









FocusNetv2: Imbalanced large and small organ segmentation with adversarial shape constraint for head and neck CT images
发表时间:2021
发表期刊:Medical Image Analysis
Abstract
放射疗法是一种使用放射线来消除癌细胞的治疗方法。危险器官 (OAR) 的描绘是放射治疗计划中避免损害健康器官的重要步骤。对于鼻咽癌,需要提前精确分割20多个OAR。这项任务的挑战在于复杂的解剖结构、低对比度的器官轮廓以及大小器官之间极度不平衡的大小。平等对待它们的常用分割方法通常会导致小器官标记不准确。我们提出了一种新颖的两阶段深度神经网络 FocusNetv2,通过使用专门设计的小器官定位和分割子网络自动定位、ROI 池化和分割小器官,同时保持大器官分割的准确性,从而解决这一具有挑战性的问题.除了我们最初的 FocusNet,我们对小器官采用了一种新颖的对抗性形状约束,以确保估计的小器官形状和器官形状先验知识之间的一致性。我们提出的框架在自收集的 1,164 次 CT 扫描数据集和 MICCAI 头颈自动分割挑战 2015 数据集上进行了广泛测试,与最先进的头颈 OAR 分割方法相比,它显示出卓越的性能。
Keywords
Organs-at-risk segmentation、Head and neck CT image、Semantic segmentation
Introduction
放射治疗是治疗癌症的重要方法。高能辐射束聚焦在肿瘤区域以阻止肿瘤细胞分裂,最终导致肿瘤细胞死亡。然而,辐射并不是癌细胞特有的,也会损害健康细胞。对于鼻咽癌,在放疗期间,头颈部(HaN)区域的20多个高危器官(OAR)可能会受到影响,这可能会导致副作用,包括吞咽困难、口干、低视力、视力障碍、辐射诱发的下颅神经病变等。因此,在放疗治疗计划期间,放射科医生需要准确规划放射治疗路径,以确保正常器官接受的辐射剂量在安全范围内。
危险器官勾画质量是影响放疗疗效和副作用的核心因素。临床上,放射科医师必须花费数小时手动描绘器官,见图 1。这通常非常耗时,并且需要放射科医生的高度专业性。在一些欠发达地区,合格的放射科医生是非常稀缺的资源。因此设计一种高性能、鲁棒的OAR分割算法可以有效缓解这一困境,减轻医生的工作量,提高放疗质量,减少患者的等待时间,对患者和医生都有很大的好处。

Fig.1 鼻咽癌放射治疗中的20多个器官。在我们的大规模自收集数据集中对22个器官注释的可视化。该任务的关键困难在于复杂的解剖结构,软组织的低对比度以及大小器官之间的极端不平衡样本。
这项任务的主要难点在于以下几个方面。 首先,解剖结构复杂,HaN 中的 20 多个 OARs 具有各种结构和复杂的形状。 例如,视交叉不是光滑的凸形,而是X形。 其次,由于CT成像的限制,软组织的对比度相对较低。 它通常不能清楚地显示器官的边界,使器官边界的自动定位成为一项具有挑战性的任务。 此外,头部和颈部的器官大小非常不平衡。 大小器官的大小之比可达数百倍,如腮腺占据数万个体素,而脑垂体仅占据约100个体素。
在过去的十年中,提出了许多方法来解决头颈部器官分割这一具有挑战性的问题。在只有少量带注释的图像可用的情况下,通常使用基于Atlas的方法。但是,它们基于图像配准技术,可能会产生不正确的器官描绘,尤其是当肿瘤占据器官时。基于atlas的方法的时间成本可能会花费数十分钟,因为它的计算量很大。最近,卷积神经网络 (CNN) 凭借其强大的特征表示能力,在OAR分割方面取得了革命性的进展 (Ibragimov和Xing,2017; Raudaschl等人,2017; Fritscher等人,2016; Wang等人,2017; Ren等人,2018; Zhu等人,2019)。但是,现有的分割cnn并未针对不平衡的器官分割任务进行优化。这些网络通常会为大型器官产生精确的分割图,而小型器官的准确性通常会被牺牲。此外,现有的深度学习方法经过了诸如交叉熵损失等每像素损失的训练,无法保证预测器官形状与先验知识之间的一致性。
为了解决上述问题,我们观察专业医生是如何划定 OAR 的。对于大型器官,他们通常以常规比例标记它们。对于小器官,他们首先定位粗略位置并放大以进行准确描绘。对于 CT 图像中边界模糊的器官,医生通常会根据已有的医学知识在图像上拟合一个形状。以视交叉为例,医生通常会在图像的大致位置尽可能地贴上 X 形标签。根据这一观察,我们提出了一种新颖的 3D 卷积神经网络 FocusNetv2,该网络经过精心设计,可在 HaN CT 扫描中准确分割大器官和小器官。为了更好地规范预测的器官形状,除了我们最初的 FocusNet (Gao et al., 2019),我们进一步提出了一种新的对抗性自动编码器 (AAE),将形状约束作为分割网络的额外监督。
我们方法的总体框架如图 2 所示。特别是,我们的网络有两个主要组成部分:分割网络和用于器官形状约束的对抗性自动编码器(AAE)。分割网络在一个两阶段框架中解决极度不平衡的数据,该框架由三部分组成:主分割网络(S-Net)、SmallOrgan Localization branch(SOL-Net)和 Small-Organ Segmentation branch(SOS-Net)。它模仿了医生如何描绘医学图像的过程。分割网络首先使用主分割网络 (S-Net) 分割所有器官,并使用小器官定位分支 (SOL-Net) 定位一系列预定义小器官的中心位置。 SmallOrgan 分割分支 (SOS-Net) 对多尺度特征和高分辨率图像进行 ROI 池化,以生成小器官标签图。在使用提出的对抗性自动编码器 (AAE) 进一步添加形状约束后,它鼓励分割网络的预测与不同器官的先前形状一致,即使 CT 图像中没有明确的边界。据我们所知,这是第一个利用自动编码器和对抗学习进行形状正则化的分割方法。

