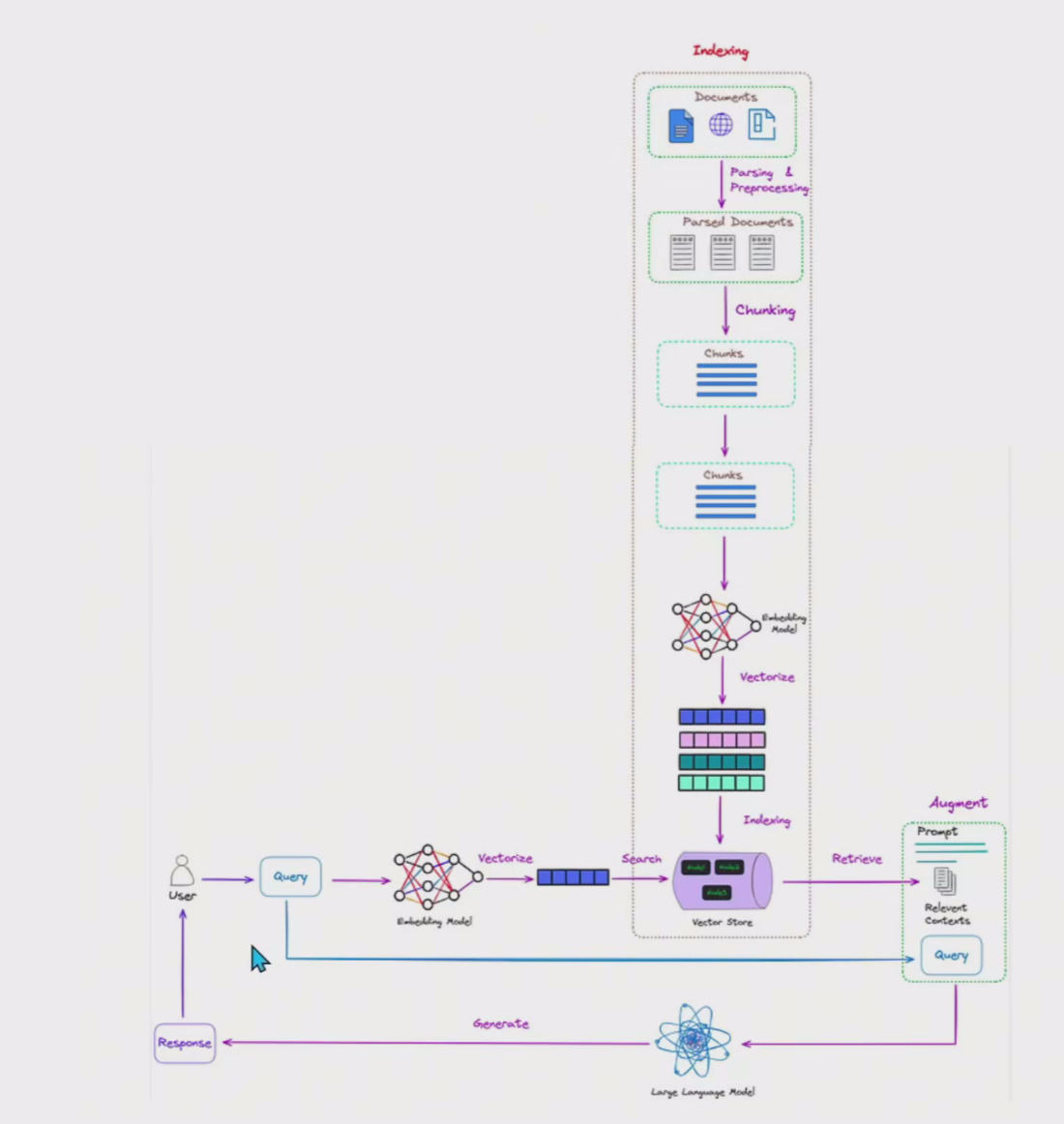
6、Advanced RAG
(1)简介
Advanced RAG是为了解决Naive RAG的局限性而开发的。
在检索质量方面,Advanced RAG实现了预检索和后检素策略。
为了解决Naive RAG在索引方面的挑战,Advanced RAG通过滑动窗口、细粒度分割和元数据等技术优化了索引方法,它还引入了各种方法来优化检索过程。
数据清洗与优化
确保输入数据的质量,删除无关内容,不能识别内容,如特殊字符、停用词等,并纠正错误,以提高语义表示的质量,确认事实准确性、更新过时信息等。
提取方式
支持各种数据提取,有web网页,pdf文档,ocr识别,各种表格等等
llamaindex reader文档:https://docs.llamaindex.ai/en/stable/api_reference/readers/
索引(index)
索引优化主要体现在chunks分块优化和索引优化上,数据索引优化技术旨在以有助于提高检索效率的方式存储数据。
滑动窗口
平衡这些需求的一个简单方法是便用重叠块。滑动窗口使chunks之间重叠,语义转换得到增强,然而,也存在局限性,包括对上下文大小的控制不精确、单词或句子被截断的风险以及缺乏语义考虑。
添加元数据
llamaindex metadata提取文档:https://docs.llamaindex.ai/en/stable/api_reference/extractors/
例子:https://docs.llamaindex.ai/en/stable/examples/metadata_extraction/EntityExtractionClimate/
利用额外的信息(元数据)来帮助检索过程,从而提高生成内容的相关性和质量。
元数据可以包括各种类型的信息,如文档的标题、作者、发布日期、标签或任何其他描述性教据,甚至如网页标签的alt数据等等,这些教据用来提高检索系统的准确性和效率。
人工构建元数据也是一种思路,比如给每个段落增加摘要、引入可能的假设性问题等。在检索时计算原始问题和假设问题之间的相似度,从而减少问题与答案之间的语义差距,提高效果。
知识图谱
知识图谱Knowledge Graph也是元数据的一种,知识图谱通过提供结构化的、关系丰富的信息,帮助系统更好地理解和处理查询(如实体),从而增强生成内容的相关性和准确性。
构建KG的过程较为复杂,质量波动较大,并且维护成本较为麻烦,应用门槛较高,相对而言使用起来不太方便。
使用KG来组织多个文档,可以参考这研究论文Knowledge Graph Prompting for MultiDocument Question Answering :https://arxiv.org/abs/2308.11730
llamaindex知识图谱文档: https://docs.llamaindex.ai/en/stable/api_reference/indices/knowledge_graph/
(2)索引优化
层次化索引结构
把文档内容构建出层次结构,即:分层索引结构,可以加快数据的检索和处理。
把文件以父子目录的关系排列,通过数据块链接到它们,把数据摘要存储在每个节点上,有助于快速遍历数据并协助RAG确定目标数据块。
利用层次结构构建知识图谱索引,有助于数据结构的保持一致性,阐述了不同概念和实体之间的联系,减少幻觉的可能性。
总分层级索引(总->细,提高搜索的效率)
创建多层级索引,如第一层索引由摘要组成,另一层由摘要对应的一或多个文档块组成,并分两步检索,首先将query与摘要匹配过滤掉不相关的文档,并只在相关组内检索第二层文档块。
这种方式虽然能够通过快速缩小范围的方式来减少检索时间,但是可能考虑到摘要的信息的完整性,这种方式可能会在第一层匹配时忽略掉文档的细节信息,从而导致检索的准确性降低。个人认为,当知识库巨大,而且文档块的内容较为单一时可以使用
比如:行业-》公司-》文档-》chunk
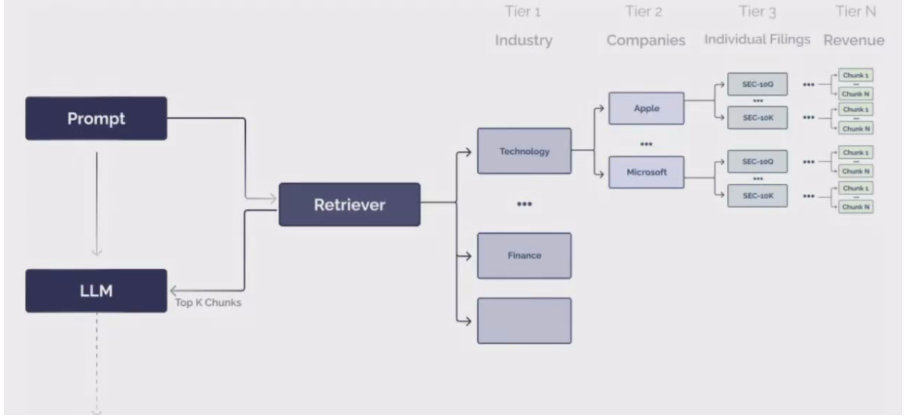
利用元数据进行多层次过滤:https://docs.llamaindex.ai/en/stable/examples/query_engine/multi_doc_auto_retrieval/multi_doc_auto_retrieval/
父子层级索引(细->总,提高搜索精确问题的准确性)
同样创建多层级索引
如:先将文档按一定方式切分成较大的文本块,形成 parent chunks;在对每个parent chunk按更细的方式切分成 child chunks,每个child chunk 都有一个其所对应的 parent index。
query 检索时,在 sub chunks中进行检索,后依据被检索到的sub chunks所对应的 parent index 回至父段块(目的是为了获得更完整完整的上下文),以父段作为最终的增强信息获得答案。
在匹配时完全依据语义和关键词,能够减少噪音,尤其能够优化当query所对应的有效信息较为简短时 parent 所面临的匹配不敏感问题。
这个也就是Small2Big方法:使用句子做检索单元(这个是small),使用前句和后句做上下文(这个是big)
Treelndex
Llamalndex中的Treelndex是一个分层的树结构索引,其中每个节点都总结了其子节点,在索引构建过程中,树是自下而上构建的,直到形成一组根节点。
以下是一些关键特征:
节点摘要:树中的每个节点都是其子节点的摘要。
自下而上构造:树是从下往上构造的,从叶节点开始,向上移动到根节点。
查询:在查询期间,可以从根节点向下谝历树到叶节点。或者,可以直接从根节点合成答案。
句子窗口索引
为了实现更细粒度的检索,我们可以将文档解析为每个块一个句子,而不是便用较小的子块。
单句类似于“子“块概念。句子“窗口”(原句两边各5个句子)类似于”父”块概念。换句话说,我们在检索过程中使用单句,并将检索到的句子与句子窗口一起传递给LLM。
多种切分方式井行查询
向量检索中chunks的大小以及部分符号会对相似度结果产生较大影响(这种影响在chunks内容相似时尤其明显)。
当chunks过小时,没有上下文信息,可能导致宽泛性query 匹配不准确,但能够匹配精准的问题。
