环境准备:
确保已经安装了Spark和PySpark,并且配置了正确的环境变量。
启动一个Spark会话(SparkSession),以便使用PySpark API。
数据加载与准备:
使用PySpark的SparkContext或SparkSession从各种数据源(如HDFS、S3、CSV文件等)加载数据。
转换数据为PySpark的DataFrame格式,以便进行后续处理。
数据清洗和预处理,包括缺失值处理、异常值检测、特征缩放等。
特征选择:
选择用于聚类的特征列。
如果需要,可以使用特征工程创建新的特征。
训练K-means模型:
导入pyspark.ml.clustering.KMeans模块。
创建一个KMeans实例,并设置聚类数量(k)、初始化模式(如"k-means||"或"random")、最大迭代次数等参数。
使用fit方法在训练数据上训练KMeans模型。
模型评估:
使用训练好的模型对训练集或测试集进行预测,获取每个样本的聚类标签。
评估聚类效果,可以使用如轮廓系数(Silhouette Coefficient)等指标来评估聚类质量。需要注意的是,PySpark的KMeans模型本身不直接提供轮廓系数的计算,可能需要手动实现或使用其他库。
可视化聚类结果(如果数据集较小且维度较低)。
结果解释与应用:
分析聚类结果,理解每个聚类的特点和意义。
将聚类结果应用于实际问题中,如客户细分、推荐系统等。
优化与调整:根据评估结果调整聚类数量(k)和其他参数,以优化聚类效果。
- DBSCAN.py
| # -*- coding: utf-8 -*-
import pandas as pd
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
# 使用matplotlib.rcParams来设置字体属性
plt.rcParams['font.sans-serif'] = ['SimHei', 'FangSong', 'YouYuan',
'Microsoft YaHei',
'Bitstream Vera Sans',
'DejaVu Sans',
'Lucid Sans Unicode',
'Arial', 'sans-serif']
plt.rcParams['axes.unicode_minus'] = False # 确保负号也能正常显示
# 加载数据
try:
df = pd.read_csv('C:\\Users\\Administrator\\Desktop\\BigData5\\data\\business.csv', encoding='gbk')
except FileNotFoundError:
print("数据文件未找到,请检查路径是否正确。")
exit()
# 检查数据是否有缺失值或异常值
print(df.isna().sum())
# 选择用于DBSCAN的特征列
X = df[['进货次数', '平均进货金额', '进货商品种类数']].values
# 数据标准化(可选,但通常对DBSCAN是有益的)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 定义DBSCAN模型
# eps是邻域的大小,min_samples是成为核心点所需的最小邻居数
dbscan = DBSCAN(eps=0.5, min_samples=5)
# 拟合模型
labels = dbscan.fit_predict(X_scaled)
# 将聚类标签添加回DataFrame
df['聚类标签'] = labels
# 移除噪声点(如果有的话,DBSCAN会将噪声点标记为-1)
df = df[df['聚类标签'] != -1]
# 查看结果
print(df[['商家ID', '聚类标签']])
# 可视化结果(仅适用于二维数据)
# 选择两个特征进行可视化,例如购物频率和平均消费金额
plt.scatter(X_scaled[labels != -1, 0], X_scaled[labels != -1, 1], c=labels[labels != -1], cmap='viridis', marker='o',
edgecolor='none', alpha=0.7)
# 可视化噪声点(如果有的话)
if -1 in labels:
plt.scatter(X_scaled[labels == -1, 0], X_scaled[labels == -1, 1], c='red', marker='x', linewidths=2)
plt.xlabel('进货次数(标准化后)')
plt.ylabel('平均进货金额(标准化后)')
plt.title('商家DBSCAN聚类结果')
plt.show() |
- GMM.py
| # -*- coding: utf-8 -*-
import pandas as pd
from sklearn.mixture import GaussianMixture
import matplotlib.pyplot as plt
import numpy as np
# 设置绘图参数
plt.rcParams['font.sans-serif'] = ['SimHei', 'FangSong', 'YouYuan', 'Microsoft YaHei', 'sans-serif']
plt.rcParams['axes.unicode_minus'] = False
# 加载数据
try:
df = pd.read_csv('C:\\Users\\Administrator\\Desktop\\BigData5\\data\\business.csv', encoding='gbk')
except FileNotFoundError:
print("数据文件未找到,请检查路径是否正确。")
exit()
# 检查数据是否有缺失值或异常值
print(df.isna().sum())
# 选择用于GMM的特征列
X = df[['进货次数', '平均进货金额', '进货商品种类数']].values
# 定义GMM模型
gmm = GaussianMixture(n_components=3)
# 拟合模型
gmm.fit(X)
# 预测每个顾客的聚类标签
labels = gmm.predict(X)
# 将聚类标签添加回DataFrame
df['聚类标签'] = labels
# 查看结果
print(df[['商家ID', '聚类标签']])
# 定义不同聚类的标记形状
markers = ['s', 'o', '^']
# 可视化结果(仅适用于二维或三维数据)
# 选择购物频率和平均消费金额进行可视化
colors = ['tab:blue', 'tab:orange', 'tab:green'] # 使用matplotlib的内置颜色
for label, color in zip(range(gmm.n_components), colors):
plt.scatter(X[labels == label, 0], X[labels == label, 1],
c=[color] * np.sum(labels == label), # 为每个聚类生成一个颜色列表
marker=markers[label % len(markers)], # 使用模运算来循环使用标记形状
edgecolor='none',
alpha=0.7,
label=f'聚类{label + 1}') # 为图例添加标签
plt.xlabel('进货频率')
plt.ylabel('平均进货金额')
plt.title('GMM聚类结果')
plt.legend() # 让matplotlib自动处理图例
plt.show() |
- K-means.py
| import pandas as pd
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
from lhx.DBSCAN import df
# 使用matplotlib.rcParams来设置字体属性
plt.rcParams['font.sans-serif'] = ['SimHei', 'FangSong', 'YouYuan',
'Microsoft YaHei',
'Bitstream Vera Sans',
'DejaVu Sans',
'Lucida Sans Unicode',
'Arial', 'sans-serif']
plt.rcParams['axes.unicode_minus'] = False # 确保负号也能正常显示
# 会员等级在聚类时不直接使用,但可以后续用来分析聚类结果
data = pd.read_csv('C:\\Users\\Administrator\\Desktop\\BigData5\\data\\business.csv', encoding='gbk')
# 选择数值型特征进行聚类
X = df[['进货次数', '平均进货金额', '进货商品种类数']].values
# 设定聚类的数量,这里假设为3个簇
n_clusters = 3
# 执行K-means聚类
kmeans = KMeans(n_clusters=n_clusters, random_state=0).fit(X)
# 获取聚类标签
labels = kmeans.labels_
# 将聚类标签添加到原始数据集中
data['聚类标签'] = labels
# 输出结果(可选)
print(data[['商家ID', '聚类标签']])
# 可视化聚类结果(仅适用于二维或三维数据)
# 由于我们有三个特征,我们可以选择其中两个进行可视化
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis', marker='o')
# 画出聚类中心
centers = kmeans.cluster_centers_
plt.scatter(centers[:, 0], centers[:, 1], c='black', s=200, alpha=0.5);
# 显示图形
plt.xlabel('进货频率')
plt.ylabel('平均进货金额')
plt.title('K-means聚类结果')
plt.show() |
实验的结果如下
1.商家DBSCAN聚类结果
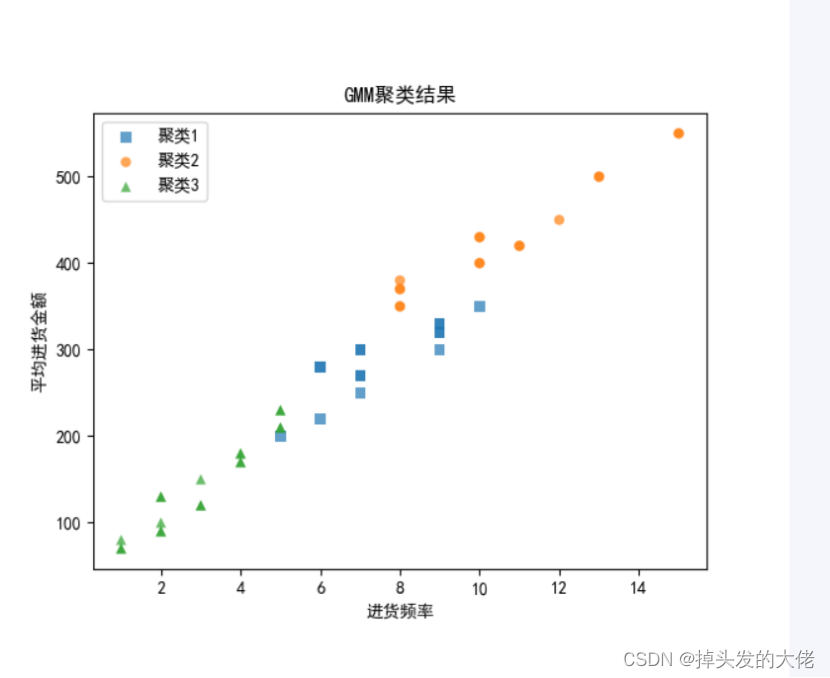
2.GMM聚类结