Fig.2 提出的focusnetv2的总体框架。
本文是我们初步工作 FocusNet (Gao et al., 2019) 的扩展(在以下论文中表示为 FocusNetv1)。对方法和实验进行了一些修改,包括通过新提出的对抗性自动编码器对器官形状先验建模、对更大数据集的额外实验以及更多消融研究。本文的其余部分安排如下。第 2 节回顾了医学图像语义分割、OAR 分割和 CNN 形状约束的相关工作。第 3 节描述了提出的 OAR 分割框架和对抗形状自动编码器,以实现更好的器官形状正则化。第 4 节介绍了实验结果。最后,第 5 节总结了方法和实验。
Related work
CNNs for medical image segmentation
最近,卷积神经网络由于能够从数据中学习更具代表性的特征,极大地推动了医学图像分析领域的发展。CNNs在许多具有挑战性的任务中展示了最先进的性能,例如图像分类,分割,检测,配准,超分辨率等。
Long等人(2015年)首次提出了全卷积网络(FCN),该网络使用卷积和1×1大小的滤波器来替换全连接层,并允许同时预测多个像素。Ronneberger等人(2015)进一步构建了一个“U”形网络(称为U-Net),具有收缩路径和对称扩张路径。跳跃连接还用于将特征从早期图层传播到后期图层。大量基于FCN和U-Net变体的作品被应用于二维医学图像分割领域(Christ等人,2016年;Yi等人,2019年;Brosch等人,2016年;Roth等人,2016年;Tan等人,2018年)。
对于CT或MR等3D图像,可以逐层使用2D CNN,但忽略了体积数据中编码的上下文信息。一些2.5D方法(Roth等人,2014年;Xu等人,2017年)试图通过使用三个正交切片或相邻切片来整合3D空间信息。但它们的表示能力仍然受到二维卷积核的限制。为了克服这个缺点,提出了基于3D CNN的算法。例如,Jçek等人(2016)提出了U-Net的3D版本;Milleri et al.(2016)提出了V-Net,它引入了构建块之间的残差连接(He et al.,2016),以缓解梯度消失问题。还针对不同的应用提出了几种3D网络,如Merkow等人(2016年);窦等人(2016);Kamnitsas等人(2017年)。
尽管基于3D CNN的方法可以更好地利用空间上下文来学习更好的特征表示,但由于训练误差主要由属于大型器官的体素控制,因此在3D任务中样本不平衡问题会被放大。Ronneberger等人 (2015) 提出使用加权交叉熵损失函数,而Milletari等人 (2016) 提出Dice损失,他们只能缓解不平衡数据的挑战,但离解决它还很远。
OAR segmentation for head and neck region
针对不同身体部位的放射治疗计划,提出了许多OAR分割工作。基于图集的方法是最常用的传统方法之一。具有预分割注释图的图集与要分割的图像之间的最佳转换通过仿射和可变形配准进行对齐。然后,可以通过在参考图像的注释图上应用此变换来获得目标图像的分割。参考图像可以是多个具有从训练集中生成的专家注释或模板的图像。基于图集的方法的准确性受两个因素影响: 第一,配准方法的能力,是否可以准确地对齐目标图像和图集图像。已经提出了不同的方法,例如 Demons 配准 (Thirion, 1998; Qazi et al., 2011)、块匹配 (Ourselin et al., 20 0 0; Han et al., 2008) 和 B-Spline 配准 (Zhang et al., 2009 年。其次,一些器官的生理或病理解剖变异使得很难找到目标图像和参考图像之间的最佳对应关系,因此提出了一些方法来使用反映患者平均解剖结构的地图集(Comowick等人,2009年)或多地图集结果的融合(Comowick和Malandain,2007年;Rohlfing等人,2004年)。一些混合方法使用活动轮廓 (Zhang et al., 2009) 和图形切割 (Van der Lijn et al., 2011; Fortunati et al., 2013) 对基于图集的分割结果进行后处理。尽管基于图谱的方法具有鲁棒性的优点,并且可以在没有用户交互的情况下执行分割,但它们基于图像配准技术,如果器官被肿瘤占据,可能会生成不正确的器官图。由于计算量巨大,时间成本可能高达数十分钟。
最近,采用卷积神经网络显着提高了 OAR 描绘的准确性。 Ibragimov and Xing (2017) 提出了第一个基于深度学习的算法。他们首先通过头部中心点检测 OAR,然后训练基于patch的 CNN 对感兴趣区域中的体素进行分类。任等人(2018) 提出了一种交错的 3D-CNN,用于联合分割 HaN 中的小器官,其中感兴趣的区域是通过配准技术获得的。朱等人(2019)提出了一种用于快速分割的 3D 挤压和激发 U-Net。童等人 (2018)提出了一种具有形状表示模型的全卷积神经网络。唐等人(2019)还提出了一种基于检测的两阶段分割方法,其中在分割头中应用局部对比度归一化以实现更好的分割性能。还有一些方法 (Mlynarski et al., 2020) 在其他方式(例如 MRI)中分割 OAR。
Shape regularization in segmentation CNNs
