







为方便阅读,故将《The Algorithmic Foundations of Differential Privacy》翻译项目内容搬运至此;
教材原文地址:https://www.cis.upenn.edu/~aaroth/Papers/privacybook.pdf
中文翻译版 Github 项目地址1:https://github.com/guoJohnny/algorithmic-foundation-of-dp-zh-cn
中文翻译版 Github 项目地址2:https://github.com/doubleheiker/algorithmic-foundation-of-dp-zh-cn
感谢前辈的翻译工作!

3.6 稀疏向量技术
拉普拉斯机制可用于回答自适应选择的低敏感度查询,并且从我们的合成定理中我们知道,隐私参数与所回答的查询数量(或其平方根)成比例地降低。不幸的是,经常会发生我们有大量问题要回答的问题,即使使用 3.5节 中的高级合成定理,也有太多问题无法使用独立的扰动技术来提供合理的隐私保证。但是,在某些情况下,我们只会关心知道高于某个阈值的查询的标识。在这种情况下,我们希望通过放弃对明显低于阈值的查询的数字答案,而仅报告这些查询确实低于阈值,从而获得本质的分析。(如果我们这样选择的话,我们也将能够获得阈值以上查询的数字值,而只需花费额外的费用)。这类似于我们在3.3节中的“Report Noisy Max”机制中所做的事情,实际上,对于非交互式或脱机情况,可以选择迭代该算法或指数机制。
在本节中,我们显示如何在在线设置中分析此方法。该技术很简单:添加噪音并仅报告噪声值是否超过阈值。本节中,我们的重点是分析隐私只会随着实际高于阈值的查询数量而降低,而不会随着查询总数的增加而降低。如果我们知道位于阈值以上的查询集比查询总数小得多(也就是说,如果答案向量稀疏的话),那么将可以大量节省(隐私参数)。
更详细地讲,我们将考虑一系列事件(每个查询一个),如果在数据库上评估的查询超过给定(已知的、公共的)阈值,则会发生这些事件。我们的目标是释放一个位向量,以指示每个事件是否已发生。在提出每个查询时,该机制将计算一个噪声响应,并将其与(众所周知的)阈值进行比较,如果超过了该阈值,则将揭示此事实。由于隐私证明(定理3.24)中的技术原因,该算法适用于阈值 T T T 的噪声版本 T ^ \hat{T} T^。虽然 T T T 是公开的,但噪声版本 T ^ \hat{T} T^ 不是。
并非对每个可能的查询都造成隐私损失,后文的分析将仅针对接近或高于阈值的查询值导致隐私损失。
设置 设 m m m 表示灵敏度为 1 的查询总数,可以自适应地选择。在不丧失通用性的情况下,有一个预先固定的阈值 T T T(或者每个查询可以有自己的阈值,但结果不变)。我们将在查询值中添加噪声,并将结果与 T T T 进行比较。正向的结果意味着噪声查询值超过了阈值。我们期望 c c c (少量)个噪声值超过阈值,并且我们只释放高于阈值的噪声值。算法将 c c c 用作其停止条件。
我们将首先分析在超过阈值查询的 c = 1 c=1 c=1 之后算法停止的情况,并表明无论查询的总序列有多长,该算法都是 ε \varepsilon ε-差分隐私的。然后利用我们的合成定理分析 c > 1 c>1 c>1 的情形,并推导出 ( ε , 0 ) (\varepsilon,0) (ε,0) 和 ( ε , δ ) (\varepsilon,\delta) (ε,δ)-差分隐私的界。
3.6 稀疏向量算法:高于阈值算法
我们首先论证了 AboveThreshold 算法是私有的,并且是准确的,该算法专门针对一个高于阈值的查询。

(注:上面算法中 ⊥ \bot ⊥ 为永假含义; ⊤ \top ⊤ 为永真含义。根据上章节描述,个人理解其含义应为: ⊤ \top ⊤ 释放回答, ⊥ \bot ⊥ 拒绝回答)
定理 3.23 AboveThreshold 算法是 ( ε , 0 ) (\varepsilon,0) (ε,0)- 差分隐私的。
【证明】 固定任意两个相邻数据库 D D D 和 D ′ D' D′。设 A A A 为表示 AboveThreshold算法 ( D , f i , T , ε ) (D,{f_i},T,\varepsilon) (D,fi,T,ε) 输出的随机变量,设 A ′ A' A′ 为表示 AboveThreshold算法 ( D ′ , f i , T , ε ) (D',{f_i},T,\varepsilon) (D′,fi,T,ε) 输出的随机变量。算法的输出是这些随机变量的一些实现,即: a ∈ { ⊥ , ⊤ } k a \in \{\bot,\top\}^k a∈{⊥,⊤}k,其形式是对于所有的 i < k , a i = ⊥ , a k = ⊤ i<k,a_i=\bot,a_k=\top i<k,ai=⊥,ak=⊤ 。算法内部有两种类型的随机变量:噪声阈值 T ^ \hat{T} T^ 和对 k k k 个查询的扰动 { ν i } i = 1 k \{\nu_i\}_{i=1}^k {νi}i=1k。在下面的分析中,我们将固定(任意的) ν 1 , . . . , ν k − 1 \nu_1,...,\nu_{k-1} ν1,...,νk−1 的值。并且 ν k \nu_k νk 和 T ^ \hat{T} T^ 具有随机性。定义以下量,该量代表在 D D D 上估计任何查询 f 1 , . . . , f k − 1 f_1,...,f_{k-1} f1,...,fk−1 的最大噪声值:
g ( D ) = max i < k ( f i ( D ) + ν i ) g(D) = \max_{i<k}(f_i(D) + \nu_i) g(D)=i<kmax(fi(D)+νi)
在下文中,我们将滥用表示法,将 Pr [ T ^ = t ] \text{Pr}[\hat{T}=t] Pr[T^=t] 写为 T ^ \hat{T} T^ 在 t t t 处的概率密度函数的简写( ν k \nu_k νk 也类似这样的表示),并写 1 [ x ] \mathbf{1}[x] 1[x] 表示事件 x x x 的指示函数 < 1 > \ ^{<1>} <1>。注意固定 ν i , . . . , ν k − 1 \nu_i,...,\nu_{k-1} νi,...,νk−1 的值(这使 g ( D ) g(D) g(D) 为确定量),我们有:
Pr T ^ , ν k [ A = a ] = Pr T ^ , ν k [ T ^ > g ( D ) and f k ( D ) + ν k > T ^ ] = Pr T ^ , ν k [ T ^ ∈ ( g ( D ) , f k ( D ) + ν k ] ] = ∫ − ∞ ∞ ∫ − ∞ ∞ Pr [ ν k = v ] ⋅ Pr [ T ^ = t ] 1 [ t ∈ ( g ( D ) , f k ( D ) + v ] ] d v d t = ∗ \begin{aligned} \underset{\hat{T},\nu_k}{\text{Pr}}[A=a] &= \underset{\hat{T}, \nu_k}{\text{Pr}}[\hat{T} > g(D) \ \text{and} \ f_k(D)+ \nu_k > \hat{T}]\\ &= \underset{\hat{T}, \nu_k}{\text{Pr}}[\hat{T} \in (g(D),f_k(D)+ \nu_k]]\\ &= \int_{-\infty}^{\infty}\int_{-\infty}^{\infty}\text{Pr}[ \nu_k=v]\\ &\ \enspace \ \cdot \text{Pr}[\hat{T}=t]\mathbf{1}[t\in (g(D),f_k(D)+v]]dvdt\\ &= * \end{aligned} T^,νkPr[A=a]=T^,νkPr[T^>g(D) and fk(D)+νk>T^]=T^,νkPr[T^∈(g(D),fk(D)+νk]]=∫−∞∞∫−∞∞Pr[νk=v] ⋅Pr[T^=t]1[t∈(g(D),fk(D)+v]]dvdt=∗
我们现在对变量做一些变换,定义:
v ^ = v + g ( D ) − g ( D ′ ) + f k ( D ′ ) − f k ( D ) t ^ = t + g ( D ) − g ( D ′ ) \begin{aligned} \hat{v} &= v+g(D)-g(D')+f_k(D')-f_k(D)\\ \hat{t} &= t + g(D) - g(D') \end{aligned} v^t^=v+g(D)−g(D′)+fk(D′)−fk(D)=t+g(D)−g(D′)
注意,对于任何 D , D ′ D,D' D,D′,有 ∣ v ^ − v ∣ ≤ 2 , ∣ t ^ − t ∣ ≤ 1 |\hat{v}-v|\leq 2,|\hat{t}-t|\leq 1 ∣v^−v∣≤2,∣t^−t∣≤1 。这是因为每个查询 f i ( D ) f_i(D) fi(D) 的敏感度都是 1 1 1 的,因此量 g ( D ) g(D) g(D) 的敏感度也是 1 1 1 。应用变量的这种变化,我们有:
∗ = ∫ − ∞ ∞ ∫ − ∞ ∞ Pr [ ν k = v ^ ] ⋅ Pr [ T ^ = t ^ ] 1 [ ( t + g ( D ) − g ( D ′ ) ) ∈ ( g ( D ) , f k ( D ′ ) + v + g ( D ) − g ( D ′ ] ] d v d t = ∫ − ∞ ∞ ∫ − ∞ ∞ Pr [ ν k = v ^ ] ⋅ Pr [ T ^ = t ^ ] 1 [ t ∈ ( g ( D ′ ) , f k ( D ′ ) + v ] ] d v d t ≤ ∫ − ∞ ∞ ∫ − ∞ ∞ exp ( ε / 2 ) Pr [ ν k = v ] ⋅ exp ( ε / 2 ) Pr [ T ^ = t ] 1 [ t ∈ ( g ( D ′ ) , f k ( D ′ ) + v ] ] d v d t = exp ( ε ) Pr T ^ , ν k [ T ^ > g ( D ′ ) and f k ( D ′ ) + ν k > T ^ ] = exp ( ε ) Pr T ^ , ν k [ A ′ = a ] \begin{aligned} * &= \int_{-\infty}^{\infty}\int_{-\infty}^{\infty}\text{Pr}[\nu_k=\hat{v}]\cdot\text{Pr}[\hat{T}=\hat{t}]\mathbf{1}[(t+g(D)-g(D'))\\ &\ \qquad \qquad \enspace \in(g(D),f_k(D')+v+g(D)-g(D']]dvdt\\ &= \int_{-\infty}^{\infty}\int_{-\infty}^{\infty}\text{Pr}[\nu_k=\hat{v}]\cdot\text{Pr}[\hat{T}=\hat{t}]\mathbf{1}[t\in(g(D'),f_k(D')+v]]dvdt\\ & \leq \int_{-\infty}^{\infty}\int_{-\infty}^{\infty}\exp(\varepsilon/2)\text{Pr}[\nu_k=v]\\ &\enspace \enspace \cdot \exp(\varepsilon/2)\text{Pr}[\hat{T}=t]\mathbf{1}[t\in(g(D'),f_k(D')+v]]dvdt\\ &= \exp(\varepsilon)\underset{\hat{T},\nu_k}{\text{Pr}}[\hat{T} > g(D') \ \text{and} \ f_k(D')+ \nu_k > \hat{T}]\\ &= \exp(\varepsilon)\underset{\hat{T},\nu_k}{\text{Pr}}[A'=a] \end{aligned} ∗=∫−∞∞∫−∞∞Pr[νk=v^]⋅Pr[T^=t^]1[(t+g(D)−g(D′)) ∈(g(D),fk(D′)+v+g(D)−g(D′]]dvdt=∫−∞∞∫−∞∞Pr[νk=v^]⋅Pr[T^=t^]1[t∈(g(D′),fk(D′)+v]]dvdt≤∫−∞∞∫−∞∞exp(ε/2)Pr[νk=v]⋅exp(ε/2)Pr[T^=t]1[t∈(g(D′),fk(D′)+v]]dvdt=exp(ε)T^,νkPr[T^>g(D′) and fk(D′)+νk>T^]=exp(ε)T^,νkPr[A′=a]
不等式来自 ∣ v ^ − v ∣ |\hat{v}-v| ∣v^−v∣ 和 ∣ t ^ − t ∣ |\hat{t}-t| ∣t^−t∣的界,以及 Laplace 分布的概率密度函数。
【定理 3.23 证毕】
【补充:对上述证明过程中的不等式步骤拓展解释。由 Laplace 分布概率密度函数( v v v 的尺度参数为 4 / ε 4/\varepsilon 4/ε)可知:
Pr [ ν k = v ^ ] = 1 2 ⋅ 4 ε exp ( − ∣ v ^ ∣ 4 / ε ) Pr [ ν k = v ] = 1 2 ⋅ 4 ε exp ( − ∣ v ∣ 4 / ε ) \begin{aligned} \text{Pr}[\nu_k = \hat{v}] &= \frac{1}{2\cdot\frac{4}{\varepsilon}}\exp\big(-\frac{|\hat{v}|}{4/\varepsilon}\big)\\ \text{Pr}[\nu_k = v] &= \frac{1}{2\cdot\frac{4}{\varepsilon}}\exp\big(-\frac{|v|}{4/\varepsilon}\big)\\ \end{aligned} Pr[νk=v^]Pr[νk=v]=2⋅ε41exp(−4/ε∣v^∣)=2⋅ε41exp(−4/ε∣v∣)
由于 ∣ v ^ − v ∣ ≤ 2 |\hat{v}-v|\leq 2 ∣v^−v∣≤2,并且由绝对值不等式,可以作出如下推导:
Pr [ ν k = v ^ ] Pr [ ν k = v ] = exp ( ∣ v ∣ − ∣ v ^ ∣ 4 ε ) ≤ exp ( ∣ v − v ^ ∣ 4 ε ) ≤ exp ( 2 4 ε ) = exp ( ε 2 ) ⟹ Pr [ ν k = v ^ ] ≤ exp ( ε 2 ) ⋅ Pr [ ν k = v ] \begin{aligned} \frac{\text{Pr}[\nu_k = \hat{v}]}{\text{Pr}[\nu_k = v]} &= \exp\bigg(\frac{|v|-|\hat{v}|}{\frac{4}{\varepsilon}}\bigg)\\ &\leq \exp\bigg(\frac{|v-\hat{v}|}{\frac{4}{\varepsilon}}\bigg)\\ &\leq \exp\bigg(\frac{2}{\frac{4}{\varepsilon}}\bigg)\\ &= \exp\big(\frac{\varepsilon}{2}\big)\\ \implies \text{Pr}[\nu_k = \hat{v}] &\leq \exp\big(\frac{\varepsilon}{2}\big)\cdot \text{Pr}[\nu_k = v] \end{aligned} Pr[νk=v]Pr[νk=v^]⟹Pr[νk=v^]=exp(ε4∣v∣−∣v^∣)≤exp(ε4∣v−v^∣)≤exp(ε42)=exp(2ε)≤exp(2ε)⋅Pr[νk=v]
同样的方法应用于 T ^ \hat{T} T^ 上,其 Laplace 分布的尺度参数为 2 / ε 2/\varepsilon 2/ε,且 ∣ t ^ − t ∣ ≤ 1 |\hat{t}-t|\leq 1 ∣t^−t∣≤1
】
(译者注<1> 指示函数:是定义在某集合 X X X 上的函数,表示其中有哪些元素属于某一子集 A A A。集合 X X X 的子集 A A A 的指示函数是函数 1 A : X → { 0 , 1 } \mathbf{1}_{A}:X\to \lbrace 0,1\rbrace 1A:X→{0,1},定义为:
1 A ( x ) = { 1 if x ∈ A , 0 if x ∉ A . \mathbf{1} _{A}(x)= \begin{cases} 1 &\text{if}\enspace x \in A,\\ 0 &\text{if}\enspace x \notin A. \end{cases} 1A(x)={10ifx∈A,ifx∈/A.
