









 本文介绍了一种利用深度学习的3D Dense-Net在头颈部癌放射治疗中进行GTV分割的方法,通过融合PET和CT图像,克服了复杂解剖结构和低对比度的挑战。与单模态和3DU-Net对比实验显示,多模态Dense-Net在Dice系数和一致性上有显著优势,参数更少,为治疗计划提供自动、快速和准确的解决方案。
本文介绍了一种利用深度学习的3D Dense-Net在头颈部癌放射治疗中进行GTV分割的方法,通过融合PET和CT图像,克服了复杂解剖结构和低对比度的挑战。与单模态和3DU-Net对比实验显示,多模态Dense-Net在Dice系数和一致性上有显著优势,参数更少,为治疗计划提供自动、快速和准确的解决方案。
Gross Tumor Volume Segmentation for Head and Neck Cancer Radiotherapy using Deep Dense Multi-modality Network

总结:PET/CT图像,多模态,3D Dense-Net,对比实验:3D U-Net 单模态Dense-Net 没有消融实验
Abstract
在放射治疗中,大体肿瘤体积(GTV)的准确描绘是制定治疗计划的关键。然而,头颈癌(HNC)由于头部各器官形态复杂,靶区背景对比度低,以及常规计划CT图像存在潜在伪影等特点,给头颈部肿瘤的治疗带来了挑战。因此,在解剖图像上手工描绘GTV是非常耗时的,并且受到观察者之间的可变性的影响,这导致了规划的不确定性。随着PET/CT成像在肿瘤学中的广泛应用,可以利用补充的功能和解剖信息来勾画肿瘤轮廓,为放射治疗规划带来显著的优势。在这项研究中,我们利用多模态PET和CT图像的优势,提出了一种基于深度学习的HNC自动GTV分割框架。该分割框架的核心是基于密集连接的三维卷积,能够更好地传播信息,充分利用从多模态输入图像中提取的特征。我们在包括250名HNC患者的数据集上评估了我们提出的框架。每位患者在放疗前接受计划性CT和PET/CT成像。辐射肿瘤学家手动描绘的GTV轮廓被用作本研究的基础事实。为了进一步研究我们提出的Dense-Net框架的优势,我们还与目前分割任务中最先进的3D U-Net框架进行了比较。同时,对每一帧进行了单模态输入(PET或CT图像)和多模态输入(PET/CT)的性能比较。计算Dice系数、平均表面距离(MSD)、94%Hausdorff距离(HD95)和质心位移进行定量评价。基于五次交叉验证的结果,我们提出的多模态Dense-Net(Dice 0.73)表现出比我们比较的网络(Dice 0.71)更好的性能。此外,与3D U-Net相比,所提出的Dense-Net结构的可训练参数更少,从而降低了预测的可变性。综上所述,我们提出的多模态Dense-Net网络能够利用多模态图像对HNC进行令人满意的GTV分割,并且比传统方法具有更好的性能。我们提出的方法为GTV分割提供了一种自动、快速和一致的解决方案,并显示出广泛应用于各种癌症的放射治疗规划的潜力。
Introduction
头颈部癌(HNC)是世界上最常见的癌症类型之一。它每年在美国造成约5万例新报告病例和约1万例死亡(Siegel等人,2016年)。除了手术和化疗,高精度放射治疗(RT)是最有效的治疗方法之一,与其他方法相比,在不同部位产生更好的功能结果(Marta等人,2014年)。准确勾画大体肿瘤体积(GTV)是图像引导下鼻咽癌放射治疗计划的关键步骤。不正确的靶点定义可能导致剂量传递计划受损,要么对健康组织造成不必要的损害,要么在肿瘤边界附近治疗不足(Riegel等人,2006年)。对于HNC来说,情况尤其严峻,因为目标被关键的解剖结构包围。在临床实践中,GTV的描述通常由肿瘤学家用有限的自动工具手动进行,这容易出错和耗时,特别是对于大的和不规则的GTV(Jeanneret-Sozzi等人,2006年)。此外,手工描绘是主观的,重现性低,并且引入了很高的观察者间可变性。先前的研究(Riegel等人,2006年;Harari等人,2010年)表明,由于操作者的经验和知识,多观察者定义的靶体积有很大差异。因此,发展一种准确、高效、可重复性的GTV勾画方法对HNC的放射治疗至关重要。
