







欢迎查看我的公众号原文
细嗦Transformer(二): Attention及FFN等细节部分解读和代码实现
也欢迎关注我的公众号:

文章目录
Q1: **Transformer为何使用多头注意力机制?**
使用Multi-Head,主要是为了:
① 捕捉不同的特征,每个头可以学习到输入序列不同方面的特征或模式。
② **增强模型的表达能力,**多个头的并行计算可以丰富模型的表达能力,使其能够关注到输入的不同方面。
多头注意力机制计算过程中,每个头都有自己的权重矩阵,最后再将每个头的输出拼接起来,进行线性变换,从而使模型能够综合利用多个头的信息。
Attention注意力机制
对注意力机制的理解,简单来讲就是,一句话中的一个词,只与句中的部分词有关系,而不是与每个词都有关系,attention就是衡量这种关系程度的一种方式。如下图所示:

Attention函数是将一个query和一组键值对(key-value)映射到输出output,这里的都是向量。Output输出是值Values的加权和。
Scaled Dot-Product Attention
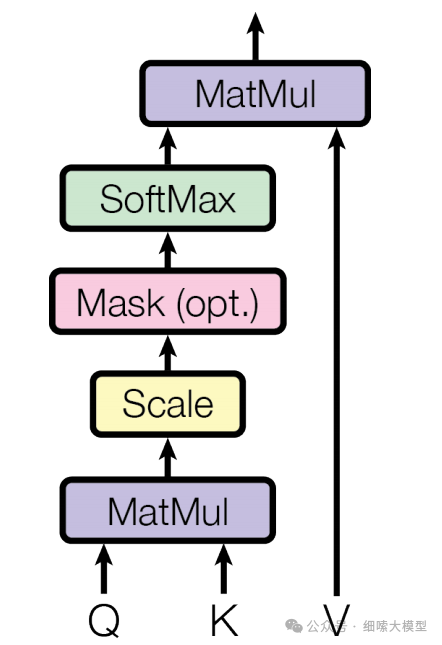
论文中将注意力称为Scaled Dot-Product Attention,也就是缩放的点积注意力。这个注意力的计算方式为:公式的输入包含维度为的和,以及维度为的,然后将一个与其他全部进行点积运算,每次的计算结果除于,经过一次运算后再与进行点积运算。对每一个都需要进行同样的操作。
计算公式为: A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q, K, V) = softmax(\frac {QK^T}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dkQKT)V
熟记这个公式
Softmax计算公式为: s o f t m a x ( x ) = e x i ∑ i e x i softmax(x)=\frac{e^{x_i}}{\sum_ie^{x_i}} softmax(x)=∑iexiexi,将值压缩到 [ 0 , 1 ] [0,1] [0,1]之间。
Q2: 为什么要除以 ?
- 论文中有说,当较大时,可能会变得非常大,导致函数的梯度变得非常小,进而导致梯度消失。
- 计算结果是一个一维向量,每个元素表示单个token的值,当过大时,可能导致某一个元素的非常大,进而在经过计算后,部分值趋近于0,部分值趋近于1,导致模型难以学习到有效注意力。
接下来对这个过程进行图解,主要参考:The Illustrated Transformer
QKV计算方式
上文所说的和和的计算方式如下图所示。这里以输入“Thinking Machines”为例
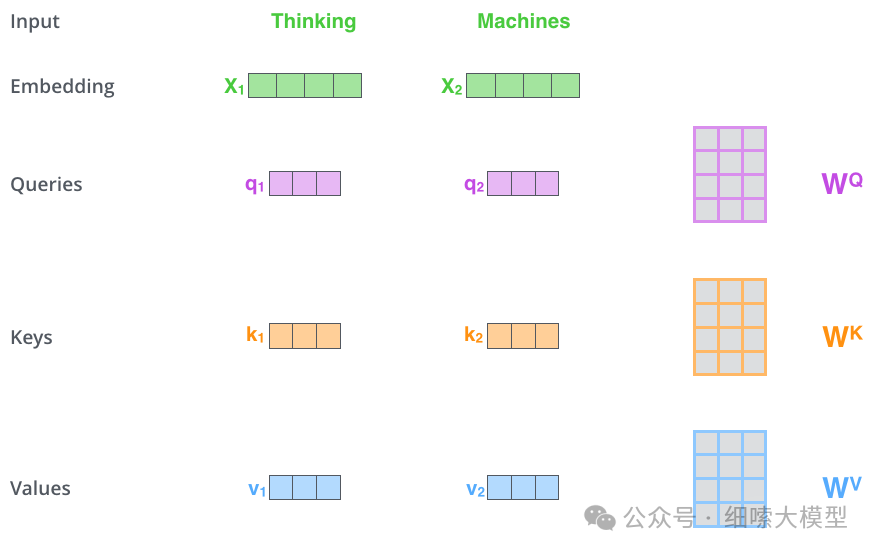
注意:
在Embedding的时候,一个token是embbeding成维的向量,如果输入的token长度为4096,一个token embedding成,那么输入层Embedding之后的维度为维,是一个矩阵。如果batch为4,那么输入层的Embedding结果就为。还需要注意图中的"Thinking Machines"是为了简单起见,当成一个token来处理,实际上这里还有一步tokenize的过程。
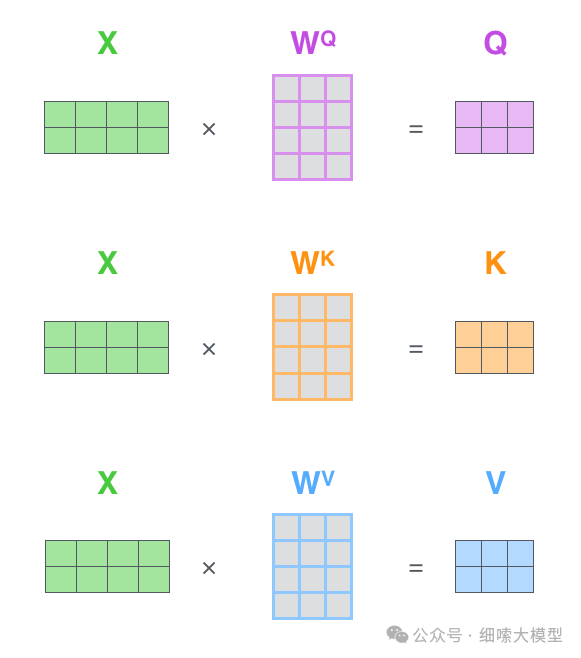
如上图所示,输入向量,经过与矩阵相乘,得到,,的计算过程一样,这里的是模型通过训练学习到的矩阵参数。
有了之后,其中的计算过程如下图所示。