当前基于 CNN 的方法通常使用像素损失进行训练,例如交叉熵损失和Dice损失,它们分别考虑像素的预测误差。 即使有足够大的感受野,它们也无法保持感兴趣器官的整体形状或更高层次的结构。 条件随机场(CRF)和图切割方法被提出来强制输出标签图的空间连续性。 有几种方法试图在 CNN 中加入形状约束。 Mosinska et al(2018) 合并了一个预训练的 VGG 网络,从网络的预测和ground truth标签图中提取高阶拓扑特征,然后最小化它们之间的 L 2 损失。 然而,ImageNet 预训练的 VGG 网络可能无法捕获医学图像中各种器官的解剖结构。 奥克泰等人(2017)使用自动编码器(AE)从真实标注中学习形状的表示,并最小化网络预测标签图和ground truth标签图的编码潜在代码之间的欧几里得损失。 Tong等人(2018年)在OAR的分割中应用了与Oktay等人(2017年)类似的想法。Al Arif等人(2018年)修改了UNet,以生成有符号距离函数(SDF),而不是分割patch图,并使用主成分分析(PCA)直接在形状域中计算误差。对抗性损失也被引入高阶形状正则化(Yang等人,2017年;Xue等人,2018年)。上述方法的基本思想是相似的,即不是在像素域用ground truth测量形状相似性,而是通过不同类型的投影(即预先训练的VGG网络、自动编码器、PCA或鉴别器)在低维流形中测量相似性。因此,关键是形状投影的质量。然而,现有的对抗性鉴别器缺乏泛化能力。Oktay等人(2017)的自动编码器;Tong等人(2018年)只接受了ground truth注释的训练。分割模型不能很好地对各种预测形状进行编码。为了缓解这个问题,我们提出了一种新的基于自动编码器的对抗性形状约束,它结合了自动编码器和对抗性鉴别器的优点。
这项工作和以前的工作有三个主要区别。首先,我们设计了一个具有较少下行采样的高性能骨干网络,但使用DenseASPP(Yang等人,2018年)保留更详细的高分辨率信息,并学习多尺度特征。其次,我们使用了一个两阶段的小器官分割模型来解决大器官和小器官之间的不平衡问题。第三个也是最关键的区别是,我们使用对抗式自动编码器将形状约束应用于网络预测,这允许我们的网络生成符合先前医学知识的预测形状,用于边界不清和对比度低的特定器官。在实际的临床应用中,我们的模型可以产生更能被人类医生接受的描绘结果,从而提高放疗治疗计划的效率。
Method
提出的 FocusNetv2 的整体结构如图 2 所示。 FocusNetv2 包含两个主要部分,分割网络和用于形状正则化的对抗性自动编码器。他们以对抗的方式接受训练。对于分割网络,它模仿人类医生如何描绘医学图像:以规则的比例标记大器官,而对于小器官,他们首先定位它们,然后放大以进一步准确描绘。因此,分割网络首先使用主分割网络(SNet)分割所有器官,并使用 SmallOrgan 定位分支(SOL-Net)定位小器官中心位置。 SmallOrgan 分割分支 (SOS-Net) 从小器官位置汇集多尺度特征和原始 CT 图像,以生成小器官标签图。因此,所提出的分割网络可以解决HaN OAR分割的类不平衡问题。
为了更好地正则化分割网络输出的形状,我们提出了一种对抗式自动编码器(AAE)来约束估计的小器官形状。AAE使用两种类型的输入进行训练:ground truth标签图和来自我们SOS网络的预测掩码。分割网络和AAE以对抗的方式交替训练。AAE试图对更好的形状表示进行编码,而SOS网络则试图预测与先前医学知识一致的更真实的形状。
Segmentation network
Main segmentation network(S-Net)
U-Net是一种常用的二维CNN,与传统方法相比,它在医学图像分割方面取得了很大的进步。最近,它的3D变体通过更好地捕捉体积上下文信息来解决3D图像的分割问题。然而,vanilla 3D U-Net在头颈部器官分割方面表现不佳。我们观察到,它的效果主要来自两个方面。首先,U-Net具有对称的编解码结构,编码器通过四个下采样操作将多尺度信息嵌入到特征图中,而解码器通过一系列上采样或反卷积操作逐渐从高层特征图重建空间分辨率。然而,过多的下采样会导致高分辨率信息的丢失,这将对只占据少数体素的小器官产生灾难性影响。虽然在编码器和解码器之间的跳跃连接中使用了高分辨率特征,但低级别和高级别特征的融合只能在一定程度上缓解问题。其次,通过多次下采样学习多尺度特征,使得高层特征的尺度固定,表示能力有限。
我们提出的 S-Net 旨在解决上述问题。如图 3 所示,S-Net 具有强大的主干,它是具有残差连接的 3D U-Net 的变体。 Squeeze and excitation 模块 (Hu et al., 2018) 用于通道注意。 S-Net 建立在 SEResBlock 之上,其详细结构如图 3 所示。为了减少信息丢失和 GPU 内存使用和分割精度之间的平衡,S-Net 只执行了两次 2X 下采样。 然而,这种结构的缺点是感受野有限,因此很难整合全局图像模式来学习高级特征。 因此,我们的 S-Net 也采用了扩张卷积和密集连接的空洞空间金字塔池 (DenseASPP) (Yang et al., 2018)。 密集连接的 ASPP 能够通过调整扩张率来组合任意尺度的特征,并具有更好的特征重用性。 在我们的模型中,我们使用 3、6、12、18 的膨胀率。应该注意的是,膨胀仅应用于卷积核的x和y轴,而沿z轴的膨胀速率固定为1。这是因为许多小器官只存在于几个连续的切片中。跳跃连接还用于融合编码器和解码器的相同比例的特征,以学习更好的特征。