在过去的几十年里,已经开发了各种基于手工特征或机器学习的半自动或自动分割方法,并在HNC GTV描述上进行了测试。基于图形的分割,包括Graph Cut(Song等人,2013;Beichel等人,2016)、马尔可夫随机场(MRF)(Zeng等人,2013;Yang等人,2015)和随机游走(Stefano等人,2017)显示出有希望的结果,特别是在PET上。
然而,由于图像之间潜在的相互矛盾/冲突的要求,很难为基于图的方法制定一个客观、稳健和直观的代价函数。最近,基于机器学习的分割方法,如支持向量机(Den等人,2017)、决策树(Berthon等人,2017)和k-近邻(KNN)(Yu等人,2009;Comelli等人,2018),被采用在许多头部和颈部分割研究中。这些分类器通过在没有任何形状约束的情况下从邻域中提取梯度或纹理特征来为每个体素做出判决。然而,这些方法的准确性是有限的,它们不能有效地转化到临床上。因此,在常规放射图像上自动勾画GTV仍然是一项非常具有挑战性的任务。
受计算机视觉任务中基于深度学习的分割最近取得的成就以及将深度学习转化为医学图像分析的成功(Havaei等人,2017年)的启发,越来越多的研究小组将重点放在用于所有类型癌症的放射治疗计划的GTV分割上。然而,针对HNC的GTV自动分割有一些特殊的挑战。首先,由于头部和颈部的关键解剖结构掩盖了病变的大小、形状和位置的不规则性,使得病变的形态更加复杂。为了克服第一个挑战,基于深度学习的分割算法能够自动提取区分特征,在处理复杂任务时显示出固有的优势。最近使用基于2D CNN(Huang等人,2018)或3D CNN(Guo等人,2019a)的算法的研究表明了深度学习在HNC分割中的巨大潜力。然而,2D CNN忽略了体积数据中的空间信息,而在肿瘤学中,放射科医生通常参考沿z轴的许多相邻切片来描绘GTV。3D CNN可以聚合所有三个维度的信息,以实现更好的预测。但其繁重的计算负担和存储需求限制了其在大规模数据集上的应用。考虑到临床实际,我们提出了一种基于三维卷积的密集连接方法(Dense-Net)来解决这些问题。其次,由于CT图像中软组织对比度不足,相当一部分HNC病变的GTV边界模糊。幸运的是,除了传统的计划CT之外,PET/CT在癌症诊断和治疗计划中变得流行,并带来多模态图像来描述肿瘤行为。众所周知,PET提供了低空间分辨率的定量代谢信息,而CT提供了高分辨率的解剖细节,可以更好地描述病变的特征(Bagci等人,2013年)。一些肿瘤分割研究已经证明,集成的多模式成像可以为肺癌和软组织肉瘤带来更好的性能(Song等人,2013;Guo等人,2018,2019b)。然而,多模态图像在HNC分割任务中的优势还没有得到研究。因此,如何利用多种模态的潜在能力进行HNC分割是一个亟待解决的问题。随着可用多模态医学图像数据量的不断增长,迫切需要开发一种基于深度学习的自动分割算法用于HNC治疗规划,以解决上述挑战。在这项工作中,我们提出了一种基于多模态图像的3D卷积密集网络用于HNC GTV分割,具有以下几个创新点和优点:1)扩展了典型的网络结构,加入了3D卷积,提取了更多的切片间特征用于HNC分割。2)采用密集连接方案,解决了三维卷积的计算量大、梯度消失、过拟合等问题,提高了预测性能,以较少的参数实现了更深层次、更高效的网络。3)网络同时提供PET和CT图像,用于GTV勾画。由于不同的模式提供了互补的生化/解剖学信息,因此可以进一步提高分割的准确性。==据我们所知,这是第一次将3D卷积和密集连接相结合来研究自动分割在多模式成像中用于HNC放射治疗的情况。==基于实验结果,我们提出的多模态Dense-Net显示出比传统方法更好的性能,可以为放射治疗计划提供自动,快速和一致的解决方案。
