







 对Linux平台多线程相关函数的介绍,以及对线程安全,线程同步的介绍
对Linux平台多线程相关函数的介绍,以及对线程安全,线程同步的介绍
具有代表性的并发服务器端实现模型和方法:
多进程服务器:通过创建多个进程提供服务。
多路复用服务器:通过捆绑并统一管理I/O对象提供服务。
多线程服务器:通过生成与客户端等量的线程提供服务。✔
目录
1. 线程的概念
1.1 为什么要引入线程
之前学习的内容中,讲解了多进程服务器端的实现方法,明确了其缺点:
- 创建进程的过程会带来一定的开销
- 为了完成进程间的数据交换,要进行特殊的IPC技术(管道通信等)
- 每秒多次的上下文切换(进程A和进程B之间切换运行,操作系统要先将进程A的相关信息移出内存,再读入进程B的相关信息),带来的巨大开销
所以,为了保持多进程的优点,同时在一定程度上客服其缺点,就引入了线程,也被称为“轻量级进程”,其相比于进程有如下优点:
- 线程的创建和上下文切换比进程的创建和上下文切换更快。
- 线程间的通信,无需特殊技术。
1.2 线程和进程的差异
对于进程来说,每次创建新进程,都要复制旧进程的整个内存区域,包括:全局数据区、堆区、栈区。但如果创建进程只是为了获得多个代码执行流,那么就不应该复制整个进程的内存区域。如图:
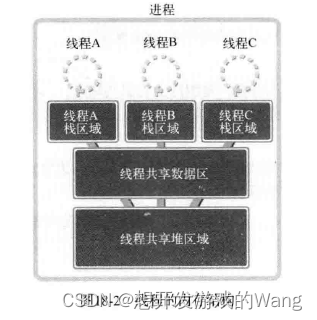
所以,线程共享数据区、堆区,而分离栈区,进程是分离整个内存区。
进程和线程可以定义为如下形式:
进程:在操作系统构成单独执行流的单位
线程:在进程中构成单独执行流的单位
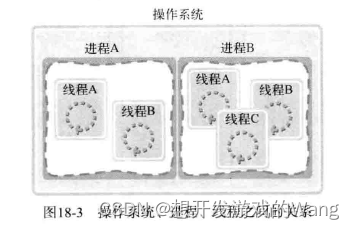
线程和进程的关系:
进程就像是一个装有线程的篮子,里面的运行注意都是线程,main函数的执行也是由线程来执行的,一般被称为主线程。如图:
2.线程函数
2.1 线程的创建
#include<pthread.h>
int pthread_create(
pthread_t* restrict thread, //保存新创建线程ID的变量地址值
const pthread_attr_t* restrict attr, //传递线程属性的参数,传递NULL,创建默认属性的线程
void* (*start_routine)(void*), //线程的main函数,单独执行流中执行的函数地址值
void* restrict arg //第三个参数调用函数时要传入的参数信息的变量地址值
);
成功返回0
失败返回其他值restrict关键字:它只可以用于限定和约束指针,并表明指针是访问一个数据对象的唯一且初始的方式.即它告诉编译器,所有修改该指针所指向内存中内容的操作都必须通过该指针来修改,而不能通过其它途径(其它变量或指针)来修改。这样做的好处是,能帮助编译器进行更好的优化代码,生成更有效率的汇编代码。
线程的代码在编译时命令行需要添加-lpthread的声明来连接线程库,如:
gcc thread.c -o thr -lpthread
传递多个参数的方法:定义一个结构体,存放参数,然后进行指针的转换。
struct thread_param { int fd; sockaddr_in addr; }; int main() { ...... thread_param params; params.fd=clientfd; params.addr=clientAddr; pthread_create(&clientthread,NULL,thread_client_handle,(void*)¶ms); } void* thread_client_handle(void* args) { thread_param params=*(thread_param*)args; int clientfd=params.fd; sockaddr_in clientAddr=params.addr; ...... }
2.1 分离线程
#include<pthread.h>
int pthread_join(
pthread_t thread, //要分离的线程ID
void** statrus //保存线程的main函数的返回值的指针变量地址值
);
成功返回0
失败返回其他值函数功能:阻塞住主线程的运行,直到这个子线程运行结束,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 891
891











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