当chunks过大时,chunk涵盖的信息多,将导致精确的问题匹配时存在噪音,而忽略了chunks中的准确答案。
因此为了增加稳健性,采用机器学习中的 ensembe方式,可以同时构建多个chunks 数据集,每个数据集的chunks大小不同(一般依据文档的内容数量选择2-3个切分方式即可),采用并行的方式进行同时匹配。并进行集中排序,选择top_k个文本块作为增强内容。
能够显著提升检索的准确率和鲁棒性,但是也会消耗存储资源和匹配时间,更适合文档数量级较小的情况下,当文档量级非常大,将大大增加资源的消耗。
chunk的大小是一个需要重点考虑的参数,它取决于我们使用的Embedding模型及其token的容量
并行优化例子:https://docs.llamaindex.ai/en/stable/examples/ingestion/parallel_execution_ingestion_pipeline/
多chunks大小索引和查询:https://docs.llamaindex.ai/en/stable/examples/retrievers/ensemble_retrieval/
(3)预检索过程(Pre-Retrieval Process)
预检索过程集中在数据索引优化和查询优化上。
提示词优化
https://docs.llamaindex.ai/en/stable/examples/prompts/advanced_prompts/
提示词改写:
原始查询并不总是最适合 LLM 检索,尤其是在实际场景中,可以让LLM 重写查询,显著提升了长尾查询的召回效果。
这有一篇论文:Query Rewriting for Retrieval-Augmented Large Language Modelshttps://arxiv.org/pdf/2305.14283
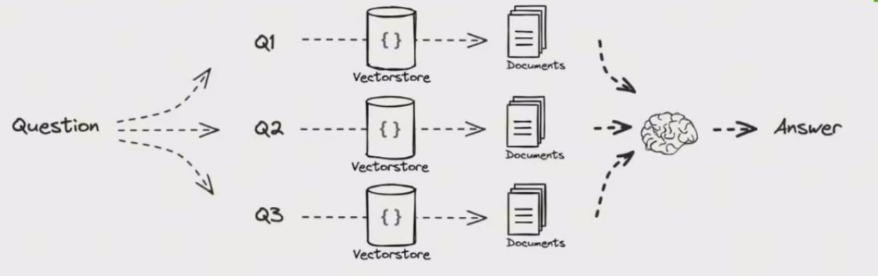
子查询
对于复杂的查询,大语言模型将其拆分为多个子查询。
比如,当你问:
“在 Github 上,Langchain 和 Lamalndex 这两个框架哪个更受欢迎?“,直接在语料库的文本中找到它们的比较比较难,所以将这个问题分解为两个更简单、具体的子查询是合理的:
“Langchain 在 Github 上有多少星?”
“Llamaindex 在 Github 上有多少星?"
这些子查询会同时进行,检索到的信息随后被汇总到一个语句中,供大语言模型综合出对原始查询的最终答案。
这两个功能分别在 Langchaln 中以多查询(multiQuery)检索器的形式和在 Llamaindex 中以子问题查询引擎的形式实现。
HyDE(假设答案)
在查询时,LLM 先根据问题生成一个假设答案,而不是直接在向量数据库中搜索查询及其计算向量。
它侧重于从答案到答案的嵌入相似性,而不是寻求问题或答案的嵌入相似性,此外,它还包括Reverse HyDE,它侧重于从查询到查询的检索。
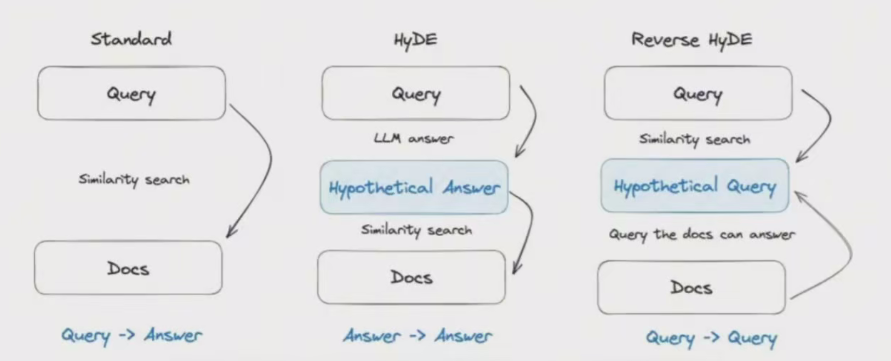
比如有人问必胜客最吃的菜是什么,这个问题暗示了对食物的关注。难点在于没有指定具体的食物,因此直接计算相关性比较困难,为了解决这个问题,可以让大语言模型先编写一个假设性的答案,然后将其转化为嵌入向量,这些嵌入向量然后在向量数据库中根据语义相似性进行检查,以帮助寻找相关信息。
HyDE和 Reverse HyDE,核心思想都是在查询和答案之间架起桥梁。
Reverse HyDE(假设问题)
利用大型语言模型(LLMs)根据给定的文档内容每个分块生成一系列假设性问题,这些问题应该能够被该文档所回答,这些问题向是构成一个索引,用于对用户的查询进行匹配搜索(这里是用问题向量而非原文档的内容向量来构成索引),检索到相应问题后,再链接回原始文档的相应部分,作为大语言模型提供答案的背景信息
CoVe
使用Meta AI 提出的Chain-of-Verification:https://arxiv.org/abs/2309.11495,扩展后的查询经过LLM 的验证,以达到减少幻觉的效果,经过验证的扩展查询通常具有更高的可靠性。
(4)检索过程(Retrieval)
检索阶段的目标是确定最相关的上下文
通常,检索基于向量搜索,它计算查询与索引数据之间的语义相似性
大多数检索优化技术都围绕嵌入模型展开
微调Embedding
将Embedding模型在特定行业或者领域微调,一些术语或者词语在通用领域可能相关性不大,但在某一个行业,一些术语或者词语可能有相关性。例如,BAAI/bge-small-en是一个高性能的嵌入模型,可以进行微调。
动态Embedding
根据单词的上下文进行调整,相同的单词可以根据周围的单词具有不同的嵌入,而静态嵌入则为每个单词使用单一向量。例如,OpenAl的embeddings-ada-02是一个复杂的动态嵌入模型,可以捕获上下文理解。
除了向量搜索之外,还有其他检索技术,例如混合搜索,通常是指将向量搜索与基于关键字的搜索相结合的概念。如果您的检索需要精确的关键字匹配,则此检索技术非常有益。
一般检索过程使用通用模型,在面对垂直领域时效果不一定很好,这些模型参数量比通用 LLM 小很多。
(5)后检索过程(Post-Retrieval Process)
在高级RAG的应用中,会有”检索后处理(Post-Retrieval)”的环节。
在检索出输入问题相关的多个Chunk后,交给LLM合成答案之前的一个处理环节。
可以做一些诸如相似度过滤、关键词过滤、chunk内容替换等处理,其中,Rerank(重排序)是一种常见的,也是在RAG应用优化中很常见的一种技术处理环节。
将其与query作为输入合并到LLMs中时,解决上下文窗口限制带来的挑战至关重要。
简单地一次性向LLMs展示所有相关文档可能会超过上下文窗口限制,会引入噪声,并阻碍对关键信息的关注,因此,对检索到的内容进行额外处理是必要的。
Rerank
Rerank就是对检索出来的多个chunks列表进行重新排序,使得其排名与用户输入问题的相关性更匹配,使得更相关、更准确的chunk排名更靠前,从而在 LLM生成时能够被优先考虑以提高输出质量,以此增加MMR以及命中率。
有了基于向量索引与语义相似度的检索,为什么还需要Rerank?