Fig.3 我们的 S-Net 结构用于具有多尺度特征学习的器官分割。正方形表示特征体积,边长表示特征体积大小。Dense ASPP 中的 d 表示每个卷积核的膨胀率。
Small-organ localization network(SOL-Net)
尽管 S-Net 使用了几个组件来提高性能,但大小器官之间的类不平衡问题仍然阻碍了网络准确分割小器官。 医生通常放大以精细描绘小器官,这类似于两阶段检测或实例分割方法中的 ROI-pooling 操作。
对于 OAR 定位,OAR 的位置、方向和大小在患者之间通常是一致的,并且不会像自然图像中的一般对象一样发生变化。因此,直接回归小器官关键点位置更适合 OAR 定位。受关键点检测任务 (Newell et al., 2016) 的启发,我们建议设计一个小器官定位网络 (SOL-Net) 来定位小器官的中心位置。如图 2 所示,我们的 S-Net 解码器最后一层的特征量被用作 SOL-Net 的输入。训练目标是小器官中心位置热图,创建为以小器官中心位置为中心的 3D 高斯分布,标准差为 5 个体素,每个小器官都有一个单独的地图(不是很懂)。 SOL-Net 被训练来预测具有 L 2 损失的中心位置热图。 它由 1 个 SEResBlock 和一个最终的 1×1×1 卷积层和一个 sigmoid 层组成,用于输出小器官位置概率图。 有了这样的位置图,我们可以进一步从小器官位置中提取 ROI-pool 特征量,以便准确地分割它们。
Small-organ segmentation network(SOS-Net)
鉴于来自 SOL-Net 输出的小器官的中心位置,我们通过关注每个小器官的周围区域来进一步提高分割精度。具体来说,给定一个小器官的位置概率图,我们首先将具有最高位置概率值的体素识别为小器官中心位置,并在其周围 ROI-pool 一个 3D 特征量。考虑到定位误差和我们收集的数据集中小器官的大小,所有小器官的 ROI 大小固定为 8 × 64 × 64(物理空间为 24 × 64 × 64 mm)。这与我们最初的 FocusNetv1 (Gao et al., 2019) 不同,为了实施考虑,ROI 大小设置为 OAR 大小的三倍,因为我们添加了对抗性自动编码器来规范小器官的估计形状。每个小器官的分割采用小器官分割网络(SOS-Net)。
为了为小器官的分割添加更多高分辨率信息,S-Net解码器最后一层的多尺度特征体以及原始输入图像从小器官ROI-pool,并连接在一起作为SOS-Net的输入。直观地说,来自S-Net的多尺度特征体已经编码了小器官的初始分割结果,原始图像体可以帮助细化分割结果。SOS网络由2个SEResBlocks和1×1×1卷积层组成,卷积层带有一个sigmoid层,用于输出每个小器官的二进制掩模。提出的两阶段定位细化策略可以同时消除下采样的信息丢失和大小器官之间的类别不平衡。为了输出所有器官的统一分割结果,我们将SOS网络的小器官分割结果叠加到S网络的大器官分割结果中,以获得所有器官的最终分割图。
Segmentation loss
在我们的任务中,最大器官和最小器官的比例可以达到接近 500:1,这使得损失以大量的大器官体素样本为主。 在最近的文献中,Focal loss (Lin et al., 2017) 和广义dice loss是试图解决类别不平衡问题的两个有效损失函数。 我们建议使用加权focal loss进行多类分割,
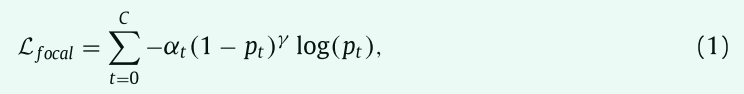
其中,C是类别的数量,Pt是类别t的概率。对于训练S-Net,αt是每个器官的权重,它与每个器官的平均大小成反比。(1 − Pt )γ 是调节因子,其对预测置信度Pt接近1的易样本 (体素) 的权重较小,对具有挑战性的样本的权重较大。Focal loss可以自适应地降低易样本造成的损失,同时可以轻微抑制分类不正确的困难样本的影响。在我们的实验中,根据经验将 γ 设置为2。
广义dice loss是另一种直接优化评估指标的损失函数。我们采用以下广义dice loss,
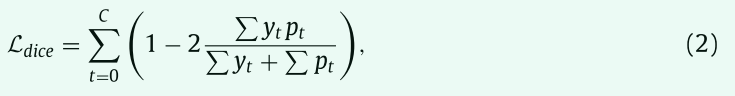
其中 yt 和 pt 表示真实标签和类别 t 的预测概率。在我们的实验中,focal loss 和 dice loss 的组合产生了最好的分割精度。因此,总分割损失定义为