Material and method
在这项工作中,我们提出了一种基于三维卷积和密集连接的分割框架,该框架使用来自HNC患者的多模态PET/CT图像。这项工作的总体流程图如图1所示。首先,在预处理步骤中,将计划CT与预处理PET/CT图像配准,并为两种图像模式配准计划CT上手动勾画的GTV轮廓。归一化和裁剪后的PET和CT图像随后被送入网络。其次,利用三维卷积的优势,实现密集连接,以改善信息流,降低网络参数,更好地利用提取的特征。为了验证该方法的有效性,将所提出的多模态Dense-Net与单模态Dense-Net和3D U-Net进行了比较。最后,通过Dice系数、平均表面距离、Hausdorff Distance95%和质心位移来评价不同网络的性能。图1中概述的每个模块和步骤的详细信息在以下小节中说明。
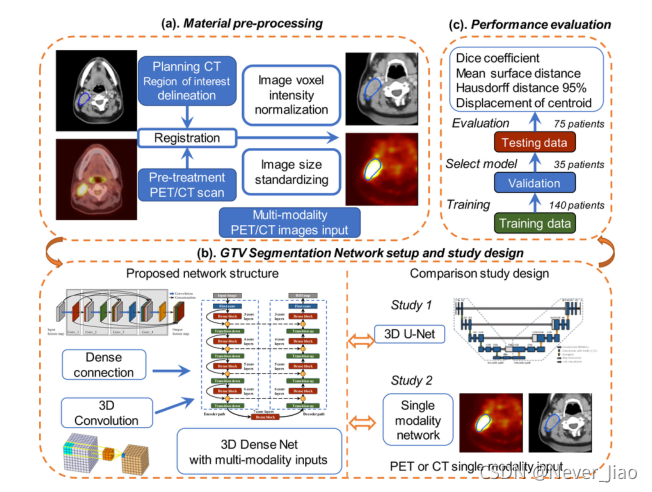
图1. 本研究的流程图:(a)数据预处理;(b)提出密集连接的网络,并进行单通道输入和3DU-Net的对比研究©性能评估。
Materials and pre-processing
实验中使用了来自癌症成像档案馆(TCIA)的HNC的数据集(Martin等人,2017年)(Clark等人,2013年)。它包含魁北克四个不同机构的18F-FDG-PET/CT和放射治疗计划CT,这些机构的头颈部鳞状细胞癌(HNSCC)经组织学证实。患者特征如补充表A1所示。所有患者在图像采集后都接受了有治疗意图的放射治疗。所有患者均在放疗前15天(范围:6-80)进行18F-FDG-PET/CT扫描。PET的中位总注射剂量为5.0MBq。CT图像是在120kVp的X射线管电压下采集的。临床特征的中位随访时间为1309(245~3402天)。
为了同时利用CT的解剖细节和PET的代谢信息,对图像进行以下处理。如图2所示,放射肿瘤学家在放疗计划CT图像上手动绘制GTV等值线。预处理18F-FDGPET/CT通过使用软件MIM®(MIM软件公司,克利夫兰,俄亥俄州)通过自动变形配准与计划CT配准(Piper,2007)。最初在计划CT上描绘的轮廓然后传播到18F-FDG-PET/CT图像。GTV轮廓(包括GTV初级和GTV淋巴结)被用作分割任务的ground truth。由于部分受试者信息缺失,250例患者同时接受了治疗前PET/CT和放射治疗计划CT的原始数据集在本研究中是合格的。
为了保持对象间的一致性,所有PET和CT图像都被线性插值到相同的分辨率,像素大小为1×1×2.5 mm3。针对不同模式间强度差异大的特点,采用Hounsfield (HU)窗口[−2 0 0,2 0 0]将CT图像的像素强度归一化为0~1,采用标准化摄取值(SUV)窗口[0,10]将PET图像强度归一化到相同的范围。考虑到GPU内存限制并移除边界黑色区域,通过手动选择中心像素(如图2(c,f)所示),将输入的3D-PET/CT图像裁剪为包含GTV注释的128×128×48像素体积。所有这些步骤都在MA TLAB(2013 Mathworks,Inc.)中执行。

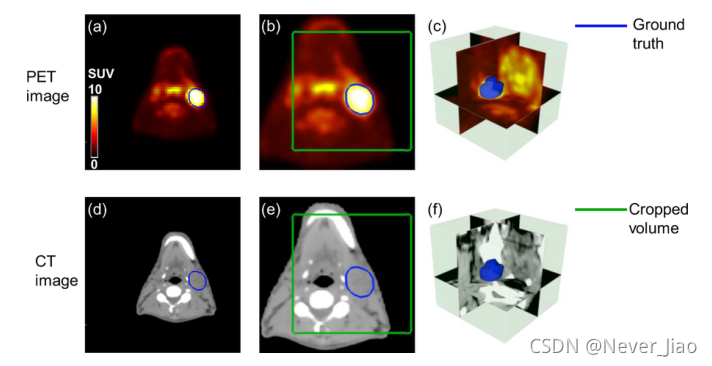
图2.输入PET和CT图像的虚幻示例(蓝色轮廓:手动勾画GTV;绿色方框:用于分割的裁剪体积(怎么定位这个位置呢?))。(a)配准的原始PET图像(b)重采样的PET图像©裁剪的PET图像的3D可视化(d)计划CT图像(e)重采样的CT图像(f)裁剪的CT图像的3D可视化。
Proposed network