详见:指示函数定义
)
定义3.9(准确度) 一个算法它的应答流
a
1
,
.
.
.
,
∈
{
⊤
,
⊥
}
∗
a_1,...,\in \{\top,\bot\}^{*}
a1,...,∈{⊤,⊥}∗ 作为对
k
k
k 个查询流
f
1
,
.
.
.
,
f
k
f_1,...,f_k
f1,...,fk 的响应。如果除了概率最大为
β
\beta
β 之外,这个算法在
f
k
f_k
fk 之前不停止,并且对于所有
a
i
=
⊤
a_i = \top
ai=⊤ 有:
f
i
(
D
)
≥
T
−
α
f_i(D) \geq T - \alpha
fi(D)≥T−α
对于所有
a
i
=
⊥
a_i = \bot
ai=⊥ 有:
f
i
(
D
)
≤
T
+
α
f_i(D) \leq T + \alpha
fi(D)≤T+α
那么,我们称这个算法对于阈值
T
T
T 是
(
α
,
β
)
(\alpha,\beta)
(α,β) -准确的。
算法1 可能出什么问题?噪声阈值 T ^ \hat{T} T^ 可能离 T T T 很远,例如 ∣ T ^ − T ∣ ≥ α |\hat{T}-T|\geq \alpha ∣T^−T∣≥α。 另外,小的 f i ( D ) < T − α f_i(D)<T-\alpha fi(D)<T−α 可能会添加大量噪声,以至于报告为高于阈值(即使阈值接近正确),而大 f i ( D ) > T + α f_i(D)>T+\alpha fi(D)>T+α 可能报告为低于阈值。所有这些都以 α \alpha α 的指数形式发生,概率很小。总而言之,我们在选择噪声阈值时可能会遇到问题,或者在一个或多个单独的噪声值 ν i ν_i νi 中可能会遇到这种问题。当然,我们可能同时存在两种错误。因此在下面的分析中,我们为每种类型分配 α / 2 \alpha/2 α/2。
(个人理解:AboveThreshold 中需要向阈值 T T T 和扰动 ν k \nu_k νk 添加 Laplace 噪声。根据 Laplace 分布的特点(下图):
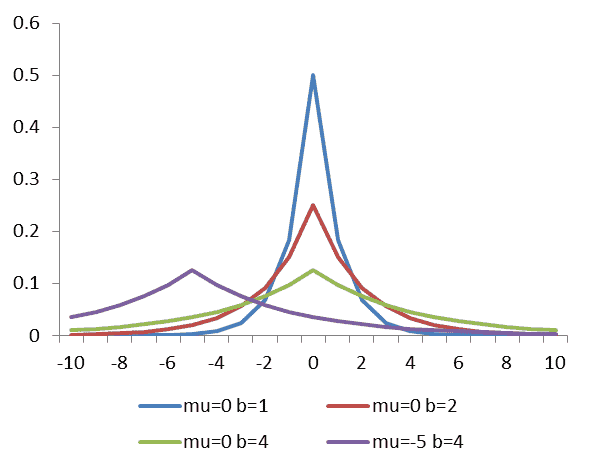
可以看出,算法会以小概率对阈值和扰动添加过大的噪声。如图的左右两侧。这就会造成上文提到的 “噪声阈值
T
^
\hat{T}
T^ 可能离
T
T
T 很远,例如
∣
T
^
−
T
∣
≥
α
|\hat{T}-T|\geq \alpha
∣T^−T∣≥α”。同样,对扰动的噪声也可能过大。这样就导致,即使
T
^
\hat{T}
T^ 与
T
T
T 接近的情况下,造成小值回答(不允许释放)超过阈值被释放;大值回答(允许释放)小于阈值被拒绝。由于 AboveThreshold 会出现这两种错误,进而不满足 定义3.9 的规定。所以对于这两种错误情况,下面定理为噪声阈值
T
^
\hat{T}
T^ 和 扰动
ν
k
\nu_k
νk 各分配
α
/
2
\alpha/2
α/2 的界。并将概率上界
β
\beta
β 和噪声取之范围
α
\alpha
α 关联起来,使得 AboveThreshold 算法不会出现两种错误情况,进而满足 定义3.9 的规定。
)
定理 3.24 对于 k k k 个查询的任何序列, f 1 , . . . , f k f_1,...,f_k f1,...,fk 使得 ∣ { i < k : f i ( D ) ≥ T − α } ∣ = 0 |\{i<k:f_i(D)\geq T - \alpha\}|=0 ∣{i<k:fi(D)≥T−α}∣=0(即,唯一接近阈值以上的查询是最后一个),当:
α = 8 ( log k + log ( 2 / β ) ) ε \alpha = \frac{8(\log k+\log(2/\beta))}{\varepsilon} α=ε8(logk+log(2/β))
AboveThreshold 算法 ( D , f i , T , ε ) (D,{f_i},T,\varepsilon) (D,fi,T,ε) 是 ( α , β ) (\alpha,\beta) (α,β)-准确的:
【证明】 如果我们能够证明除概率最大为 β \beta β 以外,当:
max i ∈ [ k ] ∣ ν i ∣ + ∣ T − T ^ ∣ ≤ α ( ∗ ) \max_{i \in [k]}|\nu_i|+|T-\hat{T}|\leq\alpha \qquad (*) i∈[k]max∣νi∣+∣T−T^∣≤α(∗)
时,由观察易得该定理。
如果是这样的情况,那么对于任意 a i = ⊤ a_i=\top ai=⊤,有:
f i ( D ) + ν i ≥ T ^ ≥ T − ∣ T − T ^ ∣ ( 1 ) f_i(D) + \nu_i \geq \hat{T} \geq T-|T-\hat{T}| \qquad (1) fi(D)+νi≥T^≥T−∣T−T^∣(1)
进一步推导:
f i ( D ) ≥ T − ∣ T − T ^ ∣ − ∣ ν i ∣ ≥ T − α ( 2 ) f_i(D) \geq T-|T-\hat{T}|-|\nu_i|\geq T-\alpha \qquad (2) fi(D)≥T−∣T−T^∣−∣νi∣≥T−α(2)
同样的,对于任意 a i = ⊥ a_i = \bot ai=⊥,有:
f i ( D ) ≤ T ^ ≤ T + ∣ T − T ^ ∣ + ∣ ν i ∣ ≤ T + α f_i(D) \leq \hat{T} \leq T+|T-\hat{T}|+|\nu_i|\leq T+\alpha fi(D)≤T^≤T+∣T−T^∣+∣νi∣≤T+α
