






Occlusion Aware Facial Expression Recognition Using CNN With Attention Mechanism
代码
https://github.com/mysee1989/PG-CNN
数据集
FED-RO
框架
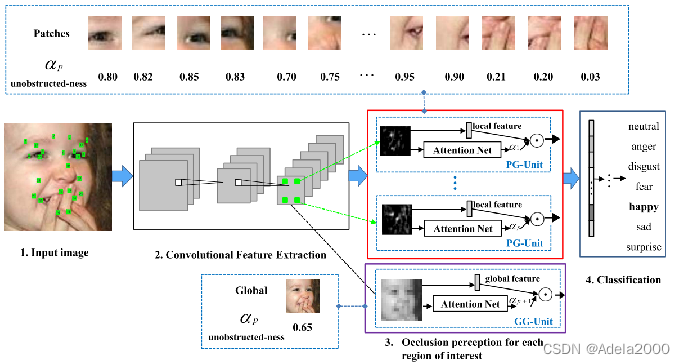
把图片中的眼睛等抠部分,经过注意力网络得到权重,和整体的权重相整合,进行分类。

抠出脸上部分的方式
Region Attention Networks for Pose and Occlusion Robust Facial Expression Recognition
代码
https://github.com/PeiwenSun2000/Region-Attention-Networks-for-Pose-and-Occlusion-Robust-Facial-Expression-Recognition
数据集
FER+
框架
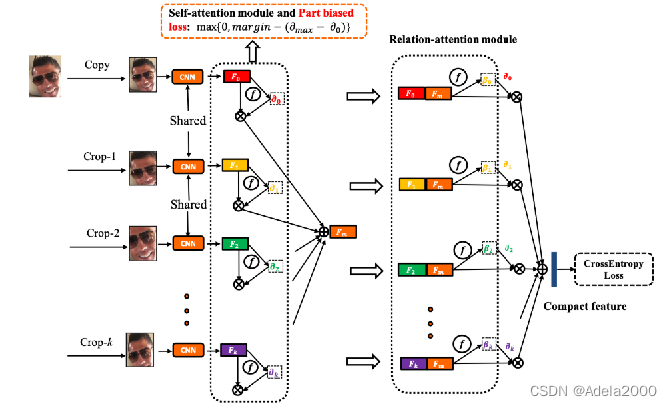
用不同的方式对原图进行裁剪,送入注意力机制中,先聚合,再通过关系注意力模块,再聚合,最后进行分类。
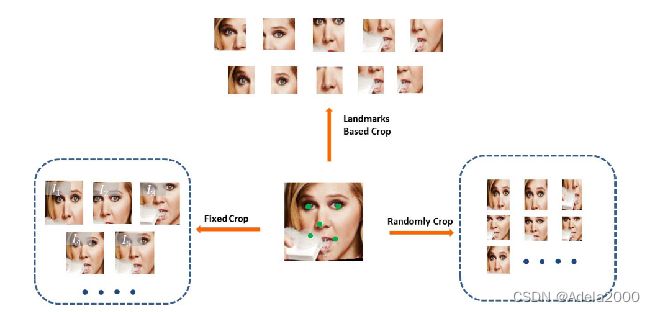
文中有三种进行裁剪的方式,固定位置裁剪、随机裁剪、基于地标的裁剪,根据实验固定位置裁剪表现最好。
Suppressing Uncertainties for Large-Scale Facial Expression Recognition
代码
https://github.com/PeiwenSun2000/Suppressing-Uncertainties-for-Large-Scale-Facial-Expression-Recognition
数据集
RAF-DB
框架
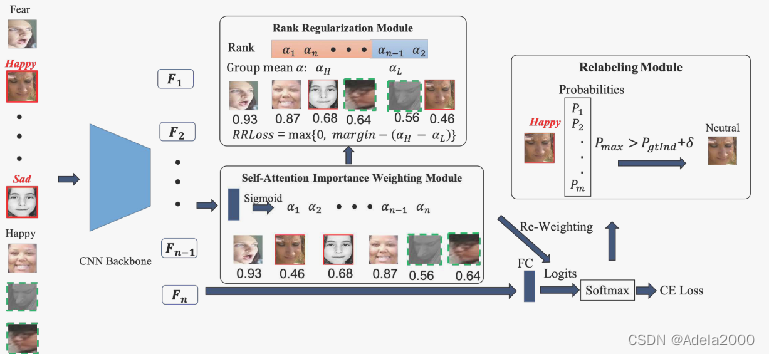
这篇论文考虑到数据集中的标注问题可能有不准确的情况。把训练集提取出特征后,送入注意力机制中,得到每张图片的权重,这里的权重我的理解是,该图片对产生的结果的重要性。然后将训练集进行分类,倘若分类结果和它本身的标注不一样则修改它的标注。
问题
下载了该论文的代码,但test的代码作者说有问题删掉了,所以我有个问题是该怎么用这个训练出来的模型预测我的结果。我疑惑的是,我的测试集使用这个模型有没有经过注意力机制,有没有重新标注。如果经过的话,测试集怎么会需要重新标准呢?
Deep multi-path convolutional neural network joint with salient region attention for facial expression recognition
代码
https://github.com/XsLangley/DAM-CNN
数据集
FER2013
框架
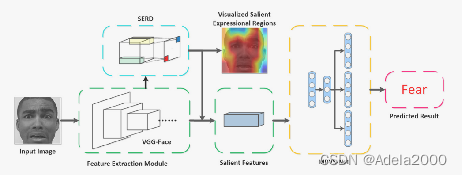
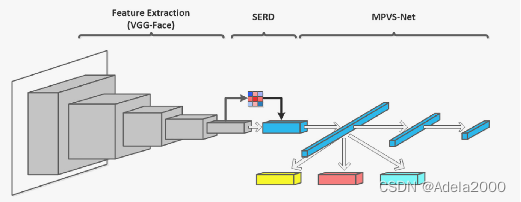
这篇文章是把图片经过注意力机制后,整张图片的每个部分拥有权重。作者认为相同的表情不同的人有不同的表现,所以用了多路径编码器,进行重构,再进行分类。
问题
看了代码和论文好几遍,没能懂多路径编码器是怎么对数据进行处理的,看代码当中进行训练的时候,就是数据依次进入多个编码器。















 1993
1993











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