1、RAG应用中有多种索引类型,很多索引技术并非基于语义与向量构建,其检索的结果希望借助独立的Rerank实现语义重排。
2、在一些复杂RAG范式中,很多时候会使用多路混合检索来获取更多相关知识;这些来自不同源、不同检索算法的chunks要借助Rerank做重排。
3、即使是完全基于向量构建的索引,由于不同的嵌入模型、相似算法、语言环境、领域知识特点等影响,其语义检索的相关度排序也可能发生较大的偏差;此时借助独立的Rerank模型做纠正也非常有意义。
4、同时LLM 的输入token长度具有限制,排名之后top-k,也能减少大语言模型的上下文输入长度,降低成本
提示压缩(Prompt Compression)
在RAG(检索增强生成)模型的后检索阶段,提示词压缩(Prompt Compression)是一项关键技术,它通过精简输入给大型语言模型(LLMs)的上下文信息。
从本质上讲,其目的是精炼提示词中的关键信息,使得每个输入的词元(input tokens)都承载更多价值,从而提升横型效率并还能控制成本。
通过某种方式,构造一种专属于LLMs的语言。
这种语言很有可能人类很难理解,但是LLMS可以很好的理解。
例如LLMLingua和LongLLMLingua、LongLLMLingua2,这些方法通过计算每个token的自信息或困惑度,然后删除那些困惑度较低的token来实现压缩。
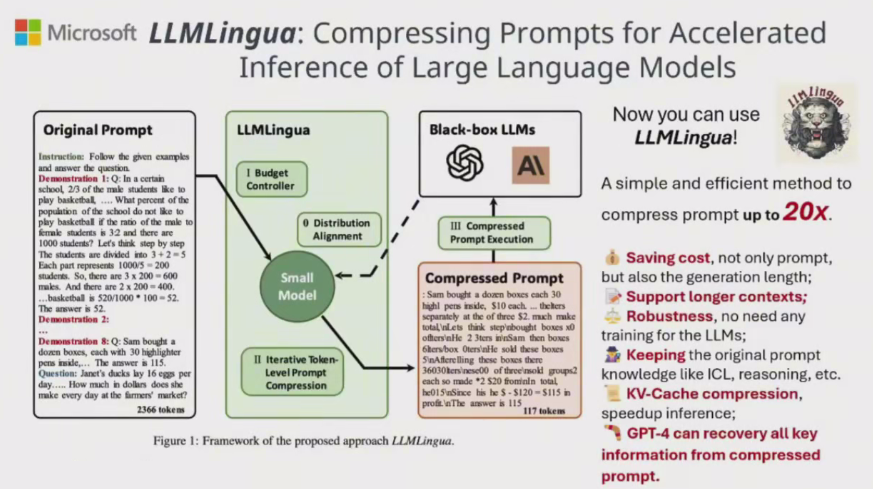
LLMLingua
LLMLingua利用紧凑且训练有素的语宫横型(例如 GPT2-smal、LLaMA-7B)来识别和别除提示中的非必要标记。这种方法能够利用大型语言横型(LLM)进行高效推理,实现高达 20 倍的压缩率,同时将性能损失降至最低。
LongLLMLingua
LongLLMlLingua出发点和LLMLingua就不太一样了,不只是想要压缩prompt保证少掉精度,而是想要在Long Context Scenarios下,通过提升prompt中的信息密度,从而提升LLMs的性能。
仅便用 1/4 的标记即可将 RAG 性能提高高达 21.4%
LongLLMLingua2
LLMLingua-2 是一种小型但功能强大的快速压缩方法,通过从GPT-4进行数据蒸馏训练,使用 BERT级编码器进行标记分类,在任务无关压缩方面表现出色。它在处理域外数据方面超越了 LLMLingua,性能提高了3到6倍
(6)融合或混合检索
混合搜索
进行相似度搜索有2种方式,包括 sparse 检索和 dense 检索。
embedding 向量化索引是 dense 检索的代表,而TF-IDF和BM25是 sparse 检索的代表。
dense 检索的方式更专注于query 和 chunks的语义关系,可能导致某些存在明显关键词的chunks 由于语义不足没有被检索出来,稳健性较弱,使用 sparse 检索方式进行ensemble,增强稳健性
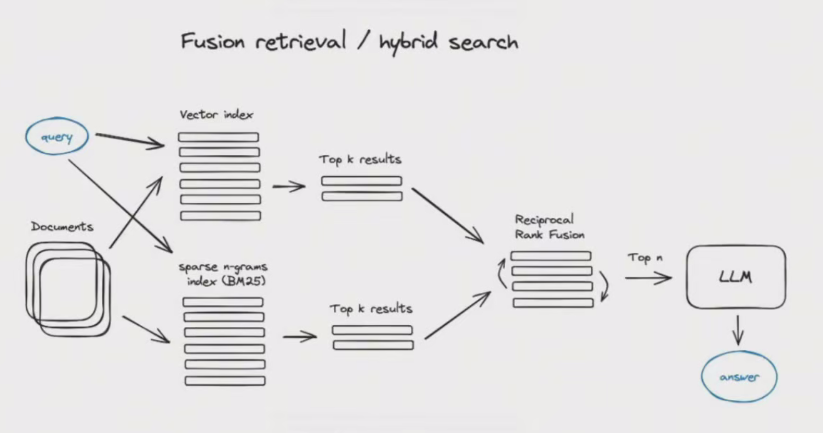
融合
RAG 融合(rag fusion),主要思想是在Multi Query的基础上,对其检索结果进行重新排序(即reranking)后输出TopK个最相关文档,最后将这topK个文档喂给LLM,并生成最终的答案(answer)。
如下图所示:
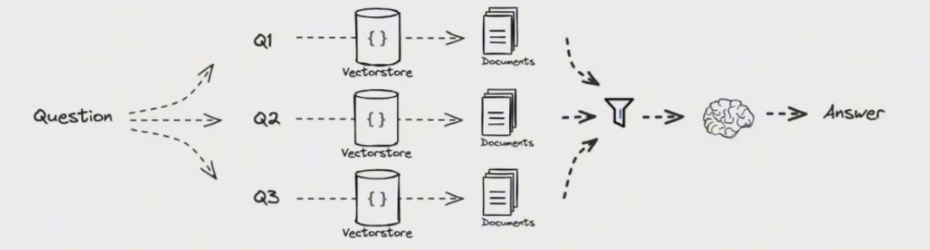
排序包含两个动作:
一是独立对每个question检索返回的内容根据相似度排序,确定每个返回chunk在各自候选集中的位置,相似度越高排名越靠前,这一步采用rerank技术为主。
二是对所有question 返回的内容利用RRF(Reciprocal Rank Fusion)综合排序,RRF排序原理如下图所示。
这也说明白了rerank和rrf之间的差别。
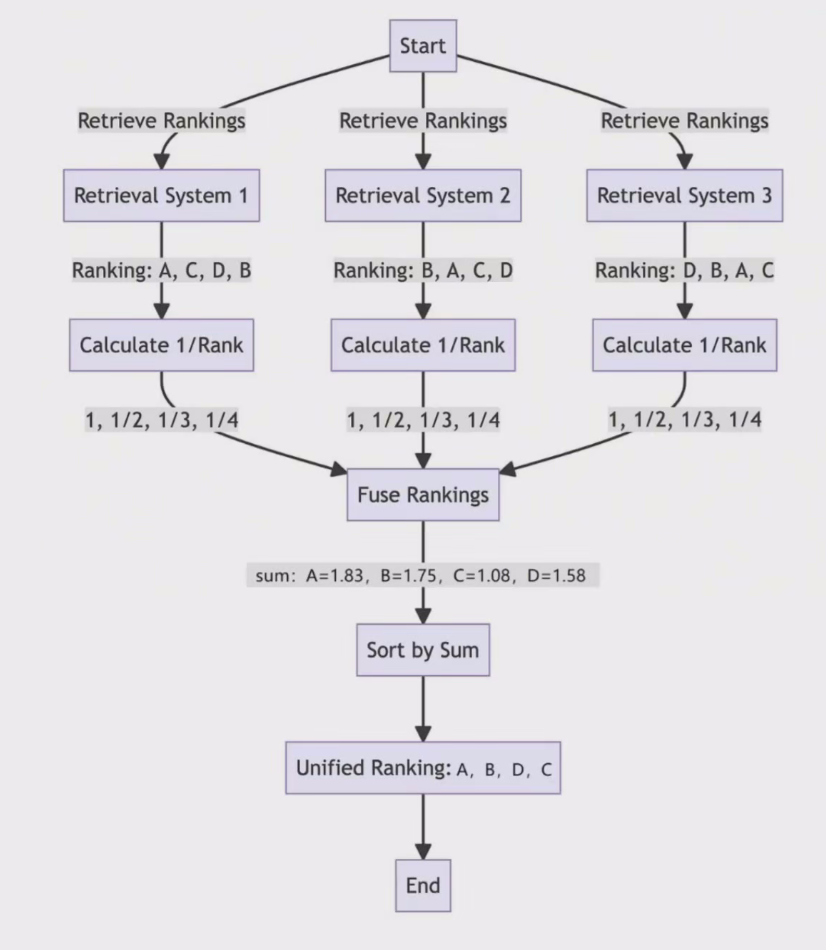
RRF score的计算公式非常简单:
score=1/(rank+k)
其中,rank是按照距高排序的文档在各自集合中的排名,K是常数平滑因子,一般取k=60,RRF将不同检索器的结果综合评估得到每个chunk的统一得分
7、Modular RAG
(1)简介
Modular RAG结构与传统的Naive RAG框架不同,Advanced RAG是Modular RAG的一种特殊形式,而Naive RAG本身是Advanced RAG的一个特例,Modular RAG结构提供了更大的多样性和灵活性,它整合了各种方法来增强功能模块。