3.商家DBSCAN聚类结果
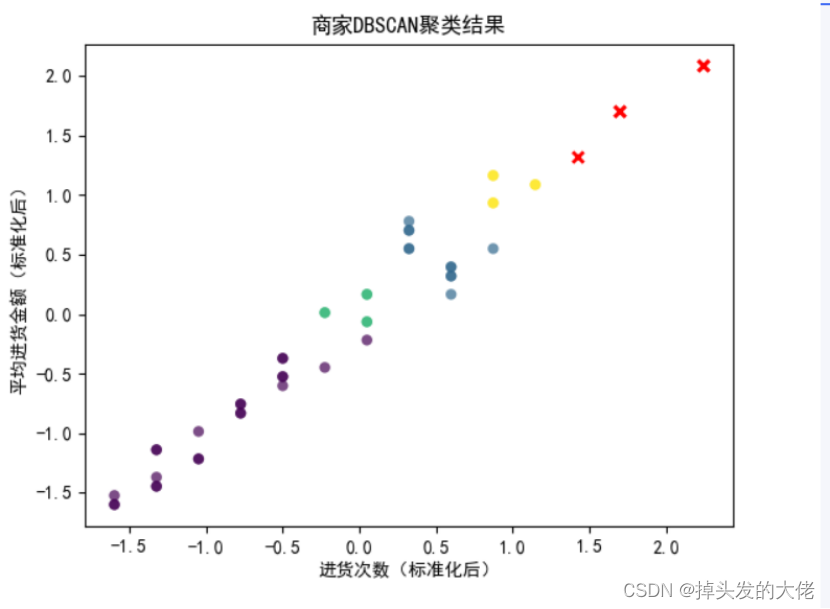






















 9719
9719











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