细胞神经网络是一种有效的图像分析工具,已被广泛应用于语义分割,并取得了显著的效果。以往的研究(Szegedy等人,2015年)已经表明,网络深度是深度学习架构的一个关键原则。然而,三维卷积网络计算量大,内存需求大,限制了网络的深度。残差网络(他等人,2016)在网络内引入了跳跃连接,从而实现了更深层次的网络。在这项工作中,我们实现了密集连接,并提出了一个3D Dense-Net用于语义分割,灵感来自于原始的Dense-Net(Huang等人,2017年)。该网络由密集块和向上/向下过渡模块组成。密集连接的详细信息如下所示:
Xℓ表示为第ℓ层的输出。在传统的CNN结构中,该向量通常通过应用来自前一层的输出Xℓ-1的非线性变换Hℓ(X)来获得,

其中Hℓ(X)是运算的组合,包括卷积、池化、批归一化(BN)和校正线性单元(ReLU)。残差网络将H-ℓ(X)与上一层特征图相结合,以改善网络内部的信息流动,
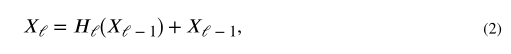
然而,Hℓ和特征映射通过求和组合,这可能阻碍信息传播。进一步推进残余连接的想法,密集连接引入了更极端的连接模式,通过跳跃连接将层链接到其所有后续层。在这个方案中,Xℓ被定义为:
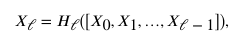
其中[…]是指连接操作。这种模式使得体系结构中的每一层都能接收来自其他层的信息,这可以缓解消失梯度问题,加强特征传播,鼓励特征重用,并大大减少可训练参数的数量。每一层上的输出特征图的大小通常被设置为较小的值,因为它通过密集连接传播。
这种特征重用的特性对于医学图像分析任务非常有吸引力,在这些任务中,很难用有限的训练数据来训练大型网络。在我们提出的网络中,3D卷积层被用来利用来自相邻切片的上下文信息。为提高计算效率,将卷积核设置为3×3×3。我们最终提出的网络结构是以(Jégou等人,2017年)为基础的,包含密集块以及向下过渡和向上过渡模块。图3显示了具有4个卷积层的致密块。如图3所示,左边的灰色立方体表示原始特征地图,卷积后的输出表示为彩色立方体。来自第一层的输入和输出特征图被整合在一起,并被设置为第二卷积层的输入。这个过程被重复几次,以构建整个密集块。最后,将所有4层的特征地图拼接在一起,作为密集块输出。
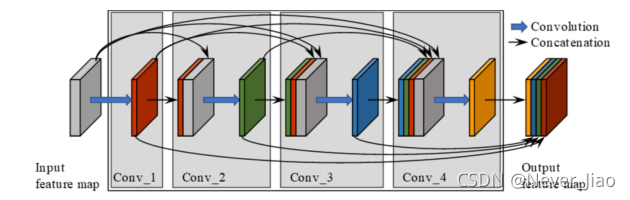
图3.具有4个卷积层的密集块架构。蓝色箭头表示卷积,黑色箭头表示要素地图之间的密集连接。
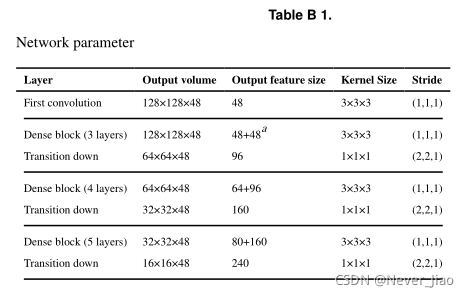
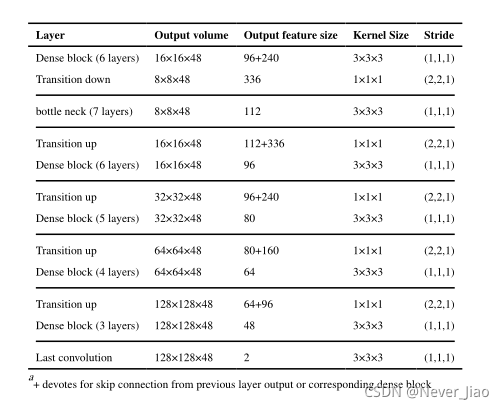
为了充分利用特征地图的空间信息,我们还引入了向下过渡和向上过渡模块,这些模块由步长为2的卷积或反卷积实现。图4显示了最终构建的网络结构。它由提取上下文特征的编码器路径和恢复图像细节的解码器路径组成。在编码器路径中,我们堆叠了四个向下过渡模块,以降低空间分辨率和扩大感受野。在解码器路径中,图像分辨率由转置模块恢复,得到精细化的语义分割图。我们的网络体系结构包含9个密集块、4个向下过渡模块和4个向上过渡模块。对于每个密集块,它由特征生长参数k=16的ℓ卷积层组成。最后一层是1×1×1卷积,然后是Sigmoid激活函数,二值化阈值固定为0.5,以生成像素级的概率图。补充表B1汇总了每个模块中使用的网络参数的详细信息。
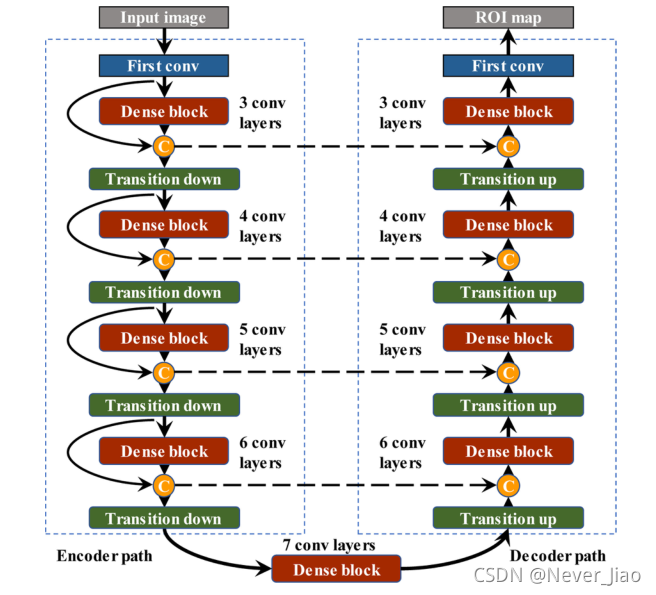
图4. 提出的网络结构包括9个密集块、4个向下过渡模块和4个向上过渡模块。
Comparison methods
