







卷积神经网络
人工神经网络(Artificial Neural Network,即ANN),是从信息处理角度对人脑神经元网络进行抽象,建立某种简单模型,按不同的连接方式组成不同的网络。神经网络由大量的神经元相互连接而成,每个神经元接受线性组合的输入后,最开始只是简单的线性加权,后来给每个神经元加上了非线性的激活函数,从而进行非线性变换后输出。每两个神经元之间的连接代表加权值,称之为权重(weight)。不同的权重和激活函数,则会导致神经网络不同的输出。
卷积神经网络(ConvolutionalNeural Network,CNN)是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,对于大型图像处理有出色表现。由于卷积神经网络的良好特性,除了对图像进行处理和分类,它在音频、视频以及文本等多种形式的信息识别和处理上都有非常不错的效果。
本次主要是介绍两个方面:一是CNN的层次结构,本文详细介绍了CNN的各个层级及其作用,另一个是基于字符级卷积神经网络的文本分类,以及它与传统分类算法的对比。
一、CNN的层级结构
1.1 卷积层
对图像(不同的数据窗口数据)和滤波矩阵(一组固定的权重:因为每个神经元的多个权重固定,所以又可以看做一个恒定的滤波器filter)做内积(逐个元素相乘再求和)的操作就是所谓的『卷积』操作,也是卷积神经网络的名字来源。
CNN有两种减少参数的方法:
1) 局部感知:一般认为人对外界的认知是从局部到全局的,而图像的空间联系也是局部的像素联系较为紧密,而距离较远的像素相关性则较弱。因而,每个神经元其实没有必要对全局图像进行感知,只需要对局部进行感知,然后在更高层将局部的信息综合起来就得到了全局的信息。网络部分连通的思想,也是受启发于生物学里面的视觉系统结构。视觉皮层的神经元就是局部接受信息的(即这些神经元只响应某些特定区域的刺激)。
2) 参数共享:也叫权重共享,由于图像的一部分的统计特性与其他部分是一样的,这也意味着我们在这一部分学习的特征也能用在另一部分上,所以对于这个图像上的所有位置,我们都能使用同样的学习特征。与此同时,数据窗口滑动,导致输入在变化,但中间滤波器的权重(即每个神经元连接数据窗口的权重)是固定不变的,这个权重不变即所谓的CNN中的参数(权重)共享机制。
举例来说,当输入一个图像,那么通过不同的滤波器就可以得到不同的输出数据,比如颜色深浅以及轮廓等等。相当于如果想提取图像的不同特征,则用不同的滤波器filter,提取想要的关于图像的特定信息。
1.2 激励层
激励层的主要作用是模拟人脑神经元的突触,形成激励,然后传到下一层。如果不用激励函数(其实相当于激励函数是f(x) = x),在这种情况下你每一层输出都是上层输入的线性函数,很容易验证,无论你神经网络有多少层,输出都是输入的线性组合,与没有隐藏层效果相当。正因为上面的原因,我们决定引入非线性函数作为激励函数,这样深层神经网络就有意义了(不再是输入的线性组合,可以逼近任意函数)。最早的想法是sigmoid函数或者tanh函数,输出有界,很容易充当下一层输入。
但是从数学上来看,非线性的Sigmoid函数对中央区的信号增益较大,对两侧区的信号增益小,由于两端饱和,在传播过程中容易丢弃信息。而relu因为其分段线性性质,导致其前传,后传,求导都是分段线性,所以相比起来的计算量更小,也能缓解过拟合。
1.3 池化层
池化层夹在连续的卷积层中间,用于压缩数据和参数的量、减小过拟合,基于的理论是平移不变性。最常见的池化操作为平均池化mean pooling和最大池化max pooling:
平均池化:计算图像区域的平均值作为该区域池化后的值。
最大池化:选图像区域的最大值作为该区域池化后的值。
1.4 分类器
Softmax回归模型,该模型是logistic回归模型在多分类问题上的推广,在多分类问题中,类标签 y可以取两个以上的值。 Softmax回归模型对于诸如MNIST手写数字分类等问题是很有用的,该问题的目的是辨识10个不同的单个数字。
Softmax回归模型是logistic回归模型在多分类问题上的扩展(logistic回归解决的是二分类问题)。对于训练集{ (x(1), y(1)), ……, (x(m), y(m))},有。y(i) ∈{1,2,…,k}对于给定的测试输入x,我们相拥假设函数针对每一个类别j估算出概率值p(y=j|x)。也就是说,我们估计得每一种分类结果出现的概率。
Softmax 回归假设函数:
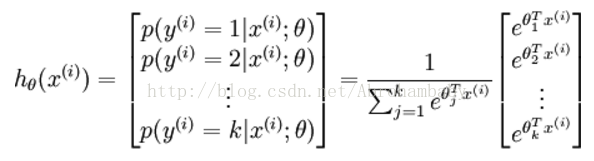
Softmax 回归代价函数:

有关Softmax回归具体可参考UFLDL。
二、基于字符级卷积神经网络的文本分类
2.1 字符级卷积神经网络
字符级卷积神经网络(character-levelconvolu-tional networks),是先对下列这些字符进行编码(如one-hot 编码),然后当输入文本时先按照这种字母表对应的编码的方式进行量化,然后输入构建好的神经网络中即可实现文本分类。
a b c d e f g h Ij k l m n o p q r s t u v w x y z 0 1 2 3 4 5 6 7 8 9
- , ; . ! ? : ’”/\ | _ @ # $ % ˆ & * ˜‘ + - = < >( ) [ ] { }
2.2 传统分类方法
1)TF-IDF(termfrequency–inverse document frequency):是一种用于资讯检索与资讯探勘的常用加权技术。TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随著它在文件中出现的次数成正比增加,但同时会随著它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜寻引擎应用,作为文件与用户查询之间相关程度的度量或评级。除了TF-IDF以外,因特网上的搜寻引擎还会使用基于连结分析的评级方法,以确定文件在搜寻结果中出现的顺序。
原理:在一份给定的文件里,词频 (term frequency, TF) 指的是某一个给定的词语在该文件中出现的次数。这个数字通常会被正规化,以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词频,而不管该词语重要与否。)逆向文件频率 (inverse document frequency, IDF) 是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到。
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向於过滤掉常见的词语,保留重要的词语。
2) Bag of words:也叫做“词袋”,在信息检索中,Bag of words model假定对于一个文本,忽略其词序和语法,句法,将其仅仅看做是一个词集合,或者说是词的一个组合,文本中每个词的出现都是独立的,不依赖于其他词是否出现,或者说当这篇文章的作者在任意一个位置选择一个词汇都不受前面句子的影响而独立选择的。
这种假设虽然对自然语言进行了简化,便于模型化,但是其假定在有些情况下是不合理的,例如在新闻个性化推荐中,采用Bag of words的模型就会出现问题。例如用户甲对“南京醉酒驾车事故”这个短语很感兴趣,采用bag of words忽略了顺序和句法,则认为用户甲对“南京”、“醉酒”、“驾车”和“事故”感兴趣,因此可能推荐出和“南京”,“公交车”,“事故”相关的新闻,这显然是不合理的。
解决的方法可以采用SCPCD的方法抽取出整个短语,或者采用高阶(2阶以上)统计语言模型,例如bigram,trigram来将词序保留下来,相当于bag of bigram和bag of trigram,这样能在一定程度上解决这种问题。
简言之,bagof words模型是否适用需要根据实际情况来确定。对于那些不可以忽视词序,语法和句法的场合均不能采用bagof words的方法。
3)Bag-of-means on word embedding 就是在Word2vec的基础上通过k-means来从训练集中的每个子集进行学习。
其中wordembedding的意思是:给出一个文档,文档就是一个单词序列比如 “A B A C B F G”, 希望对文档中每个不同的单词都得到一个对应的向量(往往是低维向量)表示。比如,对于这样的“A B A C B F G”的一个序列,也许我们最后能得到:A对应的向量为[0.1 0.6 -0.5],B对应的向量为[-0.2 0.9 0.7] (此处的数值只用于示意)。之所以希望把每个单词变成一个向量,目的还是为了方便计算,比如“求单词A的同义词”,就可以通过“求与单词A在cos距离下最相似的向量”来做到。Word2vec就是一种word embedding方式。
本文简要的介绍了CNN的层次结构,有关实例以及各种文本分类算法的对比详见PPT.
编者:HYB















 436
436

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