我们将会有对于任意 i < k : f i ( D ) < T − α < T − ∣ ν i ∣ − ∣ T − T ^ ∣ i<k:f_i(D)<T-\alpha<T-|\nu_i|-|T-\hat{T}| i<k:fi(D)<T−α<T−∣νi∣−∣T−T^∣。所以: f i ( D ) + ν i ≤ T ^ f_i(D)+\nu_i\leq \hat{T} fi(D)+νi≤T^,即: a i = ⊥ a_i=\bot ai=⊥。因此,算法在第 k 个查询被回答前不会停止。
我们现在完成证明。回忆一下 事实3.7,当 Y ∽ L a p ( b ) Y\backsim Lap(b) Y∽Lap(b) 时, Pr [ ∣ Y ∣ ≥ t ⋅ b ] = exp ( − t ) \text{Pr}[|Y|\geq t\cdot b]=\exp(-t) Pr[∣Y∣≥t⋅b]=exp(−t),算法中 T ^ \hat{T} T^ 的尺度参数 b = 2 / ε b=2/\varepsilon b=2/ε 因此我们有:
Pr [ ∣ T − T ^ ∣ ≥ α 2 ] = exp ( − ε α 4 ) \text{Pr}[|T-\hat{T}|\geq \frac{\alpha}{2}]=\exp\Big(-\frac{\varepsilon \alpha}{4}\Big) Pr[∣T−T^∣≥2α]=exp(−4εα)
由定理设定最大概率为
β
/
2
\beta/2
β/2,我们可以得知:
α
≥
4
log
(
2
/
β
)
ε
\alpha\geq \frac{4\log(2/\beta)}{\varepsilon}
α≥ε4log(2/β)
。
同样,由 布尔不等式,且算法中 ν k \nu_k νk 的尺度参数 b = 4 / ε b=4/\varepsilon b=4/ε可知:
Pr [ max i ∈ [ k ] ∣ ν i ∣ ≥ α / 2 ] ≤ k ⋅ exp ( − ε α 8 ) \text{Pr}[\max_{i\in [k]}|\nu_i|\geq \alpha/2]\leq k\cdot\exp\Big(-\frac{\varepsilon \alpha}{8}\Big) Pr[i∈[k]max∣νi∣≥α/2]≤k⋅exp(−8εα)
由定理设定最大概率为
β
/
2
\beta/2
β/2,我们可以得知:
α
≥
8
log
(
2
/
β
)
+
log
k
ε
\alpha\geq \frac{8\log(2/\beta)+\log k}{\varepsilon}
α≥ε8log(2/β)+logk
。
这两个推导共同证明了该定理。
【定理 3.24 证毕】
【补充(1)式:在 AboveThreshold 算法中,当 a i = ⊤ , f i ( D ) + ν i ≥ T ^ a_i=\top,f_i(D)+\nu_i\geq \hat{T} ai=⊤,fi(D)+νi≥T^, ∣ T − T ^ ∣ |T-\hat{T}| ∣T−T^∣ 为 Laplace 噪声,故阈值必然大于等于其下界 T − ∣ T − T ^ ∣ T-|T-\hat{T}| T−∣T−T^∣ 】
【补充(2)式:由 ( ∗ ) (*) (∗) 可以推得:
max i ∈ [ k ] ∣ ν i ∣ + ∣ T − T ^ ∣ ≤ α ⟹ ∣ ν i ∣ + ∣ T − T ^ ∣ ≤ max i ∈ [ k ] ∣ ν i ∣ + ∣ T − T ^ ∣ ≤ α ⟹ − ∣ ν i ∣ − ∣ T − T ^ ∣ ≥ − α ⟹ T − ∣ ν i ∣ − ∣ T − T ^ ∣ ≥ T − α \begin{aligned} \max_{i \in [k]}|\nu_i|+|T-\hat{T}|&\leq\alpha\\ \implies |\nu_i|+|T-\hat{T}| &\leq \max_{i \in [k]}|\nu_i|+|T-\hat{T}| \leq \alpha\\ \implies -|\nu_i|-|T-\hat{T}| &\geq -\alpha\\ \implies T-|\nu_i|-|T-\hat{T}| &\geq T-\alpha \end{aligned} i∈[k]max∣νi∣+∣T−T^∣⟹∣νi∣+∣T−T^∣⟹−∣νi∣−∣T−T^∣⟹T−∣νi∣−∣T−T^∣≤α≤i∈[k]max∣νi∣+∣T−T^∣≤α≥−α≥T−α
】
3.6.1 稀疏算法
现在,我们展示如何使用合成技术处理多个“高于阈值”的查询。
稀疏算法可以认为是:当查询进入时,它会反复调用 AboveThreshold。 每次报告高于阈值的查询后,该算法仅在 AboveThreshold 的新实例上重新启动剩余的查询流。在重新启动AboveThreshold c c c 次之后停止(即在出现 c c c 个高于阈值的查询之后)。 由于 AboveThreshold 的每个实例都是 ( ε , 0 ) (\varepsilon,0) (ε,0)- 差分隐私的,因此适用合成定理。

定理 3.25 稀疏算法是 ( ε , δ ) (\varepsilon,\delta) (ε,δ)-差分隐私的。
【证明】 我们发现到 Sparse 算法完全等同于以下过程:我们对查询流 { f i } \{f_i\} {fi} 运行 AboveThreshold 算法 ( D , { f i } , T , ε ′ ) (D,\{f_i\},T,\varepsilon') (D,{fi},T,ε′),并设置:
ε ′ = { ε c if δ = 0 ; ε 8 c ln 1 δ Otherwise. \varepsilon' = \begin{cases} \frac{\varepsilon}{c} &\text{if } \delta = 0 ;\\ \frac{\varepsilon}{\sqrt{8c\ln \frac{1}{\delta}}} &\text{Otherwise.} \end{cases} ε′={cε8clnδ1εif δ=0;Otherwise.