为了考察所提出的集成多模态分割网络的有效性,我们首先将其与以单模态图像(单独的PET或CT图像)作为输入的单模态Dense-Net进行了比较。此外,还将所建议的网络与3D U-Net进行了比较,3D U-Net是分割任务的最先进技术(圣伊塞克等人,2016年)。3D U-net是一种经典的、应用广泛的语义分割体系结构。它由用于提取特征的编码器路径和用于恢复图像细节的解码器路径组成。比较研究中使用的3D U-Net的详细信息如附录C所示。对于3D U-Net的编码器路径中的每个模块,都有两个3×3×3的3D卷积层。在每个模块之后,特征大小增加一倍。U-Net中特征规模的指数增长阻碍了它在更深层次网络中的扩展,因为当U-Net变得更深时,可训练参数的数量变得太大。
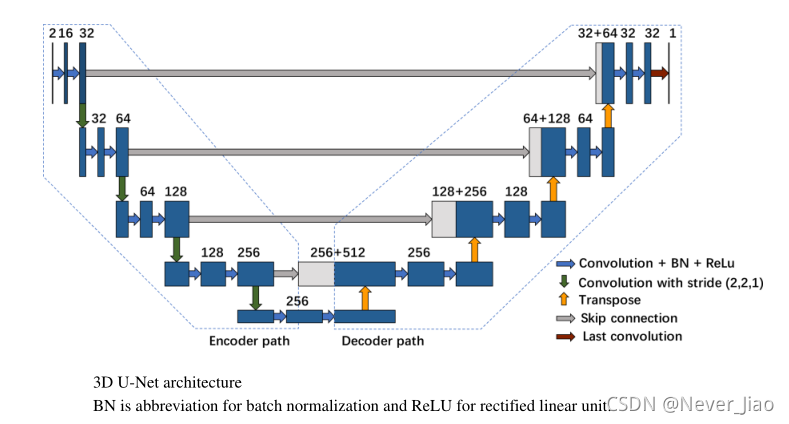
附录C. 3DU-Net结构 BN是batch normalization,,ReLU是rectified linear unit的缩写。
Evaluation metrics
使用多个度量对该方法的性能进行了定量评估。Sørensen-Dice系数(Dice,1945)是语义分割的黄金标准,它描述了ground truth和网络预测之间的空间重叠,定义为

其中P是分割结果集合,G表示ground truth描绘集合,|P|or|G|是二进制集中阳性体素的数量,| P∩G |是真阳性体素的数量。尽管较高的Dice值通常表示较好的分割结果,但它取决于目标体积大小,并且不考虑两个轮廓之间的距离。另一个补充度量是95%Hausdorff Distance(HD95)(Dubuisson和Jain,1994),用于测量分割结果的距离。
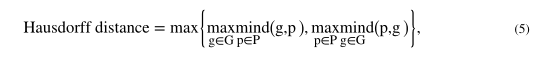
其中P和G表示网络预测和ground truth的边界表面集合,|P|和|G|表示P和G中的体素数,d(p,g)表示体素p和g之间的欧几里得距离,Hausdorff Distance是指所有表面体素的最大距离。然而,该算法对较小的离群点很敏感,并且采用HD9数来跳过离群点。HD95的值越小,通常表示结果越好。同样,平均表面距离(MSD)定义如下:
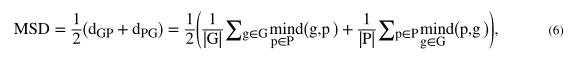
它描述了ground truth和网络预测之间的平均表面距离。
由于头部和颈部的微观结构复杂,我们还采用了ground truth图像与分割结果之间的质心偏移量(DMC)作为评价指标。质心是所有坐标方向上所有点的算术平均位置。质心的直接估计是
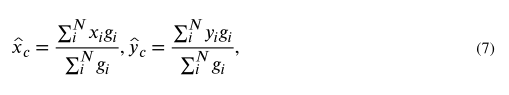
其中(xi,yi)是像素的坐标,gi∈G是二进制ground truth。求和是对与质心估计相关的所有像素的求和。同样,在相同的设置下也可以得到网络预测的质心坐标。两个质心的位移由每个维度上像素空间的欧几里得距离来分析。
Experiment setup
这个数据集由四个不同机构的250名可用患者组成。75名来自舍布克大学中心医院(舍布鲁克,QC)的患者被提供检测。其余175例患者随机分为训练组(140例)训练网络和验证组(35例),选择最佳性能模型。一旦模型被完全训练,优化后的网络随后在75名患者的独立测试数据集上进行测试,该测试数据集具有网络不可见的分布。参考方法,包括单模态的Dense-Net和3D U-Net,设置相同。将PET和CT图像作为两个输入通道输入到该网络中,并采用标注后的GTV轮廓作为训练标签。每个训练批次包含一个患者的PET/CT或单通道图像,在每个epoch对训练数据进行混洗以增加鲁棒性。为了扩大训练样本,缓解过拟合问题,通过随机平移、旋转(绕y轴90°、180°和270°)和镜像来扩大训练图像。所有的网络都是用随机权重初始化从头开始训练的。利用概率图的soft Dice(Milletari等人,2016)定义如下:
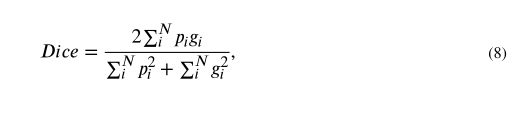