以下几个重要方面:
1.增强数据采集: RAG 已经超越了传统的非结构化数据,现在包括半结构化和结构化数据,重点是对结构化数据进行预处理,以改进检索并减少模型对外部知识源的依赖。
2.结合技术:RAG 正在与其他技术相结合,包括使用微调、适配器模块和强化学习来加强检索能力。
3.可适应的检索过程:检索过程已发展到支持多轮检索增强,使用检索内容来指导生成,反之亦然。此外,自主判断和 LLM 的使用通过确定检索需求提高了回答问题的效率。
(2)三层架构
模块化 RAG 提供了一种高可扩展的范式,将 RAG 系统划分为Module Type、Module 和 Operator三层结构,每个Module Type 代表 RAG 系统中的一个核心流程,包含多个功能模块,而每个功能模块又包含多个具体的 Operator。整个RAG 系统就变成了多个模块和对应Operator 的排列组合,形成了我们所说的 RAGFlow。在 Flow 中,每个 Module Type 中可以选择不同的功能模块,而每个功能模块中又可以选择一个或多个 Operator。
在此范式下,当前 RAG体系中的核心技术,涵盖6大Module Type、14个Module和40+Operator,旨在提供对 RAG 的全面理解Modular RAG(模块化检索增强生成)的三层架构是其核心特点之一,提供了一个高度可重构的框架,以适应不同的应用场景和需求,这三层架构具体包括:
1、顶层(Module Type):顶层关注RAG的关键阶段,每个阶段都被视为一个独立的模块。
这一层继承了高级RAG范式的主要流程,并引入了一个编排模块来控制RAG流程的协调。
顶层的模块类型包括索引、预检索、检索、后检索、生成和编排,它们代表了RAG系统中的核心流程。
2、中间层(Module):中间层由每个模块类型内的子模块组成,进一步细化和优化功能。这些子模块负责处理特定的功能或任务。
例如索引模块可能包含块优化和结构组织等子模块,而检索模块可能包含检索器选择和检索器微调等子模块。
3、底层(Operator):底层由基本操作单元一一操作符构成。操作符是模块内的具体功能实现,是RAG系统中的构建块。
例如,索引模块内的操作符可能负责将文档分割成块、优化块的大小和重叠大小、或者为块附加元数据等
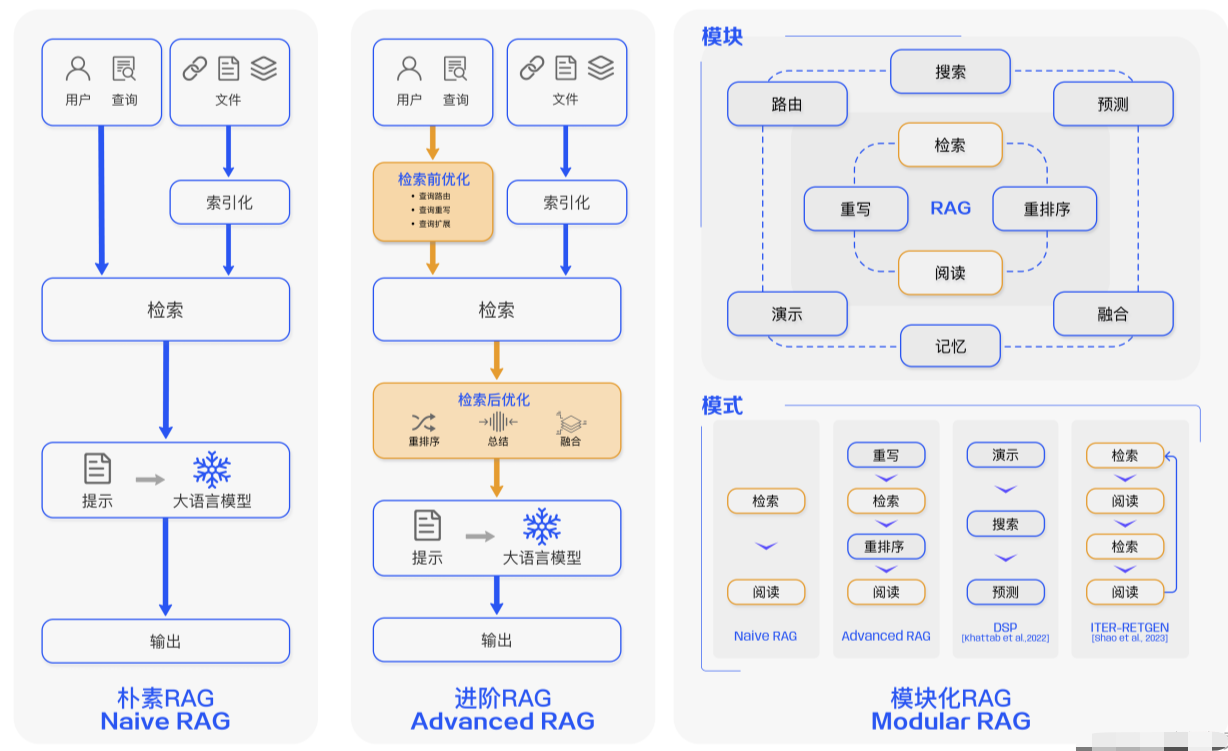
模块化RAG的好处显而易见,为现有的RAG相关工作提供了全新而全面的视角。通过模块化的组织方式,相关技术和方法被清晰地概括出来。
研究视角。模块化 RAG 具有高度可扩展性,方便研究人员在全面了解当前 RAG 开发的基础上提出新的模块类型、模块和运算符。
应用层面。RAG系统的设计与构建变得更加便捷,用户可以根据已有数据、使用场景、下游任务等需求定制 RAG Fow,开发者也可以参考现有的 (参考RagFlow)Flow 构建方式,根据不同的应用场景和领域定义新的流程和模式。
(3)Tuning 阶段
主要包括三个模型的微调,Retriever微调,reranker微调,Generator 微调,有时候只需要调一部分,有时候则3个都需要调。
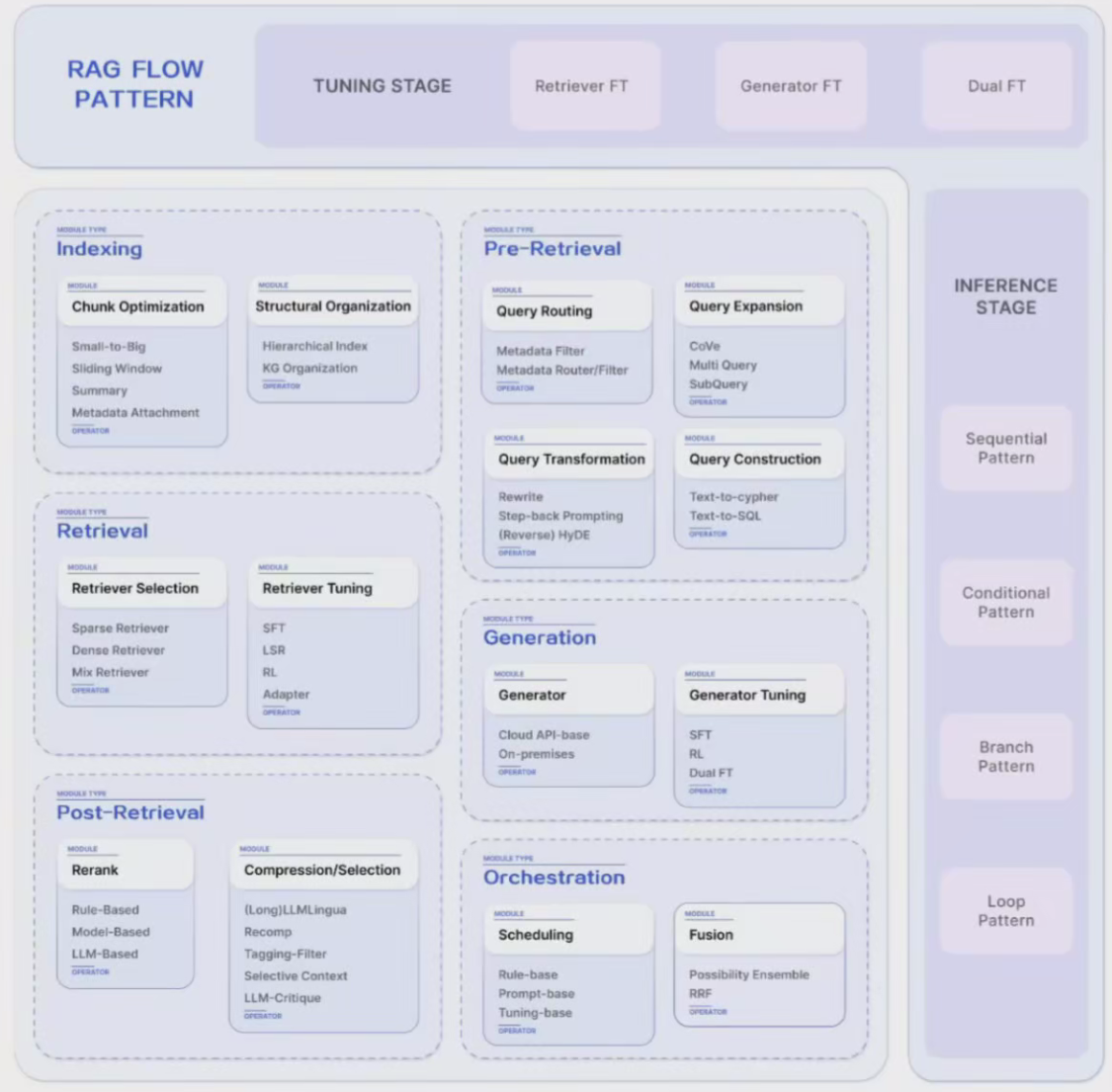
Retriever 微调
在RAG Flow中,对Retriever器进行微调,也就是微调embedding模型,常用方法包括:
直接微调检索器:构建专门的Retriever数据集来微调Retriever。例如,使用开源检索数据集或基于特定领域的数据构建一个数据集。
LM监督微调Retriever(LSR):根据LLM 生成的结果对检索器进行微调。
LLM Reward RL:依然以LLM的输出结果作为监督信号,利用强化学习将检索器与生成器对齐,整个检索过程以生成马尔可夫链的形式拆解。
reranker微调
后面细讲如何用业数据或者私有知识来微调reranker模型
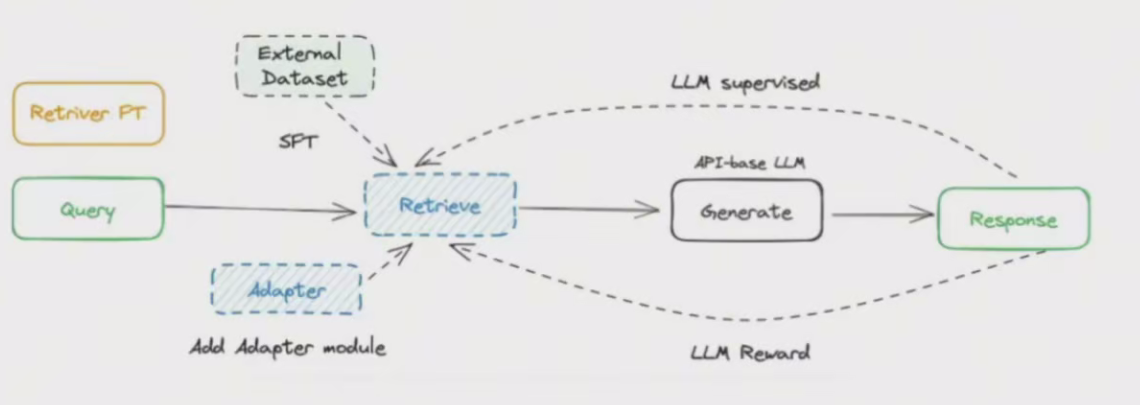
Generator 微调
微调大语言模型,比如用行业知识,企业私有知识库来微调,或者预训练等
(4)推理阶段
在推理阶段,有四种典型的RAG Fow模式
(5)推理阶段 - 顺序模式