使用 AboveThreshold 算法提供答案。当 AboveThreshold 算法停止时(在回答了1个超过阈值的查询之后),我们只需在剩余的查询流上重新启动 Sparse算法
(
D
,
{
f
i
}
,
T
,
ε
′
)
(D,\{f_i\},T,\varepsilon')
(D,{fi},T,ε′) ,并继续这个过程直到我们重新启动 AboveThreshold 算法
c
c
c 次。第
c
c
c 次 AboveThreshold 算法停止后,Sparse算法 也停止。我们已经证明了AboveThreshold 算法
(
D
,
{
f
i
}
,
T
,
ε
′
)
(D,\{f_i\},T,\varepsilon')
(D,{fi},T,ε′) 是
(
ε
′
,
0
)
(\varepsilon',0)
(ε′,0)-差分隐私的。最后,根据高级合成定理(定理 3.20 和 推论 3.21),
c
c
c 个
ε
′
=
ε
8
c
ln
1
δ
\varepsilon' = \frac{\varepsilon}{\sqrt{8c\ln \frac{1}{\delta}}}
ε′=8clnδ1ε-差分隐私算法的合成是
(
ε
,
δ
)
(\varepsilon,\delta)
(ε,δ) -差分隐私,并且
c
c
c 个
ε
′
=
ε
/
c
\varepsilon' = \varepsilon/c
ε′=ε/c- 差分隐私算法的合成是
(
ε
,
0
)
(\varepsilon,0)
(ε,0) -差分隐私。
需要证明 包含 c c c 个 AboveThreshold 算法 的 Sparse 算法的准确性。我们注意到,如果对于每个 AboveThreshold 算法 ( α , β / c ) (\alpha,\beta/c) (α,β/c) 精确的,那么 Sparse 算法将是 ( α , β ) (\alpha,\beta) (α,β) 精确的。
【定理 3.25 证毕】
定理 3.26 对于 k 个查询的任何序列, f 1 , . . . , f k f_1,...,f_k f1,...,fk 使得 L ( T ) ≡ ∣ { i : f i ( D ) ≥ T − α } ∣ ≤ c L(T)\equiv|\{i:f_i(D)\geq T - \alpha\}|\leq c L(T)≡∣{i:fi(D)≥T−α}∣≤c。如果 δ > 0 \delta >0 δ>0,当:
α = ( ln k + ln 2 c β ) 512 c ln 1 δ ε \alpha = \frac{(\ln k+\ln\frac{2c}{\beta})\sqrt{512c\ln\frac{1}{\delta}}}{\varepsilon} α=ε(lnk+lnβ2c)512clnδ1
Sparse 算法是 ( α , β ) (\alpha,\beta) (α,β) 精确的。
如果 δ = 0 \delta =0 δ=0,当:
α = 8 x ( ln k + ln ( 2 c / β ) ) ε \alpha = \frac{8x(\ln k + \ln(2c/\beta))}{\varepsilon} α=ε8x(lnk+ln(2c/β))
Sparse 算法是 ( α , β ) (\alpha,\beta) (α,β) 精确的。
【证明】 运用 定理3.24 的证明方法,将 β \beta β 设为 β / c \beta/c β/c,并分别根据 δ > 0 \delta > 0 δ>0 或 δ = 0 \delta=0 δ=0 将 ε \varepsilon ε 设为 ε 8 c ln 1 δ \frac{\varepsilon}{\sqrt{8c\ln \frac{1}{\delta}}} 8clnδ1ε 和 ε / c \varepsilon/c ε/c 即可。
3.6.3 数值稀疏算法
最后,我们给出了 Sparse 算法的一个版本,它实际上输出了高于阈值查询的数值,我们只需要在精度上损失一个常数因子就可以做到这一点。我们称这种算法为 NumericSparse,它是一种简单的使用 Laplace 机制组成的 Sparse 算法。它不是输出向量 a ∈ { ⊤ , ⊥ } ∗ a \in \{\top,\bot\}^* a∈{⊤,⊥}∗ ,而是输出向量 a ∈ ( R ∪ { ⊥ } ) ∗ a \in (\mathbb{R} \cup \{\bot\})^* a∈(R∪{⊥})∗。
我们发现 NumericSparse 算法是具有隐私性的:
定理 3.27 NumericSparse 算法是 ( ε , δ ) (\varepsilon,\delta) (ε,δ)- 差分隐私的。
【证明】 我们发现,如果
δ
=
0
\delta=0
δ=0,则NumericSparse算法
(
D
,
{
f
i
}
,
T
,
c
,
ε
,
0
)
(D,\{f_i\},T,c,\varepsilon,0)
(D,{fi},T,c,ε,0) 就是 Sparse 算法
(
D
,
{
f
i
}
,
T
,
c
,
8
9
ε
,
0
)
(D,\{f_i\},T,c,\frac{8}{9}\varepsilon,0)
(D,{fi},T,c,98ε,0) 的自适应组合,其中输出具体数值使用了具有隐私参数
(
ε
′
,
δ
)
=
(
1
9
ε
,
0
)
(\varepsilon',\delta)=(\frac{1}{9}\varepsilon,0)
(ε′,δ)=(91ε,0) 的 Lapalace 机制。如果
δ