其中pi∈P是每个体素的预测概率,gi∈G是二进制ground truth。使用soft Dice作为训练目标函数,使用默认设置的Adam算法(Kingma and Ba,2014)作为优化器。所有网络均使用NVIDIA GTX 1080 Ti显卡上的TensorFlow 1.4实现。
Results
该网络针对100个epoch进行了优化。多通道Dense-Net训练需要360分钟左右。多模态图像3D U-Net、PET Dense-Net和CT Dense-Net分别需要232分钟、355分钟和355分钟。任何单模态或多模态网络的测试时间(即对新图像的分割)可以忽略不计(<1分钟)。
Feature map analysis
为了验证提取的特征的有效性,我们首先从每个密集块的输出中可视化特征地图。对于每个特征图,我们使用不同特征通道的绝对平均值来说明输出。图5显示了来自密集块的输入图像和输出的示例,并解释了我们的多模态Dense-Net的特征传播和信息流的清晰路径。如图所示,早期块的输出在颌骨区域呈现高强度,因为骨骼的体素强度在CT图像上很高。经过多个密集块处理后,骨区域的体素强度下降,肿瘤强度增强,表明网络已经学会从集成的PET和CT体素中自动选择鉴别特征。同时,空间分辨率通过向下转换模块不断降低,直到出现瓶颈(Dense block5),从而导致从Dense block5提取的特征图难以解释。由于高阶特征依赖于原始图像更少的像素级信息,随着网络的深入,特征变得更加抽象(Johnson et al., 2016)。对于解码器路径,空间分辨率通过向上过渡模块恢复,最终的GTV轮廓通过后续的卷积层逐渐显示出来。因此,最终生成的分割轮廓(绿色)恢复手动描绘的GTV轮廓(蓝色)。
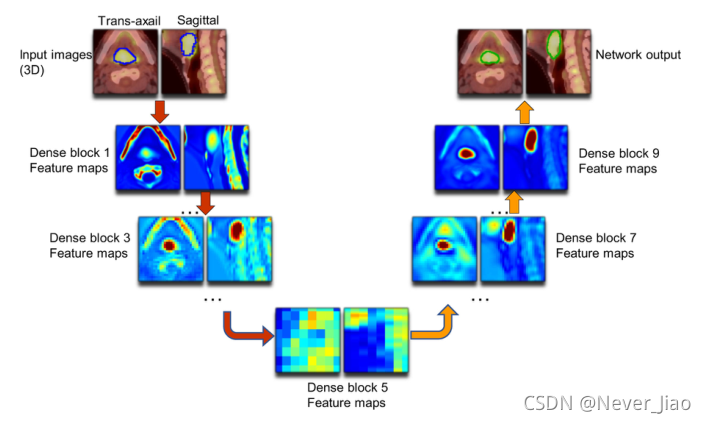 图5. Dense-Net的代表性特征图(左:轴状面;右:矢状面)。为了说明起见,显示了来自密集块1、3、5、7、9的输出。输入图像上显示的蓝色轮廓线是指手动绘制的GTV(训练标签),末尾显示的绿色轮廓线是指网络预测的GTV轮廓线(结果)。
图5. Dense-Net的代表性特征图(左:轴状面;右:矢状面)。为了说明起见,显示了来自密集块1、3、5、7、9的输出。输入图像上显示的蓝色轮廓线是指手动绘制的GTV(训练标签),末尾显示的绿色轮廓线是指网络预测的GTV轮廓线(结果)。
Qualitative results
图6显示了Dense-Net在单模态和多模态输入下的典型比较结果。如图6所示,多模态Dense-Net在Dice为0.82的情况下取得了良好的性能,而PET单模态输入的性能仅为0.60。PET图像上肿瘤体素强度较高,有助于定位肿瘤位置,但肿瘤代谢不均匀,导致GTV内出现暗区。
幸运的是,在多模态输入的帮助下,我们提出的网络可以利用CT图像提供的纹理信息来圈定假阴性区域。相比之下,使用单一模态作为输入,网络输出轮廓只能跟随PET摄取轮廓,从而导致假阴性结果。该比较实例表明,多模态Dense-Net的输出轮廓可以同时考虑CT和PET的解剖和功能信息,具有比单一模态网络更好的性能。
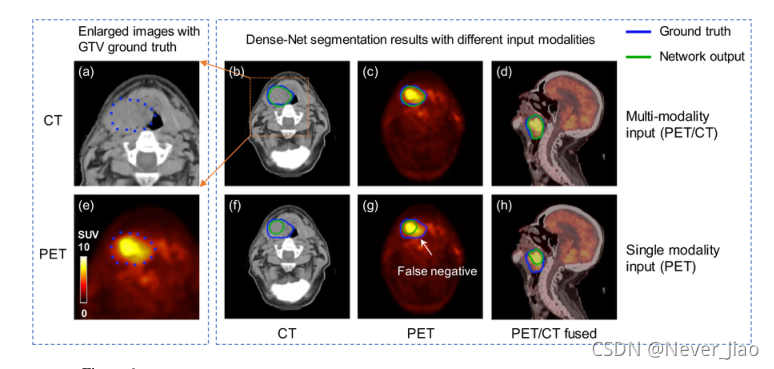
图6.具有不同输入方式的Dense-Net的代表性结果。(a,e)放大原发肿瘤和淋巴结的GTV轮廓的CT和PET图像。(b,c,d)PET/CT多模态输入的Dense-Net分割结果。使用PET单模态输入的(F,g,h)Dense-Net分割结果。蓝色轮廓表示GTV ground truth,绿色轮廓表示网络输出。