RAG Flow 的顺序结构将 RAG 的模块和运算符组织成线性流水线,如果它同时包含 Pre-Retrieval和 Post-Retrieval模块类型,就是典型的 Advanced RAG 范式;把Pre-Retrieval和 Post-Retrieval 去掉就是典型的 Naive RAG 范式。

目前使用最广泛的 RAG Pipeline 是 Sequential,常见的包括检索前的 Query Rewrite 或 HyDE,检索后的 Rerank 操作

重写-检索-阅读(RRR)
重写-检索-阅读(RRR)也是典型的顺序结构。
查询重写模块是一个较小的可训练语言模型,在强化学习的背景下,重写器的优化被形式化为马尔可夫决策过程,以LLM 的最终输出作为奖励。检索器采用稀疏编码模型 BM25。

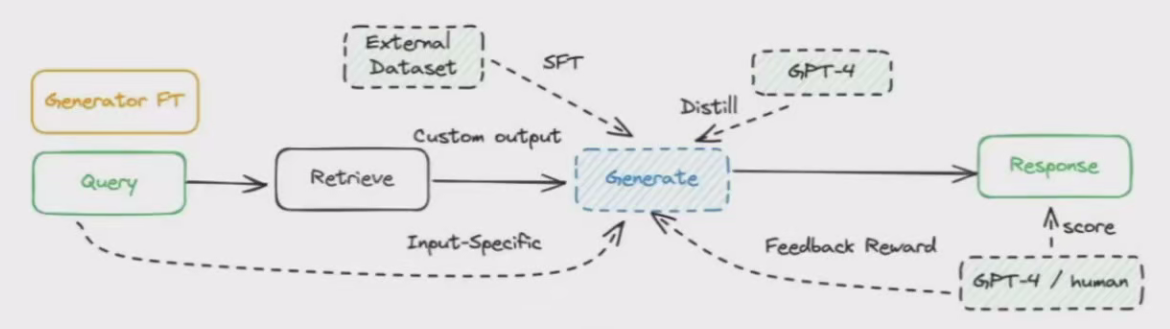
(6)推理阶段 - 条件模式
具有条件结构的 RAG Flow 涉及根据不同的条件选择不同的RAG 路径。
通过基于查询关键字或语义确定路线的路由模块来实现的
-元数据路由器/过滤器:居块中的关键字和元数据进行筛选,以缩小搜索范围。
-语义路由器:利用查询的语义信息。也可以采用混合路由方法,将基于语义和元数据的方法相结合,以增强查询路由。
根据问题类型选择不同的路由,针对不同场景引导不同的流程。
例如,当用户查询严肃问题、学习问题或娱乐话题时,对大模型答案的容忍度是不同的,不同的路由分支通常在检索源、检索流程、配置、模型和提示方面有所不同。
条件 RAG 的经典实现是semantic-router这个项目:https://github.com/aurelio-labs/semantic-router
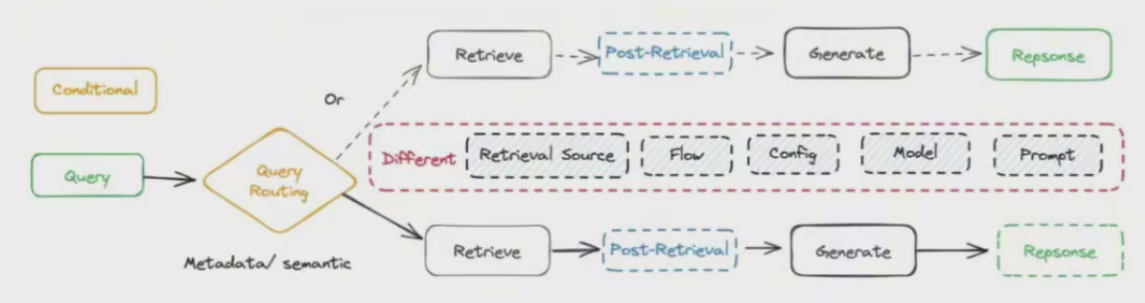
(7)推理阶段 - 分枝模式
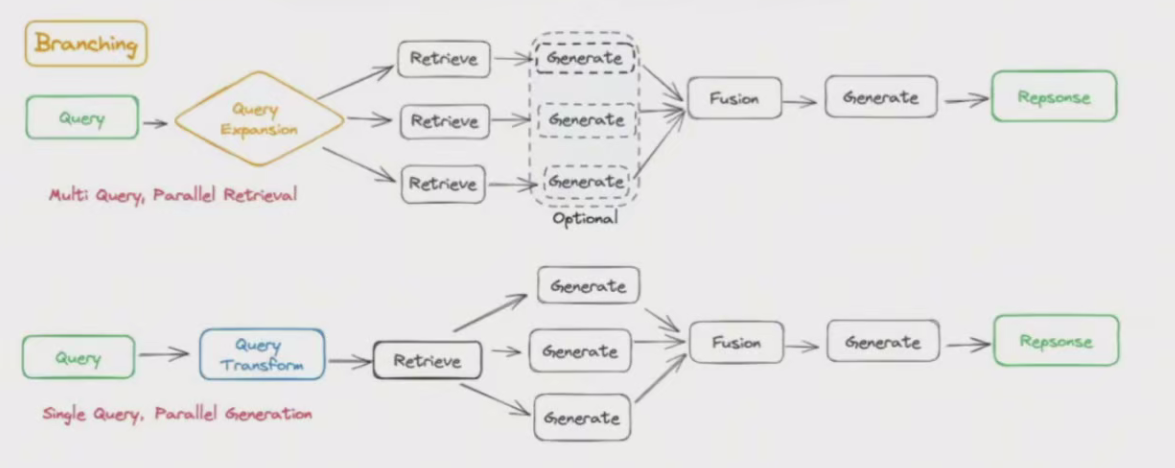
具有分支结构的 RAG Flow 与条件方法的不同之处在于,它涉及多个并行分支,而不是像条件方法那样从多个选项中选择一个分支。
从结构上来说,可分为两类:
-检索前分支(多查询、并行检索)。将原查询扩展为多个子查询,然后对每个子查询进行单独检索。检索完成后,根据子问题和对应的检索内容立即生成答案。或者,也可以只使用扩展后的检索内容,将其合并到统一的上下文中生成答案。
-检索后分支(单个查询,并行生成)。此方法保留原始查询并检索多个文档块,随后,它同时使用原始查询和每个文档块进行生成,最后将生成的结果合并在一起。
(8)推理阶段 - 环形模式
模块化RAG的一个重要特征是 RAG Fow 具有循环结构,其中包含相互依赖的检索和推理步骤,它通常包含用于流程控制的judge 模块。
进一步分为迭代、递归、自适应(主动)检索方法。
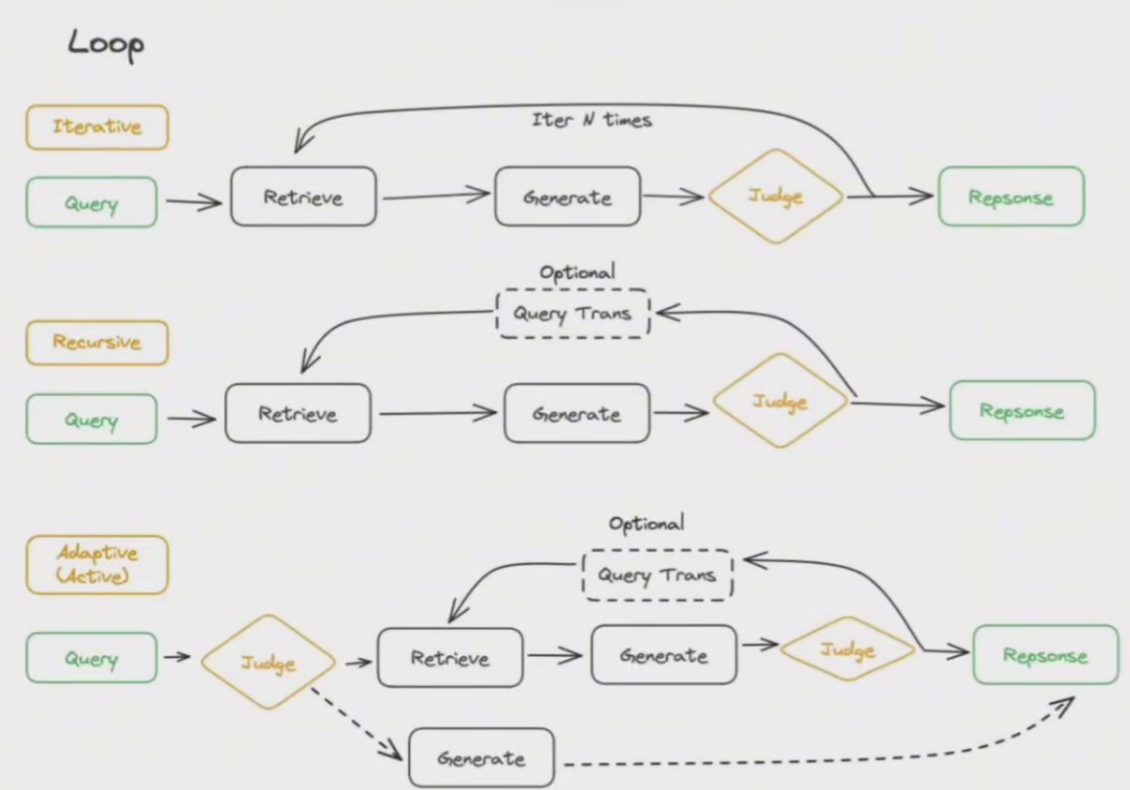
(9)推理阶段 - 环形模式 - 迭代检索
有时,单一的检索和生成得到的答案质量不能满足要求。需要 RAG 使用多次迭代方法,通常涉及固定数量的检索迭代。
迭代检索的一个典型案例是ITER-RETGEN:https://arxiv.org/abs/2305.15294,它迭代检索增强和生成增强。
在每次迭代中,ITER-RETGEN利用上一次迭代的模型输出作为特定上下文来帮助检索更相关的知识。循环的终止由预定义的选代次数决定
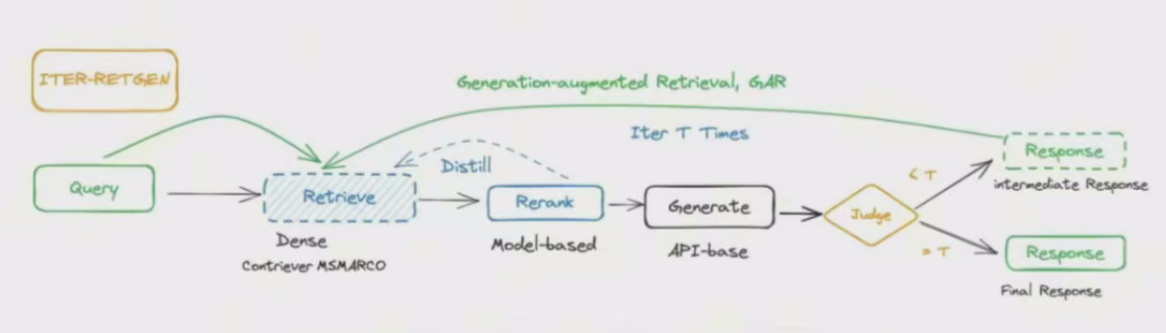
如下迭代过程:

对于给定的问题q和检索语料库D=(Dq},其中Dq表示一个段落,ITER-RETGEN连续执行T次检索生成迭代。
在每次迭代t中,我们首先使用上一次选代的生成Yt-1,将其与q组合,并检索前k个段落。
接下来,我们提示LLM生成输出Yt,该输出Yt将检索到的段落(表示为DYt-1 || q)和q合并到提示中
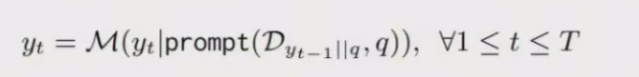
最后的输出Yt将作为最终结果产生。
(10)推理阶段 - 环形模式 - 递归检索
递归检索与迭代检索相比,就是明确依赖上一步,不断深化检索,主要是改写查询和扩展查询。
终止条件也是设置最大深度。
在RAG中涉及查询转换,将模糊的查询逐步改写成明确的查询,每次检索都重写查询。
对应处理需要多跳推理或多层次解析的复杂查询时特别有用。

1、澄清树(TOC)