其中 λ 对两个损失进行加权,我们在实验中根据经验设置 λ = 1。
Shape regularization with adversarial autoencoder(AAE)
由于 CT 的成像原理,一些 OAR 在图像中没有显示出明显的边界,例如视交叉。 由于 OAR 是正常器官,它们通常在不同患者之间具有相对一致的形状,在分割网络中加入高阶形状约束可以使预测与先前的解剖知识更加一致。 我们提出了一种新颖的对抗性自动编码器(AAE),将形状正则化引入到我们的分割框架的训练中。 据我们所知,这是第一个利用自动编码器和对抗性学习来约束分割掩码的分割方法。
一个好的形状正则化项设计应该具有以下两个特点。首先,它需要能够以可微分的方式表示形状,以便可以通过反向传播训练分割网络以进行形状正则化;其次,它应该能够区分形状之间的细微差异,这样当分割网络预测的形状越来越接近真实形状时,它仍然会给出正确的惩罚。
标签映射所代表的形状是高度结构化和高维的,这使得在这样的高维空间中测量两个形状之间的相似性变得极具挑战性。高维形状通常位于一个低维形状流形中(Wang et al.,2014; Oktay et al.,2017),其中每个形状将被映射到子空间中的一个低维点(向量)。如果一个形状流形被成功地发现,从流形上的一个点(对应于一个特定的形状)(我理解为低维形状流形中的一个点对应高维形状中的一个特定的形状)开始,我们可以沿着流形上的不同方向遍历。相应的形状将在语义层面平滑而连续地变化。
因此,我们在低维形状流形中测量两个形状之间的相似性。我们使用形状自动编码器,这是一个经过训练的神经网络,可以尽可能地重建输入器官的形状(见图 4)。瓶颈结构使自动编码器能够将输入形状转换为潜在代码,该代码捕获其显著特征,同时丢弃不相关的特征。因此,如果自编码器能够很好地重构输入形状,则潜在空间是低维形状流形的良好近似(Lei et al., 2020; Zhu et al., 2016)。此外,自动编码器是可微的,并且可以通过最小化潜在空间中预测器官形状和真实形状之间的距离来规范估计的器官形状。

Fig.4 具有形状重建损失和对抗性 L 2 损失的对抗性自动编码器的结构。
对于第二个特征,准确测量预测器官形状和ground truth器官形状之间的相似性至关重要。因此,我们引入了一种对抗式训练方案来训练对抗式自动编码器。自动编码器使用来自小器官分割分支的预测形状和相应的ground truth形状进行训练。它有两个损失项,第一个是通过最小化传统的重建损失来重建输入形状以学习形状表示,
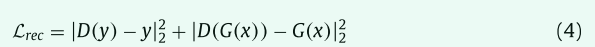
其中 x 是输入图像,y 是其对应的真实标签,G 是分割网络,G ( x ) 是给定输入图像的 SOS-Net 预测的二进制器官掩码,D ( y ) 和 D ( G ( x )) 是 给定ground truth y和预测的器官掩码G(x)的AAE 的重建结果。
另一个对抗性损失项试图通过最大化其在低维流形中的距离来区分预测形状和ground truth形状的潜在代码。通过这种方式,我们强制使用自动编码器来更好地对两种类型的形状进行编码并捕获它们的细微差异,而鼓励分割网络将自动编码器愚弄为无法捕获细微差异。因此,建议的对抗性形状损失公式化为
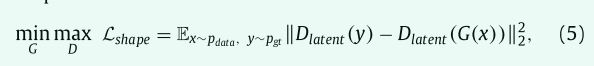
其中,Dlatent(y) 或Dlatent(G (x )) 是ground truth器官形状y和预测器官形状G (x) 的潜码和多尺度解码器特征,如图4所示。直观地,分割网络G和AAE D进行最小最大游戏。分割网络G试图预测和形状先验一致的掩膜以最小化低维形状流中的距离,而AAE D试图学习更好的编码以最大化距离。
因此,分割网络的总体目标函数和来自对抗式自动编码器的形状正则化项被定义为

