






一、神经网络
交叉熵函数

交叉熵(Cross Entropy)是信息论中的一个概念,用于衡量两个概率分布之间的差异。在机器学习和深度学习中,交叉熵经常用于损失函数,特别是在分类问题中,用于衡量模型预测的概率分布与真实标签的概率分布之间的差异。
性质
- 非负性:交叉熵损失函数的值始终非负。
- 零点:当模型的预测概率与真实标签完全一致时,交叉熵损失为0。
- 对称性:交叉熵不是对称的,即 H(P,Q)≠H(Q,P)。
为什么使用交叉熵
- 直观:交叉熵直观地衡量了模型预测的概率分布与真实分布之间的差异。
- 优化:在最大似然估计中,最小化交叉熵等价于最大化数据的似然概率。
- 梯度:交叉熵损失函数具有良好的梯度特性,便于使用梯度下降等优化算法。
与对数似然的关系
交叉熵损失函数实际上是对数似然损失函数的负数,它们是等价的。最小化交叉熵损失函数等同于最大化对数似然函数,这是统计模型中常用的一种方法。
梯度

在机器学习和深度学习中,梯度是一个非常重要的概念,它用于指导模型参数的优化。梯度是损失函数相对于模型参数的偏导数,它指示了损失函数在参数空间中增加或减少的方向和速率。
大模型中的梯度
对于大型模型,参数数量可能非常庞大,这使得梯度的计算和存储变得具有挑战性。以下是一些处理大型模型梯度的策略:
- 矩阵运算:利用矩阵运算来高效地计算梯度,减少计算量。
- 梯度累积:在计算资源有限的情况下,可以累积梯度,然后一次性更新参数。
- 参数服务器:在分布式训练中,使用参数服务器来存储和更新模型参数,以减少单个设备的存储压力。
- 模型并行:将模型的不同部分分布到不同的设备上,以利用更多的计算资源。
梯度的计算
在实际应用中,梯度的计算通常通过自动微分(Autograd)来实现。例如,在PyTorch中,模型的前向传播会自动构建计算图,反向传播(Backpropagation)时会自动计算梯度。
梯度爆炸和消失
在深度学习中,梯度爆炸和消失是常见的问题。梯度爆炸是指梯度的值变得非常大,导致参数更新不稳定。梯度消失是指梯度的值变得非常小,导致学习过程缓慢或停滞。这些问题通常通过合理的初始化、激活函数选择、学习率调整等策略来解决。
梯度的重要性
梯度是连接模型参数和损失函数的桥梁,是优化算法的基础。理解梯度的概念对于深入学习机器学习和深度学习至关重要。
总结
梯度是损失函数相对于模型参数的变化率,它指示了参数应该如何更新以最小化损失。在大型模型中,梯度的计算和处理需要特别的策略,以应对参数数量庞大的挑战。梯度下降等优化算法利用梯度来指导模型参数的更新,以达到优化目标。
WORD2VEC