论文Tree of Clarifications: Answering Ambiguous Questions with Retrieval-Augmented Large Language Models:https://arxiv.org/pdf/2310.14696
递归检索的典型实现,例如ToC(Tree of Clarifications),涉及递归执行RAC(Recursive Augmented Clarification)
递归构建一个澄清问题的树状结构来处理模糊问题(AQ)
-从根节点(AQ)开始,通过递归执行RAC,逐步插入子节点,每个子节点包含一个澄清问题-答案对。每次扩展,重新对当前查询进行文档重排序。
-树状结构的探索在达到最大有效节点数或最大深度时结束。默认使用广度优先搜索(BFS),以确保覆盖更广泛的解释。
构建澄清树后,ToC会收集所有有效节点并生成全面的长文本答案来解决 AQ。
(11)推理阶段 - 环形模式 - 自适应(主动)检索
随着 RAG 的进步,逐渐从被动检索转向自适应检索,也称为主动检索,这在一定程度上归功于 LLM 的强大功能。
RAG系统可以主动判断检索时机,决定何时结束整个流程并产生最终结果。
根据判断标准,又可以分为基于Prompt和基于Tuning的方法。
1、基于提示词方法
使用提示工程来控制流程以指导 LLM。
一个典型的实现示例是:前瞻式主动检索增强生成 FLARE(Forward-Looking Active Retrieval Augmented Generation):https://blog.lancedb.com/better-rag-with-active-retrieval-augmented-generation-flare-3b66646e2a9f/
论文Active Retrieval Augmented Generation:https://arxiv.org/pdf/2305.06983
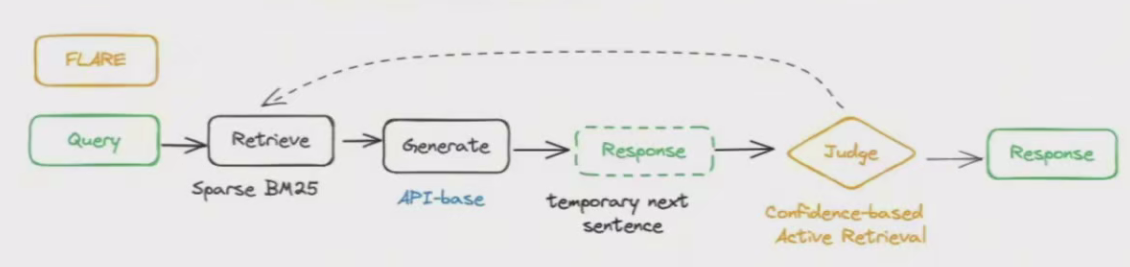
FLARE提出了两种检索查询方法:一种是基于检索指令的方法(FLARE instruct),另一种是直接使用生成句子作为查询的方法(FLARE direct)包括FLARE instruct和FLARE Direct。
FLARE 的迭代生成过程:
先迭代生成临时的下一句,将其用作查询以检索相关文档,如果这些文档包含概率较低的token,就会重新生成下一句,直到达到整体生成的结束。
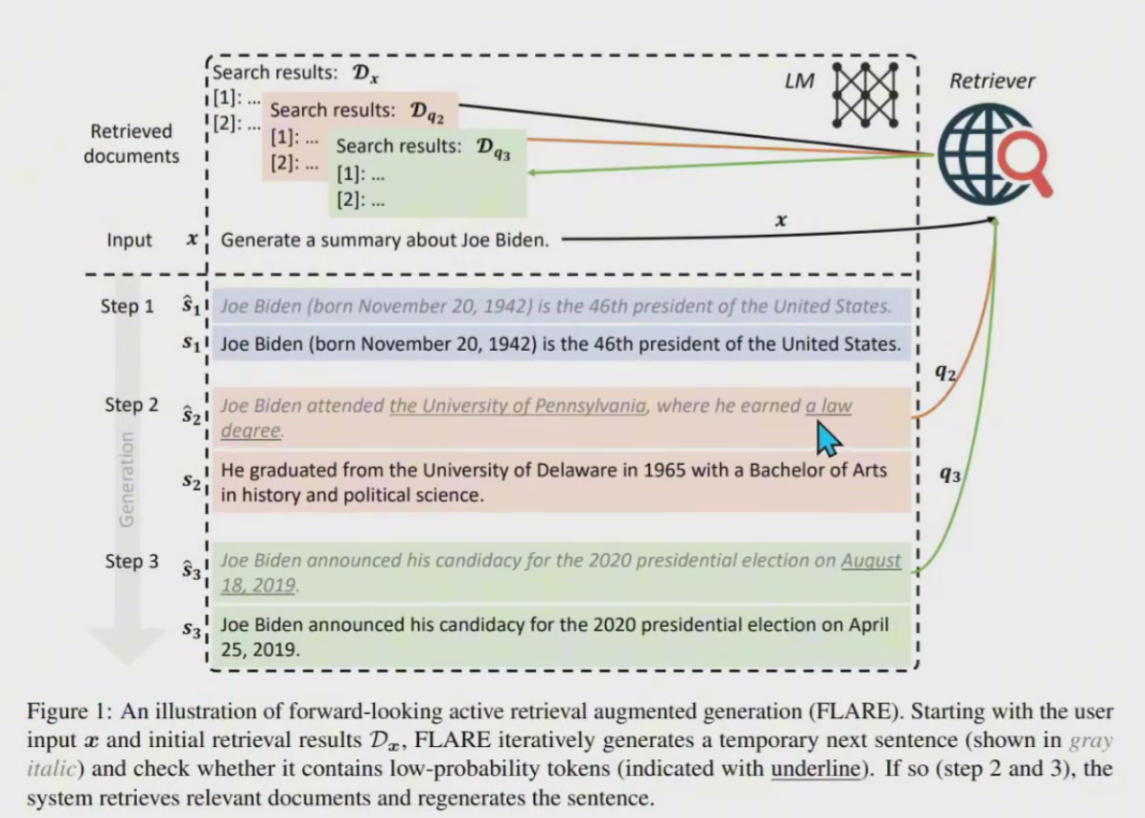
假设模型生成一个句子,但置信度较低(下划线突出显示)“宾夕法尼亚大学“和“法律学位

解决低可信度信息:FLARE Direct 采用了两种方法:
1、通过掩码进行隐式查询(以橙色突出显示):例如屏蔽之后剩下的句子’Joe Biden attended, where he earned’ ,让后通过这剩下部分去向量数据库检索。
2、通过问题生成进行明确查询(以绿色突出显示):让大语言机型生成问题,示例可能包括:"乔:拜登上过哪所大学?“和"乔:拜登获得了什么学位?”,然后使用这些问颗从数据库中提取相关数据,确保信息的准确性和相关性。
2、Tuning-base
基于Tuning的方法涉及微调 LLM 以生成特殊 token,从而触发检索或生成。此概念可以追溯到Toolformer,其中特定内容的生成有助于调用工具。在 RAG 系统中,此方法用于控制检索和生成步骡。
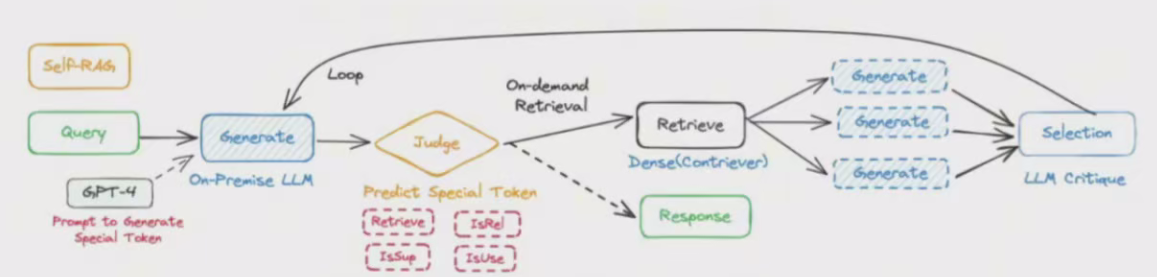
一个典型案例是 Self-RAG(SELF-RAG: LEARNING TO RETRIEVE, GENERATE, AND CRITIQUE THROUGH SELF-REFLECTION)
论文:https://arxiv.org/pdf/2310.11511
github:https://selfrag.github.io/
微调后的模型:https://huggingface.co/selfrag/selfrag_llama2_7b
SeIf-RAG的基本工作原理:
SeI-RAG通过在模型层面的微调,让大横型本身直接具备了判断按需检索与自我评判的能力,并进而通过与应用层的配合,达到提升生成准确性与质最的问题。
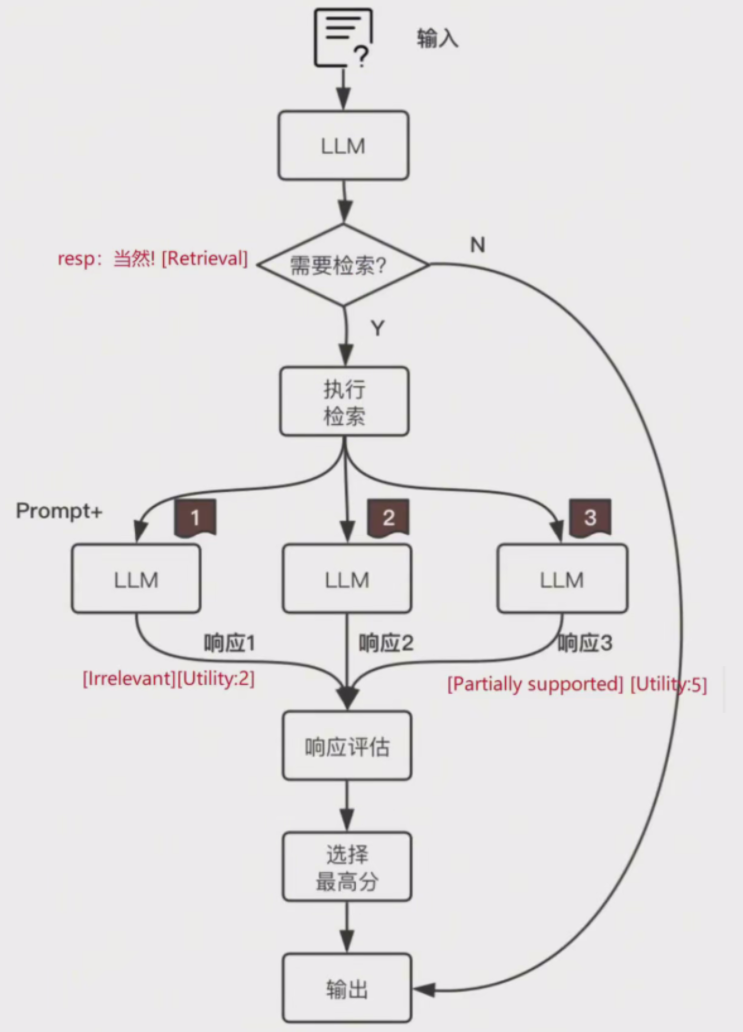
仔细看上面的流程,会发现一共会涉及到两个环节需要借助LLM进行评判:
1、是否需要知识检索以实现增强?