>
0
\delta>0
δ>0,则 NumericSparse 算法
(
D
,
{
f
i
}
,
T
,
c
,
ε
,
δ
)
(D,\{f_i\},T,c,\varepsilon,\delta)
(D,{fi},T,c,ε,δ) 是 Sparse 算法
(
D
,
{
f
i
}
,
T
,
c
,
512
512
+
1
ε
,
δ
/
2
)
(D,\{f_i\},T,c,\frac{\sqrt{512}}{\sqrt{512}+1}\varepsilon,\delta/2)
(D,{fi},T,c,512+1512ε,δ/2) 的自适应组合, 其中输出具体数值使用了具有隐私参数
(
ε
′
,
δ
)
=
(
1
512
ε
,
δ
/
2
)
(\varepsilon',\delta)=(\frac{1}{\sqrt{512}}\varepsilon,\delta/2)
(ε′,δ)=(5121ε,δ/2) 的 Lapalace 机制。
因此,NumericSparse 算法的隐私来自简单的组合。
【定理 3.27 证毕】
要讨论准确性,我们必须定义一种机制的准确性,这是指响应一系列数值查询而输出流 a ∈ ( R ∪ { ⊥ } ) ∗ a \in (\mathbb{R} \cup \{\bot\})^* a∈(R∪{⊥})∗ 的含义:

定义3.10(数值精度) 一个响应 k k k 个查询流 f 1 , . . . , f k f_1,...,f_k f1,...,fk 并输出应答流 a 1 , . . . , ∈ ( R ∪ { ⊥ } ) ∗ a_1,...,\in(\mathbb{R} \cup \{\bot\})^* a1,...,∈(R∪{⊥})∗ 的算法,如果除概率最大为 β \beta β 之外,算法不会在 f k f_k fk 之前停止,并且对于所有 a i ∈ R a_i \in \mathbb{R} ai∈R 有:
∣ f i ( D ) − a i ∣ ≤ α |f_i(D)-a_i|\leq \alpha ∣fi(D)−ai∣≤α
对于所有 a i = ⊥ a_i =\bot ai=⊥,有:
f i ( D ) ≤ T + α f_i(D) \leq T + \alpha fi(D)≤T+α
则这个算法是相对于阈值 T T T 的 ( α , β ) (\alpha,\beta) (α,β) 准确。
定理 3.28。 对于 k k k 个查询的任何序列 f 1 , . . . f k f_1,...f_k f1,...fk 使得 L ( T ) ≡ ∣ { i : f i ( D ) ≥ T − α } ∣ ≤ c L(T)\equiv|\{i:f_i(D)\geq T-\alpha\}|\leq c L(T)≡∣{i:fi(D)≥T−α}∣≤c ,如果 δ > 0 \delta>0 δ>0,当:
α = ( ln k + ln 4 c β ) c ln 2 δ ( 512 + 1 ) ε \alpha = \frac{(\ln k+\ln \frac{4c}{\beta})\sqrt{c\ln \frac{2}{\delta}}(\sqrt{512}+1)}{\varepsilon} α=ε(lnk+lnβ4c)clnδ2(512+1)
NumericSparse 算法是相对于阈值 T T T 的 ( α , β ) (\alpha,\beta) (α,β) 准确的。
如果 δ = 0 \delta=0 δ=0,当:
α = 9 c ( ln k + ln ( 4 c / β ) ) ε \alpha = \frac{9c(\ln k + \ln(4c/\beta))}{\varepsilon} α=ε9c(lnk+ln(4c/β))
NumericSparse 算法是相对于阈值 T T T 的 ( α , β ) (\alpha,\beta) (α,β) 准确的。
【证明】 精度需要两个条件:首先,对于所有 a i = ⊥ : f i ( D ) ≤ T a_i =\bot:f_i(D)\leq T ai=⊥:fi(D)≤T: Sparse 准确定理以 1 − β / 2 1-\beta/2 1−β/2 概率成立。另外,对于所有 a i ∈ R a_i\in \mathbb{R} ai∈R ,它要求 ∣ f i ( D ) − a i ∣ ≤ α |f_i(D)-a_i|\leq \alpha ∣fi(D)−ai∣≤α 。 这通过 Laplace 机制的精度以 1 − β / 2 1-\beta/2 1−β/2 概率成立。
【定理 3.28证毕】
我们到底显示了什么?如果给我们一系列查询,并保证只有最多 c c c 个答案的答案高于 T + α T+\alpha T+α,我们就可以回答高于给定阈值 T T T 的那些查询,直至误差 α \alpha α。如果我们事先知道进行这些高于阈值查询的身份,并使用拉普拉斯机制进行回答,那么在给定相同的隐私保证的情况下,此精度等于(等于常数和 log k \log k logk)。也就是说,稀疏向量技术允许我们几乎“免费”地辨别这些大型查询的身份,只为这些不相关的查询进行对数精度的响应。这种算法与另一种形式(通过指数机制找到造成隐私损失大的查询,然后通过拉普拉斯机制响应这些查询)提供相同的保证。然而,这个稀疏向量算法运行起来很简单,而且最关键的是,它允许我们自适应地选择查询。
参考文献
Randomized Response is due to Warner [84] (predating differential privacy by four decades!). The Laplace mechanism is due to Dwork et al. [23]. The exponential mechanism was invented by McSherry and Talwar [60]. Theorem 3.16 (simple composition) was claimed in [21]; the proof appearing in Appendix B is due to Dwork and Lei [22];