在实践中,分割网络 G 和对抗性自动编码器 D 是在另一种优化方案中进行训练的。 G首先通过固定D并最小化以下损失来优化

其中 λ1 根据经验设置为 5 以平衡这两项。优化 LG 将鼓励分割网络 G 输出与真实形状一致的器官形状。然后当 G 固定时通过最小化以下损失来优化 D:

其中 λ2 在我们的实验中设置为 0.001,因为较大的 λ2 可能会导致所提出的 AAE 的训练不稳定。在分割网络 G 的训练过程中,G 估计的器官形状将逐渐接近真实器官形状,因此,如果编码的潜在代码无法区分估计器官形状和真实器官形状,则自编码器可能很难为分割网络 G 提供有效的监督。因此,最大化 Dlatent(G (x)) 和 Dlatent(y) 之间的距离会鼓励自动编码器对它们之间的细微差别进行编码。等式 (7) 和 (8) 交替优化,以逐步改进分割网络 G 和对抗性自动编码器 D。
使用自动编码器或对抗性学习进行分割的讨论以前的分割方法也探索了在分割中使用自动编码器。奥克泰等人(2017)和童等人(2018)只训练了具有真实器官形状的自动编码器。然后训练分割网络以最小化来自预测形状的自动编码器和ground truth形状的潜在特征之间的距离,其中自动编码器的参数是固定的。然而,由于自编码器从未使用分割网络预测的器官形状进行训练,当估计的器官形状接近真实形状时,单独的自编码器的潜在代码无法区分这两者,因此自编码器无法提供有效指导进一步规范分割网络。此外,在童等人 (2018) 中,自动编码器使用整个图像进行训练。自编码器训练也面临着极度不平衡的数据,从而使得小器官形状表示的训练无效。在我们的方法中,我们在小器官分支中采用了自动编码器,从而避免了不平衡类问题。
之前的几项工作(Yang et al., 2017; Han et al., 2018)采用以下方式在分割网络中使用目标函数进行对抗训练
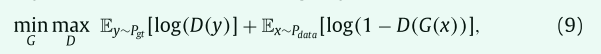
其中x是输入图像,y是其对应的ground truth形状,G是分割网络,G (x) 是预测的器官形状,D是鉴别器网络,它试图区分其输入是真实的还是假的 (即ground truth标签或网络预测掩码)。但是,D以前被设计为分类器,而我们在最小最大游戏中采用了形状自动编码器。
Experiments
Datasets
提出的 FocusNetv2 在两个 HaN CT 图像数据集上进行了评估。第一个数据集是一个自我收集的数据集,表示为我们的数据集。我们的数据集由 1164 份收集的鼻咽癌患者 CT 扫描组成。在每次扫描中描绘了在 HaN 放射治疗计划中要考虑的 22 个 OAR,包括(左和右)眼睛、(左和右)晶状体、(左和右)视神经、视交叉、垂体、脑干、(左和右)颞叶、脊髓、(左和右)腮腺、(左和右)内耳、(左和右)中耳、(左和右)颞下颌关节和(左和右)下颌骨。每个病例的ground truth注释由具有数百例注释经验的资深医生提供,每个结构由同一个注释者分割,并由另一个注释者审查。左右晶状体、左右视神经、视交叉、垂体因体积小、解剖结构复杂而被定义为小器官。CT扫描的各向异性体素间距为0.78毫米至1.25毫米,层间厚度为2.7毫米至3.5毫米。所有扫描重新采样至1×1×3 mm,以便进一步处理。我们随机抽取数据集,选择1044个样本进行训练,120个样本进行测试。
为了与最先进的HaN OAR分割方法进行比较,我们在公共数据集MICCAI Head and Neck Auto segmentation Challenge 2015数据集(表示为MICCAI’15数据集)上评估了建议的FocusNetv2。该数据集也称为哈佛医学院提供和维护的计算解剖学公共领域数据库(PDDCA)。该数据集包括来自口咽、下咽或喉III或IV期鳞状细胞癌患者的多幅图像研究。它由 38 个用于训练的 CT 扫描和 10 个用于测试的扫描组成,并具有 9 个器官注释:脑干、下颌骨、视交叉、(左右)视神经、(左右)腮腺和(左右)下颌下腺体,视交叉、左右视神经被定义为小器官。结构的描绘基于放射治疗肿瘤学组 (RTOG) 描述的协议。我们对所有扫描进行重新采样,使其体素大小为 1 × 1 × 2.5 mm 以训练我们的 FocusNetv2,同时为了与其他方法进行公平比较,我们通过我们提出的方法将预测的分割标签重新采样回原始间距,然后计算评估指标。
Implementation details
我们的方法是用Pytork实现的,并在NVIDIA TITAN Xp GPU上进行了培训。分割网络从零开始训练,初始权值取自标准高斯分布。我们首先训练S-Net,然后训练SOLNet,同时确定S-Net的训练参数。SOS-Net随后进行训练,并以另一种方式使用对抗式自动编码器进行更新。最后,我们对整个网络进行微调,以进行联合优化。我们使用ADAM优化器以0.05的学习率训练网络。批量大小设置为1。对于对抗式自动编码器,在数据集中使用地面真相标签对其进行预训练,以稳定对抗式训练过程。
原始CT图像大小约为n×512×512,其中n为切片数。由于每个CT图像的大部分是背景,因此它们被集中裁剪为n×240×240。最好使用整个图像卷来训练网络。然而,由于GPU内存的限制,在训练S-Net和SOL-Net时,我们从CT图像中沿z轴为每次迭代随机裁剪40个patch块。滑动切片策略带来的一个问题是,裁剪过程可能会破坏器官的形状以训练 AAE 和 SOS-Net。 由于两个数据集中的小器官主要是晶状体、视神经、视交叉和垂体。 它们仅位于沿 z 轴的几个相邻切片中,这些切片可以完全包含在一个 40 切片的立方体中,并且有很大的余量。 因此,我们在训练 AAE 和 SOS-Net 时采用了抽样策略。 尽管我们沿 z 轴随机平移对立方体进行采样,但我们始终确保立方体包含所有具有一定边距的小器官。 因此,小器官的形状是完整的。 CT 扫描每 40 个切片裁剪一次,沿 z 轴的步幅为 40,即裁剪之间没有重叠。然后我们将每个 40 切片的分割结果堆叠在一起以获得最终预测。 随机变换(x 和 y 轴上 40 个像素内的平移,10 度内的旋转,以及从 0.7 到 1.3 倍的缩放)用于训练期间的数据增强。
Evaluation metrics
我们在本研究中使用了两个评估指标。 Dice score coefficient (DSC) 使用公式 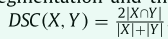
衡量预测分割和ground truth分割之间的重叠程度,其中 X 和 Y 分别代表预测和ground truth的体素集。 95% Hausdorff Distance(95HD) 是 Hausdorff Distance的变体,它测量 X 中的点到 Y 中最近邻点的最大距离。 HD 计算为两个方向的平均值,HD = (d H (X, Y ) + d H (Y, X)) / 2 。 95% Hausdorff Distance可以通过计算 95% 的最大距离来减轻异常值的敏感性。
Experiments on our collected dataset
我们将我们提出的方法与基于多图集的方法进行比较,其中对称归一化 (SyN) (Avants et al., 2008) 用作配准方法、DeepLabv3+ 的 3D 变体 (Chen et al., 2018) 和HaN OAR 分割中最先进的深度学习方法,名为 AnatomyNet (Zhu et al., 2019)。
对于基于多图谱的方法,由于约束和计算资源的限制,我们从训练集中随机选择9个CT扫描作为图谱。对称归一化(SyN)(Avants et al.,2008)及其在ANTs软件包中的实现用于恢复要分割的CT和每个图谱之间的最佳仿射矩阵和可变形变换场。将变换域应用于atlas标签,得到9个标签图,然后通过投票获得最终预测。DeepLabv3+(Chen et al.,2018)是一个著名的分割框架,最初设计用于二维语义切分。它使用空间金字塔池化和扩展卷积,实现了自然图像分割的最新性能。我们将它们的网络结构扩展到3D,用于体积分割。它被随机初始化,并使用与我们建议的FocusNetv2相同的损失函数进行训练。AnatomyNet(Zhu et al.,2019)设计用于对整个CT图像进行快速分割,与传统的基于Atlas的方法相比具有良好的性能。
Quantitative comparison
比较结果如表1和表2所示。 传统的基于多图谱的方法 SyN 在大器官上具有良好的性能,特别是对于那些与周围区域(例如下颌骨)具有高对比度的器官。 然而,对于小尺寸的器官,它会导致不理想的分割结果。 基于深度学习的方法在这些情况下具有压倒性优势,因为小器官具有更复杂的解剖结构,基于多图集的方法 SyN 处理复杂多样的解剖变化的能力有限。基于深度学习的方法之一,即使没有敌对的autoencoder,我们在大多数器官FocusNetv1性能更好。这是因为,我们的特别设计的两级框架大大降低背景,大器官和小器官之间的极其不平衡的比例。每个小器官分支都可以专注于指定器官的分割,其中包含高分辨率的详细信息以进行详细完善。在结合了拟议的对抗性自动编码器的对抗性形状损失之后,可以通过较大的边距进一步提高小器官的分割精度。和其他方法相比,我们的FocusNet在22个器官中的19个器官中获得了最佳的Dice得分,在22个器官中的19个器官中获得了最佳的95HD得分。就小器官的准确性而言,与其他基于深度学习的方法相比,我们的FocusNetv2在Dice得分上有5.59% 的提高。
表1 在我们收集的数据集上,通过不同比较方法得出的Dice得分系数(%)结果。阴影行表示这些器官被视为小器官。