2、如何对多个输出的响应结果计算评分?
这里用简单的方式先来理解这四种评判指标,后续再看如何生成这些指标:
1、Retrieve:是否需要知识检索
表示LLM后续的内容生成是否需要做额外知识检索。取值:
[No Retrieval]:无需检索,LLM直接生成
[Retrieval]:需要构
[Continue to Use Evidence]:无需检索,使用之前内容
2、lsRel:知识相关性(知识 =>问题)
表示检索出来的知识是否提供了解决问题所需的信息。取值:
[Relevant]: 检索出来的知识与需要解决的问题足够相关。
[lrrelevant]: 检索出来的知识与需要解决的问题无关
3、IsSup:响应支持度(知识 =>响应)
表示生成的响应内容是否得到检索知识的足够支持。取值:
[Fully supported]:输出内容陈述被检索的知识完全支持。
[Partially supported]:输出内容陈述只有部分被检索的知识所支持。
[No support/Contradictory]:输出内容不被检索的知识所支持(即编造)
4、lsUse:响应有效性(响应 =>问题)
表示生成的响应内容对于回答/解决输入问题是否有用。取值:
[Utility:x]:按有效的程度x分成1-5分,即最高为[Utility:5]
在训练过程中,需要使用两个模型:
批判模型(critic model)C和生成模型(generator model)G。
批判模型C主要生成G所需的已经标注好的用于有监督学习任务的数据(supervision data)。
在推理过程中,只需使用模型 G,不需要批判模型C。
SeIf-RAG训练了两个模型,Critic和Generator,这两个模型都使用reflection token扩展词汇表,并使用标准的下一个token预测目标进行训练。
第1步:Critic数据创建:使用 GPT4生成Critic训练数据。
第2步:Critic训练:使用新的特殊token训练Critic。
第3步:Generator数据创建:使用Critic和 Retriever生成生成器训练数据。
第4步:Generator训练:使用新的特殊token训练Generator。
8、总结
以下对RAG架构的详细解析:
二、RAG落地
检索增强生成(Retrieval-Augmented Generation,RAG)是目前为止我们认为最经济、最有效的企业级LLM解决方案。
全量训练成本昂贵,一个7B(70亿个参数)模型已经让大部分中小企业局的没有性价比。
对于大模型可以做的事情就剩下三件:Prompt工程、微调(Fine-Tune)和RAG。
真实落地中,觉得Fine-Tune都有点奢侈,特别是数据整理是个大问题,基本上当时的微调都需要按目标数据和通用数据比1:7的比例喂进去,微调成本过高。
对于不是专职做大模型的团队来说,微调至少不能当做常规手段,尽管有时不可避免对LLM和embedding模型,rerank模型做一些微调。Prompt工程确实有效,而且很自然地成了RAG中的一环。而在我们的实践中,RAG最终成了最靠谱的解决方案。
可以选择一款开源的私有知识库项目,为RAG提供了数据更新、数据清洗,元数据抽取,文档内容提取等工作。
数据源当然最主要的还是手工维护为主,但是依然会提供一个文档库来管理自己的文档;
另外一个数据来源就是互联网,适合于对完全公开的公共网站定向fetch。
对于LLM,目前常采用的要么是本地的lama3.1-8B或gwen2-14B,要么就是在线的gwen2-72BAPI,也有少部分用gpt4的api,当然也可以多用几个模型配合,为多个不同能力专长的大模型做一个LLM选择和切换。
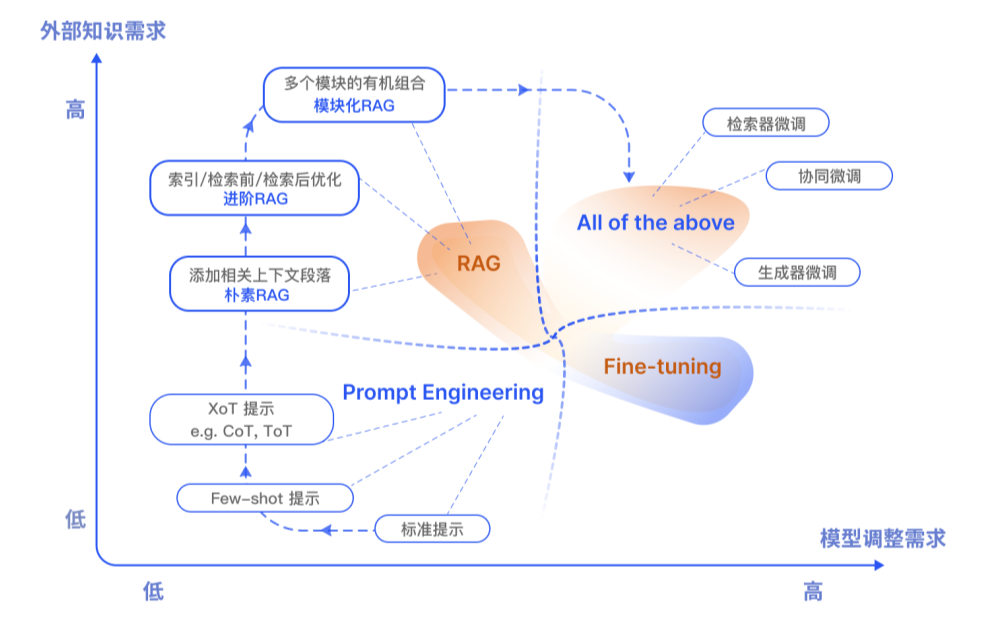
1、RAG 和微调应该如何选择?