图7显示了所提出的Dense-Net和3D U-Net之间的另一种比较,并且多模态PET/CT图像被馈送到这两个网络中。显然,PET图像在分割网络中占据主导地位,因为PET图像提供了更具体的肿瘤区域信息。3D U-Net的结果遵循了这一观察结果,输出轮廓更多地依赖于PET突出显示的区域。同样,CT图像的解剖信息可以补偿PET图像的异质摄取。但是需要合适的网络来从一个通道的输入图像中提取和利用解剖信息。与3D U-Net(Dice=0.72)相比,提出的多模态Dense-Net(Dice=0.80)能更好地描绘GTV轮廓。三维可视化也证实了我们提出的方法可以更好地恢复原始的GTV,特别是在白色箭头所指的区域。这可能是因为Dense-Net中的卷积层由于信息流的改善,总是可以通过密集的连接间接地从输入图像中获得更多的信息。
图7.多模态Dense-Net和3D U-Net分割结果的比较。(a)输入图像;(b)多模态Dense-Net结果; © 3D U-Net结果;(d,e,f)分别对应于(a,b,c)的3D可视化。
图8和表1总结了Dice、MSD、HD95和DMC在验证数据集和测试数据集上的网络性能。基于测试数据集的结果,所提出的多模态Dense-Net可以在PET和CT输入图像的情况下获得Dice中位数0.73,平均和标准偏差(STD)为0.71±0.10,MSD为3.10±1.14 mm,HD95为8.98±6.34 mm,质心位移为4.82±3.30 mm。同时,3D U-Net的Dice为0.69±0.11,MSD为3.57±2.08 mm,HD95为11.16±9.69 mm,质心位移为5.16±3.77 mm,均低于Dense-Net。当使用单模态输入时,Dense-Net PET显示的Dice中位数为0.64±0.16(MSD为4.53±3.31 mm,HD95为14.75±12.17 mm,质心位移7.82±6.56),是比较方法中最低的。对CT作为单模态输入的Dense-Net也进行了研究,但结果极低,Dice中位数为0.32。MSD不适用于用CT单输入测量网络输出。由于CT图像中软组织的对比度较低,如果没有补充信息,几乎不可能进行GTV勾画。因此,在本研究中,我们忽略了使用CT单一模态的Dense-Net结果。我们使用右尾配对学生t检验来评估指标差异的显著性,即备选假设设置为:Dice多模态Dense-Net>Dice比较法。实验结果表明,我们提出的多模态Dense-Net比3D U-Net(p值=0.015)和带PET的Dense-Net(p值<0.001)上具有更好的分割精度。可训练参数由3D U-Net的35.3M显著降低到5.58M。
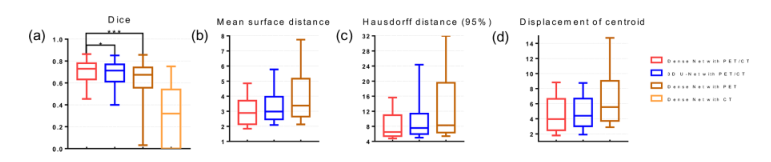
图8.网络性能的统计结果(a)Dice盒图(框为中位数和25~75个百分位数,竖线为2.5~97.5个百分位数),(b)平均表面距离(MSD),©Hausdorff Distance(95%)(HD95),(d)质心位移。(b)、©和(d)采用相同的框图策略。*代表p值<0.001,***代表p值<0.05。
研究了GTV体积大小与分割性能的关系。如图9(a)所示,较大的肿瘤往往以较小的方差获得较好的分割结果,而对于较小的病变,分割性能并不稳定。图9(b)总结了每种尺寸(5cm3)箱子(原文为bin,怎么翻译更合适呢)的平均Dice。为了进行定量分析,我们根据患者的体积大小将患者分为两组。Dice结果显示大组(体积大小>30cm3,Dice平均值±STD:0.75±0.07)和小组(体积大小<30cm3,Dice:0.65±0.10)之间存在显着差异(p值<0.001)。很明显,Dice受GTV体积的影响,小体积导致骰子值的大变化并降低整体性能。
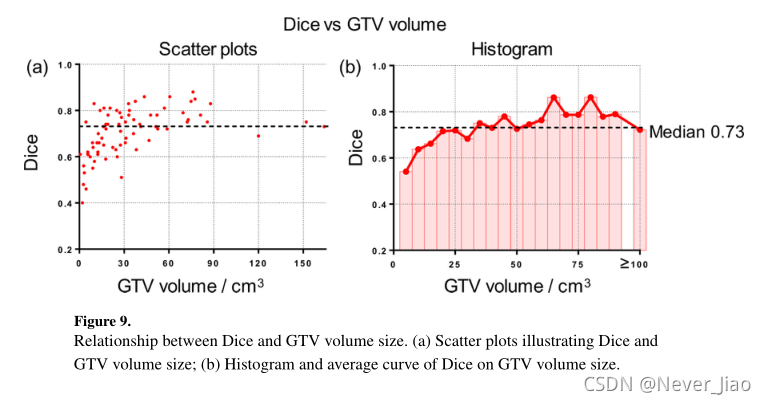
图9. Dice和GTV体积大小之间的关系。(a)Dice和GTV体积大小的散点图;(B)Dice关于GTV体积大小的直方图和平均曲线。
Discussion