表2 在我们收集的数据集上,不同比较方法的HD95 (mm)的结果。阴影行表示这些 OAR 被视为小器官。

Qualitative comparison
如图5所示,在前两行中,基于多图谱的方法SyN错过了左晶状体,并且在分割视神经方面表现不佳,这与定量结果一致。DeepLabv3在眼球附着在晶状体上的区域存在错误。可能是因为DeepLabv3以低分辨率处理图像,然后向上采样到原点分辨率以进行最终预测,从而导致详细信息的丢失。在第三行中,对于视交叉,尽管基于多图谱的方法的结果不够准确,但其形状符合先前的医学知识。DeepLabv3和AnatomyNet更倾向于预测其结果中的平滑形状,这是最先进的细分深度学习网络的常见问题。这是因为解剖轮廓的低对比度和器官的极小体积的结合使小器官的训练无效。此外,基于像素的损失不能惩罚高水平的形状误差。通过合并建议的小器官分割分支和对抗性形状自动编码器,我们的FocusNetv2生成令人满意的X形状分割掩模。这证明了我们的FocusNetv2成功地将形状约束引入深度学习框架。它可以达到满意的分割精度,同时使分割结果与先前的医学知识一致。

Processing time
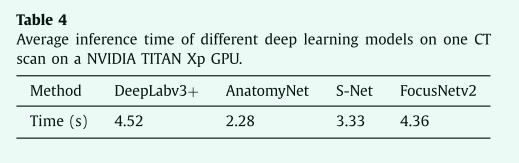
深度学习方法的处理时间如表4所示,所有方法都使用相同的计算平台和NVIDIA TITAN Xp GPU进行测量。我们的骨干网络S-Net平均需要3.33秒来处理一次CT扫描。在添加SOL-Net和SOS-Net后,我们的Focus usNetv2需要4.36秒,仍然比DeepLabv3+快,但分割精度要高得多。我们的方法比AnatomyNet消耗更多的计算资源,但比DeepLabv3+少。考虑到放射治疗计划通常需要几个小时,并且不是一个时间敏感的任务,我们的方法可以在合理的时间内实现最佳性能。
表4在NVIDIA TITAN Xp GPU上进行一次ct扫描时,不同深度学习模型的平均推理时间
在使用和不使用我们算法的结果的情况下,我们进一步测试了医生的平均描绘时间。 人类医生在头颈部 CT 扫描中描绘 22 个 OAR 通常需要大约一个小时。 如果我们的算法结果用于辅助,医生只需要对大多数患者的自动勾画结果进行小的修改。 整个勾画时间仅需20-30分钟,比以前缩短了1/3到1/2。 它可以显着提高放射科医生的效率。
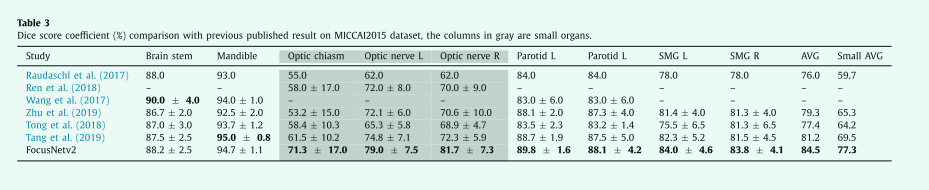
表3 Dice score coefficient (%) 与之前在 MICCAI2015 数据集上公布的结果比较,灰色的列是小器官。
Experiments on MICCAI’15 dataset
Comparison with state-of-the-arts
我们还在MICCAI 2015头颈数据集上测试FocusNetv2。FocusNetv2的所有设置与我们收集的数据集上的实验中使用的设置相同,只是小器官的数量设置为3,包括左右视神经和视交叉。
我们将我们的方法与之前发表的最新结果进行比较。图6显示了我们的方法在一些测试用例上的可视化。Dice分数和95 HD分数如表3和表5所示,我们的方法显示出优越的整体性能,并大大优于以前最先进的方法。尤其是在小器官方面,我们的FocusNetv2比以前最先进的方法高出7.8%。Ren等人(2018年)提出了一种用于联合分割视神经和交叉的交错3D CNN。他们在从配准获得的小目标体积中执行基于patch的分割。Wang等人(2018b)提出了一种基于顶点回归的方法,该方法在脑干和下颌骨方面具有良好的性能。然而,它在腮腺中的表现相对较差,并且没有提供其他器官的结果。Zhu等人(2019年)提出了AnatomyNet,它声称我们的主干S-Net也有类似的想法。但它们只会减少下采样操作的数量,这会导致有限的感受野,从而在预测的标签图中产生异常值。我们的S-Net引入了紧密连接的ASPP,这不仅扩大了感受野,还学习了更好的多尺度特征表示。它输出的错误更少,如表5中的95HD所示。

表5 在MICCAI’15数据集上,通过不同比较方法得出的95HD分数(mm)结果。

童等人 (2018) 首次将形状约束引入到 HaN OAR 分割中。 他们使用自动编码器从训练数据集中学习潜在形状表示。 我们的方法和他们的方法之间的主要区别在于两个方面。 首先,我们使用对抗训练来学习形状表示,不仅适用于ground truth标签,还适用于来自分割网络的估计分割掩码。 因此,自编码器可以更好地编码估计和ground truth器官掩码之间的细微差异,从而为分割网络提供更有效的梯度,并使分割网络的预测与ground truth形状更加一致。 其次,他们以原始尺度训练所有器官的形状表示模型。 然而,由于背景、大器官和小器官之间的比例极不平衡,导致分割网络对小器官的训练不足,也会影响自编码器对形状表示的学习。 因此,我们只在我们提出的 SOS-Net 中整合对抗性形状损失,使小器官的形状表示更有效。 我们的对抗性形状损失的显著性能改进证明了我们方法的有效性。
Tang等人(2019年)使用了一种两阶段方法,包括一个OAR检测模块和一个OAR分割模块,其中OAR检测模块识别OAR的位置和大小,分割模块在OAR区域内进一步分割。由于OAR在患者中的位置和大小相对一致,而使用目标检测模块需要仔细设计锚定大小,并且容易出现假阳性,因此,我们的方法通过OAR中心位置回归对OAR进行定位,并根据训练集的统计信息确定ROI的大小。通过特殊设计的结构,我们的主干S-Net的性能与Tang等人(2019年)相当,在引入小器官分割分支和提议的对抗性形状损失后,我们的最终FocusNetv2大大优于他们的。
Ablation studies
我们还对 FocusNetv2 的每个组件对 MICCAI’15 数据集的影响进行了消融研究。结果如表6所示。我们首先对 S-Net 中下采样操作数量的影响进行了实验。我们分别用交叉熵损失和 1、2、3 和 4 下采样(表示为“SEResUNet_dX”)训练 SEResUNet。随着下采样次数的减少,整体 Dice 得分和小器官的 Dice 得分会上升。 SEResUNet_d2 和 SEResUNet_d1 的性能相似,但 SEResUNet_d2 在小器官上的性能稍好一些。利用Focal loss和Dice loss(表示为“SEResUNet_d2_FL_DL”)大大提高了分割精度。进一步将 ASPP 模块组合到 S-Net 中(表示为“SEResUNet_d2+ASPP”)可以稍微提高性能。引入小器官定位网络和小器官分割网络(记为“FocusNetv1”),可以解决类不平衡问题。在通过对抗性自动编码器添加形状约束后,FocusNetv2 将小器官的 Dice 得分显着提高了 5.94%。表 6 中的“FocusNetv2 no concat”仅将来自 S-Net 的 ROIpooled 特征作为小器官分割网络(SOS-Net)的输入,其中未连接原始 CT 图像。它还采用 AAE 形状约束。我们观察到原始 CT 图像对小器官分割的细化有很大的影响。
表6 FocusNetv2 各部分的消融研究。 Small Dice 是视交叉、左右视神经三个小器官的平均Dice分数。 UNet_d4 表示 SEResUNet 进行了 4 次下采样,对于 d3、d2 和 d1 以此类推,它们是用交叉熵损失训练的。 FL是focal loss,DL是Dice loss