McSherry and Mironov obtained a similar proof. The material in Sec-tions 3.5.1 and 3.5.2 is taken almost verbatim from Dwork et al. [32].\text{Pr}ior to [32] composition was modeled informally, much as we did for the simple composition bounds. For specific mechanisms applied on a single database, there are “evolution of confidence” arguments due to
Dinur, Dwork, and Nissim [18, 31], (which pre-date the definition of differential privacy) showing that the privacy parameter in k-fold com- √k position need only deteriorate like k if we are willing to tolerate a (negligible) loss in δ (for k < 1/ε2). Theorem 3.20 generalizes those arguments to arbitrary differentially private mechanisms.The claim that without coordination in the noise the bounds in the composition theorems are almost tight is due to Dwork, Naor, and Vadhan [29]. The sparse vector technique is an abstraction of a tech- nique that was introduced, by Dwork, Naor, Reingold, Rothblum, and Vadhan [28] (indicator vectors in the proof of Lemma 4.4). It has subsequently found wide use (e.g. by Roth and Roughgarden [74], Dwork, Naor, Pitassi, and Rothblum [26], and Hardt and Rothblum [44]). In our presentation of the technique, the proof of Theorem 3.23 is due to Salil Vadhan.
目录导航
第1章:https://blog.csdn.net/AdamCY888/article/details/146454841
第2章:https://blog.csdn.net/AdamCY888/article/details/146455093
第3章(1/3):https://blog.csdn.net/AdamCY888/article/details/146455756
第3章(2/3):https://blog.csdn.net/AdamCY888/article/details/146455796
第3章(3/3):https://blog.csdn.net/AdamCY888/article/details/146455328
第4章:https://blog.csdn.net/AdamCY888/article/details/146455882
第5章:https://blog.csdn.net/AdamCY888/article/details/146456100
第6章(1/2):https://blog.csdn.net/AdamCY888/article/details/146456712
第6章(2/2):https://blog.csdn.net/AdamCY888/article/details/146456972
第7章:https://blog.csdn.net/AdamCY888/article/details/146457037
第8章:https://blog.csdn.net/AdamCY888/article/details/146457172
第9章:https://blog.csdn.net/AdamCY888/article/details/146457257
第10章:https://blog.csdn.net/AdamCY888/article/details/146457331
第11章:https://blog.csdn.net/AdamCY888/article/details/146457418
第12章:https://blog.csdn.net/AdamCY888/article/details/146457489
第13章(含附录):https://blog.csdn.net/AdamCY888/article/details/146457601




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