除了 RAG,LLMs主要优化手段还包括了提示工程 (Prompt Engineering)、微调(Fine-tuning,FT)。他们都有自己独特的特点。根据对外部知识的依赖性和模型调整要求上的不同,各自有适合的场景。
| 特点对比 | 检索增强生成(RAG) | 微调(FT) |
|---|---|---|
| 知识更新 | RAG直接更新检索知识库,保持信息最新,模型无需频繁的重新训练,适合动态数据环境。 | FT存储静态数据,知识与数据更新需要重新训练。 |
| 外部知识 | RAG擅长利用外部资源,非常适合文档或其他结构化/非结构化数据库。 | 虽然FT可以对大语言模型进行微调以对齐预训练学到的外部知识,但对于频繁更改的数据源来说可能不太实用。 |
| 数据处理 | RAG对数据加工和处理的要求低 | PT依赖高质量数据集,有限的数据集可能不会产生显著性能提升。 |
| 模型风格 | RAG主要关注信息检索,擅长整合外部知识,但可能无法完全定制模型的行为或写作风格。 | FT允许根据特定的语气或术语调整大语言模型的行为、写作风格或特定领域的知识。 |
| 可解释性 | RAG通常可以追溯到特定数据源的答案,从而提供更高等级的可解释性和可溯源性。 | FT就像黑匣子,并不总是清楚模型为何会做出这样的反应,具有相对较低的可解释性。 |
| 计算资源 | RAG需要高效的检索策略和大型数据库相关技术。另外还需要保持外部数据源集成以及数据更新。 | FT需要准备和整理高质量的训练数据集、定义微调目标以及相应的计算资源。 |
| 延迟和实时要求 | RAG需要进行数据检索,可能会有更高延迟。 | 经过FT的大语言模型无需检索即可响应,延迟较低。 |
| 减少幻觉 | RAG本质上不太容易产生幻觉,因为每个回答都建立在检索到的证据上。 | FT可以通过将模型基于特定领域的训练数据来减少幻觉。但当面对不熟悉的输入时,它仍然可能产生幻觉。 |
| 道德和隐私问题 | RAG的道德和隐私问题来源于从外部数据库 | FT的道德和隐私问题则因为模型的训练数据存在敏感内容。 |
2、RAG落地实践心得
(1)RAG的技术选型
要做好AI应用对开发者的要求会非常高。
仅仅会工程技能(指的是传统的产研,包括CURD、系统框架、高并发、高可用等)是没用的。
仅仅会算法(指的是AI算法和数据分析,包括深度学习、统计分析和数学计算等)也是远远不够的。
Python是AI业界第一语言没有问题,但是和java、Go、C++等语言相比,无论是生态、实践和类型等方面,在企业级架构能力上依然偏弱。
对团队来说,既要有懂AI的,又要有懂业务的,还要有懂开发的,这儿的开发还包括python,java,前端对多种语言和技术栈。
(2)RAG底座
RAG的整体架构或者说底座,可以用java开发,而上面的组件,用的很多是Python写的,也包括一些开源组件。
中间件可以使用LangChain和Llamalndex,如果企业应用中有很多复杂的需求,需要做二次开发,也方便后期做优化和修改。
如果研发资源有限,也可以用QAnything、AnyThingLLM等私有知识库工具,有完整的前端管理工具。
(3)向量数据库
对于向量数据库,如果以前的业务有用elasticsearch,那就直接可以用elasticsearch做向量数据库。
Elasticsearch在7.2.0版本引入了dense_vector字段类型,支持存储高维向量数据,如词嵌入或文档嵌入,以进行相似度搜索等操作,而且用的BM25+KNN(实际是ANN,更精确说是HNSW)。
之前的elasticsearch使用经验,包括高并发和集群经验都可以迁移。
比如传统关系数据库PostgreSQL也通过pgvector支持了向量数据库,还有clickhouse也是有支持,看业务场景。
3、RAG知识目录
(1)Embedding
embedding模型性能,特别是适合专业领域的embedding模型在语义表达上差异较大。
(2)需要认真的Chunking
Chunking可能会是影响大部分人检索精度的第一个拦路虎,因为分块分的不好,检索是不可能好的,特别是把一个完整的句子切断了,或者句子里面有代词“TA”,怎么办?还有就是NLTK的chunking也值得借鉴。
(3)embedding模型微调
embedding模型选择应该也是大家在构建RAG应用时经常会面对的问题,甚至我们会很热衷于试用各种横型,比如Bge-large·zh、Jina、m3e等,当然还有API方式的,像通义千问、OpenAl的text-embedding-ada-002等等。
对选择的embedding模型基本满意,有一点小问题,可以通过微调来解决
(4)内容提取能力
一个非常影响最后质量的能力,就是我们需要先把文档中的内容提取出来。
最简单的当然是文本,但是我们也需要去记录一些元数据(页码、标题、副标题等)。
然后就是对表格的提取,需要对表格提取的内容设置相应的制表符,有些中文的表格是非常复杂的,提取表格是toB应用的关键能力之一。
另外就是图片上的内容提取,有时候需要采用大量的OCR。
正常像langchain和llamaindex这样的框架都支持的很好,但如果不满意得自己编码处理。
(5)本地化部署国产大模型
如果要私有化部署整套RAG系统,那么就需要去部署国产大模型。
选择国产是这些模型有专业团队在用中文数据来做训练,对于中文的理解和处理能力不会差,比如Baichuan2-138、gwen2-14B、ChatGLM3-6B等。
对于Llama3.1,当然也是很优秀的,包括现在的明星产品Mistral,但是这些模型总感觉在未来的中文能力上是会弱后与前面提到的这几家。
(6)Rerank
如果前面提到的问题你都解决了,检索结果还不尽如人意,那么就是要用高阶的方法rerank了
在成千上万份文档(chunks)中去做检索的时候,为了保证实时性,特意牺牲了很多精度,比如我们只知道全校读书最好的TOP30,但并不知道TOP3是哪几位,以至于我们随机叫三位,极大概率并不是真正的第一名、第二名、第三名。
rerank就是在第一次检索后,把TOP30再做一次打分排序,这次我们就知道谁是第一名了。
(7)RAG如何面对不同类型场景
企业的业务需求决定了我们的使用场景。比如行业专业性很强,讲出来的都是专业术语,那么可能BM25的检索会比相似度会好,这时候就需要将更大的权重放在BM25上。
另外是否允许在未召回满意的结果时(比如置信度<0.68,0.68是假设)让大模型兜底作答(很可能会胡说八道)还是说告诉客户该问题根据已知内容无法获悉。
这些都可以通过抽出一些参数来做控制。
还有比如基于图关系数据库的,比如微软开源的GraphRAG等。
4、常见业务场景
(1)对客服务
一般对外服务型的企业,每天都会面临大量的客户咨询,比如客户在使用咱们提供的系统时,会碰到各种各样的问题,这里面最常见的就是客户不了解使用方式引起的咨询(我们不能完全期望客户会去翻看几万字的使用手册或者更详细的“help”文档)。
如果你自己当过一段时间的坐班客服,就会发现90%以上的问题其实都是“老生常谈”的问题,那么,这时候如果咱们可以将几万字的使用手册、一堆帮助中心的文件与对客服务系统建立连接,不仅可以将这些非结构化知识的价值激活,还可以极大提升对客服务的能力。
目前在RAG产品上已经非常成熟,我们也有新能源汽车、政务办事、软件售后和旅游服务等行业的客户都有强烈需求与自身的各类文档形成连接,构建自己强大的对客服务能力。
(2)生产辅助
在某些知识密集型较高工业生产型企业,拥有大量行业标准,细到更换某个零件需要遵守的11个步都被明确写明。
类似这样的行业标准(SOP)文件可能多达几百份,平均每份又多达上百页,在进行日常生产或维修的时候,对于很多从业人员都是一种挑战,要么每次翻阅大最标准文件(耗费大量时间),要么凭直觉或经验(带来错误率)。
很多客户(基于RAG和LLM)之后,将这些SOP文件全部喂给Bot,然后直接问:“我现在要更换XX机器上的XXX号零件,需要怎么操作?",Bot只需几秒就会告诉你11个标准流程,而且附带原文的预览链接。
省去了自己翻阅庞杂文件的时间,也减少了生产和维修中的“拍脑袋“错误。
(3)行业知识
金融行业
帮助金融机构自动化合规流程,减少人工审核的成本和时间,提高合规准确性。通过实时监控和分析金融机构的操作和交易,确保其符合各项法律法规。
金融领域涉及到各行各业,包含了经济、产业、公司等众多方面的知识,金融知识图谱常见的实体包括:公司、产品、证券和人员等。实体间的关系包括:股权关系、任职关系、担保关系、供应商关系、竞争对手关系、生产关系、采购关系和上下游关系等。
有些实体和关系,可以自动抽取生成,如股权关系和任职关系等,均可在工商局注册登记平台得到公开信息。
法律行业
海量的法律条文、判例、合同及政策文件不仅考验着法律从业者的专业素养,也对信息处理与分析技术提出了更高要求,在法律实践中,律师往往需要花费大量时间梳理案件文档、法律条文及相关判例,以寻找案件的关键点和法律依据。
医疗行业
基于教科书、指南、共识等权威知识来源,提供丰富的西医、中医知识库,内容包括但不限于疾病知识、典型病例、症状体征、检查知识、检验知识、手术操作知识、护理操作知识、临床指南规范和专家共识、医疗相关法律法规、药品说明书、中药概述、方剂知识、经络知识、穴位知识、医案等。
5、资料知识沉淀
大型项目型公司,主要业务就是涉及智慧城市、智慧医疗、智慧交通和智慧旅游等类型的项目,这些单体项目往往项目金额巨大、周期跨度长(通常1-3年)、参与人员庞杂。
超过100GB的交接文件中有一半属于这方面的资料,包括从商机、需求调研开始的各类资料,到可研与立项的各种规范文件,再到整个项目的设计、研发与实施过程的管理文件。
如果出现核心人员变动(100%会发生),如人员离职、新人加入、人员调岗,甚至主要领导更换,都会造成项目过程管理的混乱。
比如新负责人会问:“这个规格从立项文件里面规定的5%调整到现在的8%,是谁决定的?什么原因?"
如果项目组人员变动大,多数情况下可能就问不出答案,这时候项目组人员也许只能在成千上万的项目资料中去找答案。
如果此时我们可以激活文件的价值,让我们可以与它们建立对话,那项目管理的效率和结果肯定会大大提升。
类似于上文提到过的项目管理过程,如果使用RAG系统进行管理,项目人员可以向RAG系统提问:“这个规格从立项文件里面规定的5%调整到现在的8%是谁决定的?什么原因?“。
RAG系统会先把结果告知您,如“立项文件中XX规格从5%调整为8%是由张总在2023年5月18日的项日会议中提出的,主要原因是为了给后续升级提供性能的冗余。具体内容可参见?《项目会议纪要-2023058.pdf》”,然后给出文件的引用,用户可点击打开文件查看原文。
在历史中有很多工具被发明出来改善人类的能力,比如汽车可以改善人的行动能力,眼镜可以改善人的视力,助听器可以改善人的听力,而类似于RAG这样的技术工具,与庞大却零散的非结构化文件进行连接,是可以帮助人改善记忆的。
人类一直渴望借助各类工具提升自己,我认为这就是我们渴望建立与这些文件建立对话的底层需求。
6、审批优化
审批自动化在企事业单位的应用场景很多,最简单的包括合同预评审。
法务工作中很多时间是浪费在一些初级问题的发现和纠正过程中的,比如合同的格式问题、必填项缺失、数额无法对齐、错别字、付款条件不清晰等。
这些问题均可以使用系统进行预审,让发起人通过与机器交互,改进此类问题之后,再交由法务人员处理。
可以让法务人员更加集中精力处理核心问题。
还有就是项目审批的过程,各类审批都有相应的审批制度,然后审批人员对照制度来对项目审批提交的各类文件进行审阅,过程漫长繁琐。如何通过大语言模型、RAG,以及Agent,帮助审批人员完成耗时最长的前40%工作。


















 568
568

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