在这项工作中,我们提出了一种用于HNC GTV分割的多模态分割框架。我们的结果表明,该网络可以有效地从CT和PET图像中学习解剖学和新陈代谢信息,并且与最先进的参考方法相比,可以产生更好的分割结果。此外,基于我们提出的网络的GTV结果与参考方法相比具有较小的可变性,这对于需要花费大量精力收集大量人工标记图像的RT应用是至关重要的。
我们提出的体系结构采用了3D卷积和密集连接,这给HNC分割任务带来了一些好处。首先,三维卷积可以从体积数据中提取更多的三维信息,这与放射科医生通常参照Z轴上相邻的切片来描绘GTV的临床实践是一致的。然而,三维卷积的内存消耗和繁重的计算负担限制了它的应用。然后,我们提出的网络在网络中引入密集连接来克服这一问题,并使每个卷积层能够访问来自其所有先前层的特征地图。这种连接模式可以鼓励信息和梯度的传播,缓解梯度消失问题,降低过拟合风险。此外,特征重用还可以在网络深入时减少可训练参数,从而降低过度拟合的风险,对临床应用至关重要。
虽然我们提出的网络的性能要好于参考方法,但是我们在测试阶段仍然观察到了失败的案例,这使得中位数Dice为0.73,而不是突出的其他分割任务。==一个原因是由于形态学的复杂性导致HNC GTV分割任务的复杂性,另一个原因是网络结构还有待改进。==图10显示了一组分割性能较差的失败案例。图10(a)(b)显示了我们提出的网络在摄取PET图像后可以用突出显示的喉部区域来描绘GTV的例子。然而,由于肿瘤的CT对比度不够,边界附近的假阳性增加了分母,从而获得了相对较低的Dice系数(图10(a):0.55,(b):0.62)。在这些病例中,有几个患者可以显著降低总体统计数据。此外,我们还观察到,小肿瘤往往与小的真阳性区域产生低Dice,而且Dice系数忽略了不同区域的解剖学意义或相关性。例如,在不考虑小物体的情况下,较大的肿瘤有更大的真阳性区域和更好的Dice。图10©(d)的Dice是0.74,它显示了一个非常好的描绘结果,尽管无法识别淋巴结。
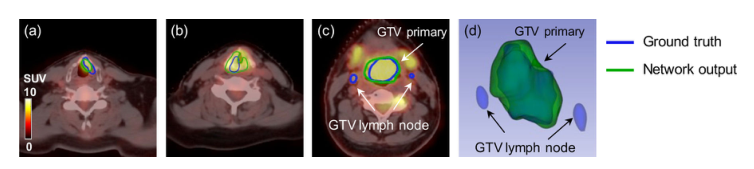
图10.具有假阳性和假阴性区域的典型案例。(a)喉部肿瘤患者的PET/CT图像;(b)食道周围肿瘤患者的PET/CT图像;©大肿瘤和淋巴结转移患者的PET/CT图像;(d)©中GTV的三维可视化。
由于数据准备和实施的限制,仍有一些尝试可以达到更好的分割效果。首先,在预处理过程中,可以通过细化GTV轮廓、校正图像伪影和完善图像配准来进一步提高图像质量。其次,由于内存的限制,原始图像被裁剪到128×128×48立方体。较大的输入量,例如没有裁剪的整个PET/CT图像,可能会产生更好的分割性能,并且可以更容易地转换到临床上。此外,还可以在多模态Dense-Net中加入额外的图像模态,以进一步提高分割精度。例如,磁共振成像(MRI)以其出色的软组织对比度、多平面成像能力和有利于剂量控制而成为HNC的标准实践。双能量计算机断层扫描(DECT)是指在两个不同峰值能量水平下同时进行CT扫描的新技术。特别是,可以从增强后的图像中减去碘,以改善头颈部癌症的图像质量、肿瘤-软组织边界的确定和关键结构的侵袭。双层螺旋CT线性结合的伪单色图像可以减少金属伪影,对头颈部肿瘤特别有利。从理论上讲,在我们的网络中结合这些图像模式可以更好地描述肿瘤边界,并提供一个稳健的靶区体积估计。
Conclusion
在这项研究中,我们提出了一种用于HNC放射治疗的GTV分割框架。该方法利用三维卷积充分利用图像的三维空间信息,并利用密集连接改善多模态图像的信息传播。所提出的多模态Dense-Net已成功应用于HNC患者,获得了满意的GTV分割结果。对比研究表明,我们提出的网络可以在较少的训练参数下获得比其他最先进的方法更好的分割精度,这在帮助医生为不同类型的癌症患者制定放疗计划方面具有很大的潜力。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