q 1 q_1 q1与 k 1 , k 2 k_1,k_2 k1,k2分别进行点击运算,然后除于 ( d k ) \sqrt{(d_k)} (dk),这里 d k d_k dk就是 k e y key key的维度,论文中的维度为64, ( d k ) = 8 \sqrt{(d_k)}=8 (dk)=8,所以图中除的是8。除以 ( d k ) \sqrt{(d_k)} (dk) 可以使梯度更加稳定。然后再经过一个 S o f t m a x Softmax Softmax得到向量[0.88,0.12],最后于 v a l u e ( v 1 ) value(v_1) value(v1)进行点积运算,得到 q 1 q_1 q1的输出 z 1 z_1 z1。
因此,Self-Attention层的公式就表示为:
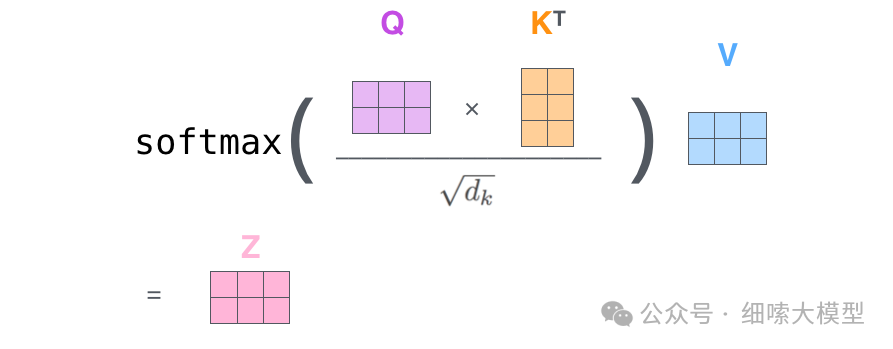
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 504
504

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