最后,我们进行一个实验显示autoencoder的对抗训练的有效性,FocusNetv2 w / AE起源在表6所示。autoencoder只是训练重建的真实形状的输入数据集。autoencoder的参数是固定的规范的培训细分网络类似于童et al .(2018),除了正规化只应用于小器官分割分支。随着autoencoder没有针对分割网络训练,其正则化能力是有限的。FocusNetv2 w / origin AE的性能比提出的FocusNetv2低了4.11%,这证明了我们的对抗autoencoder的有效性。
Robustness of SOL-Net and SOS-Net
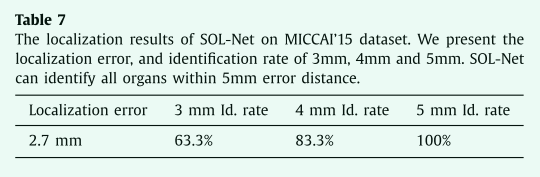
小器官的分割性能可能会受到小器官定位精度的影响。如果器官边界框偏离ground truth 位置太远,则SOS-Net将很难准确地分割小器官。因此,我们进行了实验来分析我们提出的SOL-Net和SOS-Net的鲁棒性。首先,我们分析了SOL-Net的定位精度,如表7所示。对于所有小器官,SOLNet的平均定位误差 (估计质心与ground truth质心之间的平均距离) 约为2.7毫米。我们进一步测量不同距离内的小器官定位率。如果器官的估计质心与ground truth质心在一定距离内,则认为该器官已正确定位。63.3% 的小器官位于3毫米内,83.3% 可以位于4毫米内。如果我们将距离扩展到5毫米,所有小器官都可以正确定位。
表7 SOL-Net在miccai'15数据集上的定位结果。我们给出了定位误差,以及3毫米、4毫米和5毫米的识别率。SOL-Net可以识别5毫米误差距离内的所有器官。
尽管我们的SOL-Net可以定位误差较小的小器官,但我们进行了另一项实验,以探索定位误差对以下分割模型的影响。在训练了包括S-Net,SOL-Net,SOS-Net在内的分割网络之后,所有参数都是固定的。然后,我们没有使用SOL-Net中的本地化边界框,而是获得了小型器官的ground truth框,并添加了随机转换来模拟本地化错误。然后,使用随机移位的框来指导ROI池化以通过SOS-Net进行细分。结果如表8所示。对于5毫米内的定位误差,存在分割精度的轻微降低。即使定位误差达到9毫米,性能下降仍在可接受的范围内。考虑到我们的SOL-Net的5毫米定位率达到100%,我们的方法对SOL-Net的定位误差具有鲁棒性。
表8 MICCAI’15 数据集上具有不同定位误差的小器官的平均 Dice 得分。 SOL-Net 是指使用来自 SOL-Net 的定位结果。 其余部分使用ground truth器官质心,但添加了距离为 0 mm、1 mm、3 mm、5 mm、7 mm 和 9 mm 的随机平移。

Limitations and future works
尽管我们的方法表现出强大的性能并且可以加速临床应用中的放射治疗计划过程,但它仍然远非完美。我们的形状约束目前仅适用于小器官,因为在训练形状自动编码器时还存在样本不平衡问题。直接为所有器官训练自动编码器会偏爱大器官,而忽略大部分小器官,从而难以约束小器官的分割结果。考虑到 SNet 对于大器官具有良好的性能,而对于小器官,患者之间存在显着差异,我们只对边界模糊的小器官应用形状约束,以鼓励网络生成与形状先验一致的预测。**此外,我们目前的培训有多个阶段,这使得培训过程复杂。**这是从性能角度考虑的。在我们的实验中,网络在端到端训练时无法达到最佳性能。
未来的改进主要有几个方向。第一种是采用新的CNN技术,如注意机制(Wang等人,2018a;Fu等人,2019),以增加骨干网络的容量和能力。相对位置编码(Dai等人,2019年)可用于学习器官之间和器官内的相对位置信息。此外,还可以提供模型的不确定性估计(Lakshminarayanan等人,2017),这对临床应用具有重要意义。它允许医生更加关注模型不确定的区域。此外,我们提出的对抗性形状约束可以应用于更多的器官和身体部位,以实现全自动全身放疗规划。
Conclusion
我们提出了一种新的具有对抗性形状约束的分割框架,该框架在大边缘HaN CT图像中大小不平衡器官的分割方面优于现有的方法。该框架包括两个部分,一个两阶段分割网络和一个作为形状正则化的对抗式自动编码器。两级分割网络是专门为HaNdCT图像中的OAR不平衡问题而设计的。通过减少下采样次数,利用DenseASPP学习的多尺度特征,我们的S-Net可以保证大器官分割的准确性。通过训练预测小器官中心位置图,我们的SOL-Net可以生成精确的小器官中心位置。SOS-Net可以解决分类不平衡的问题,高分辨率的特征体积可以用来精确分割小器官,从而进一步提高性能。使用我们新的对抗式自动编码器,我们的框架不仅可以学习形状表示,还可以为器官掩膜编码更具辨别力的特征。它能够为分段网络的训练提供更好的监督。在大量真实患者数据和MICCAI 2015数据集上进行的大量实验表明了我们提出的框架的有效性。
Appendix A
Network details
在本节中,我们将提供有关网络结构的更多详细信息,包括分割网络和自动编码器。
自动编码器的结构如表9所示,这是一种卷积自动编码器。除FC层外,在每个ReLU层之前也会使用批量标准化。我们在解码器中使用三线性上采样层和卷积层,而不是转置卷积层。第一个FC层(512维特征向量)的输出是自动编码器的潜在代码。
表9对抗式自动编码器模型的结构。

分割网络的结构如表10所示,包括S-Net、SOL-Net和SOS-Net。对于SOS-Net,第一个maxpooling使用 (1,2,2) 的核大小,因为CT图像的间距是各向异性的,并且在z轴上较大。在解码器中,SOS-Net使用三线性上采样层和SEResBlocks来恢复空间分辨率。
表10 分割网络的结果

More visualization results
Supplementary material
可以在 10.1016/j.media.2020.101831 的在线版本中找到与本文相关的补充材料。















 1769
1769











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