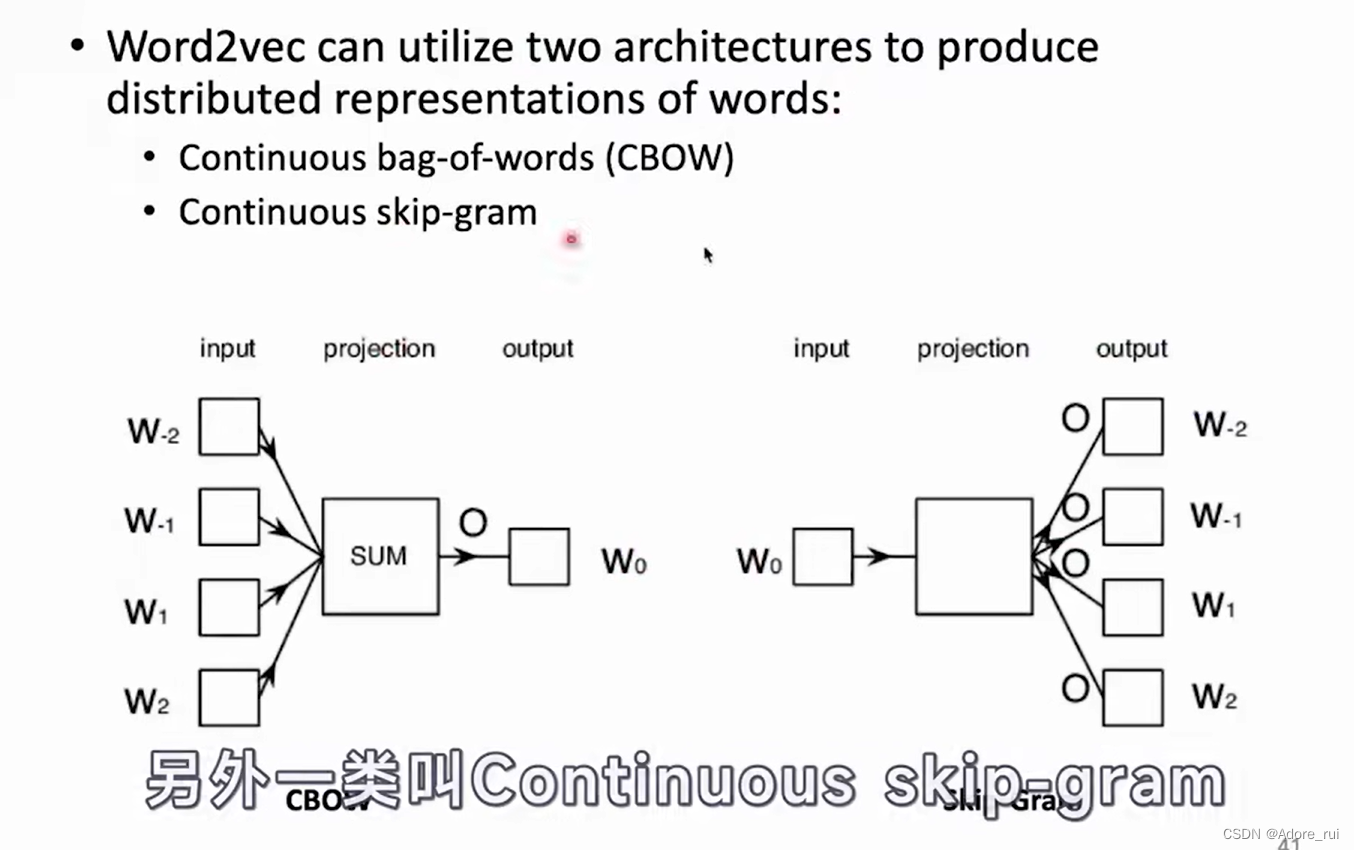
CBOW:根据context词去预测目标词。--图左
SKIP-GRAM:根据目标词去预测context词。 --图右
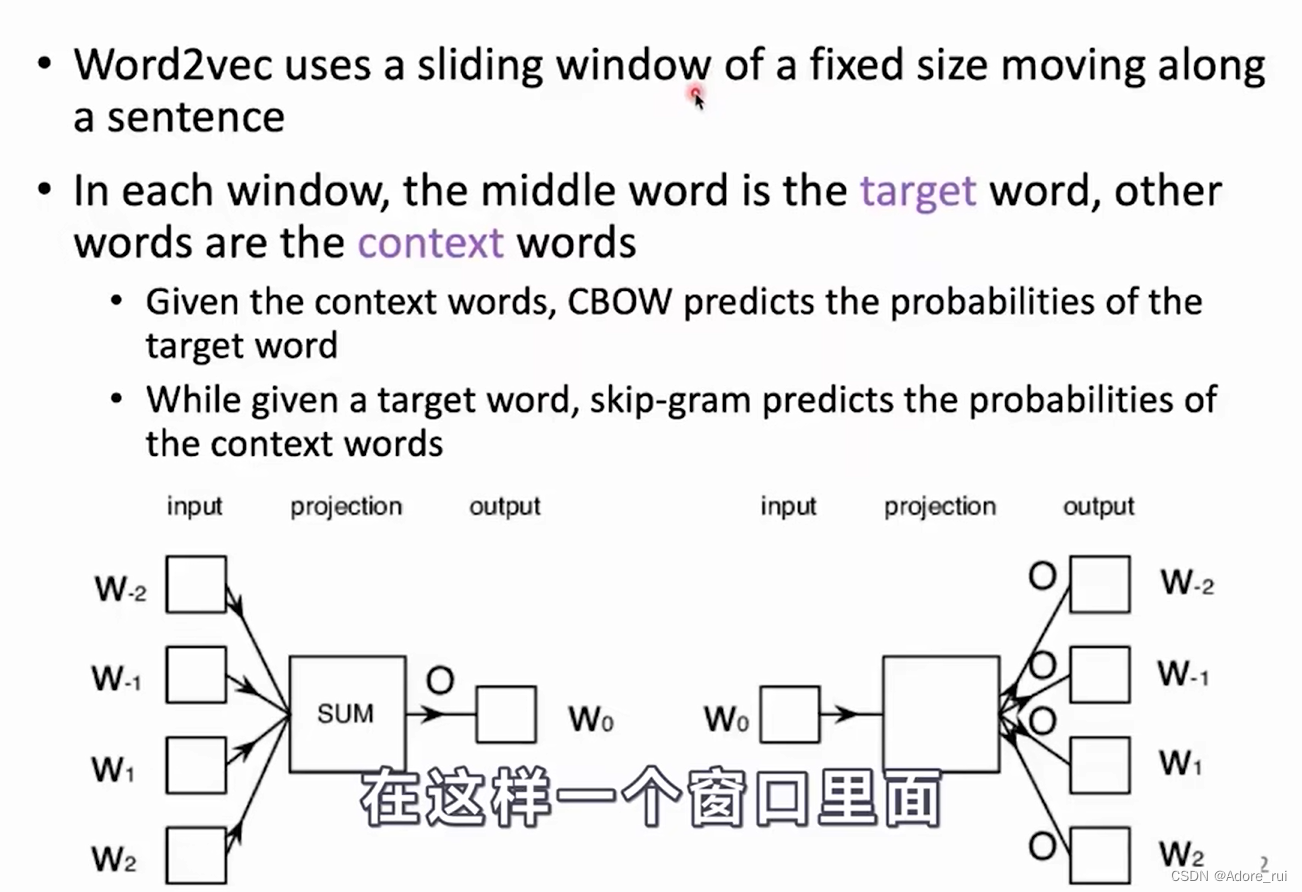
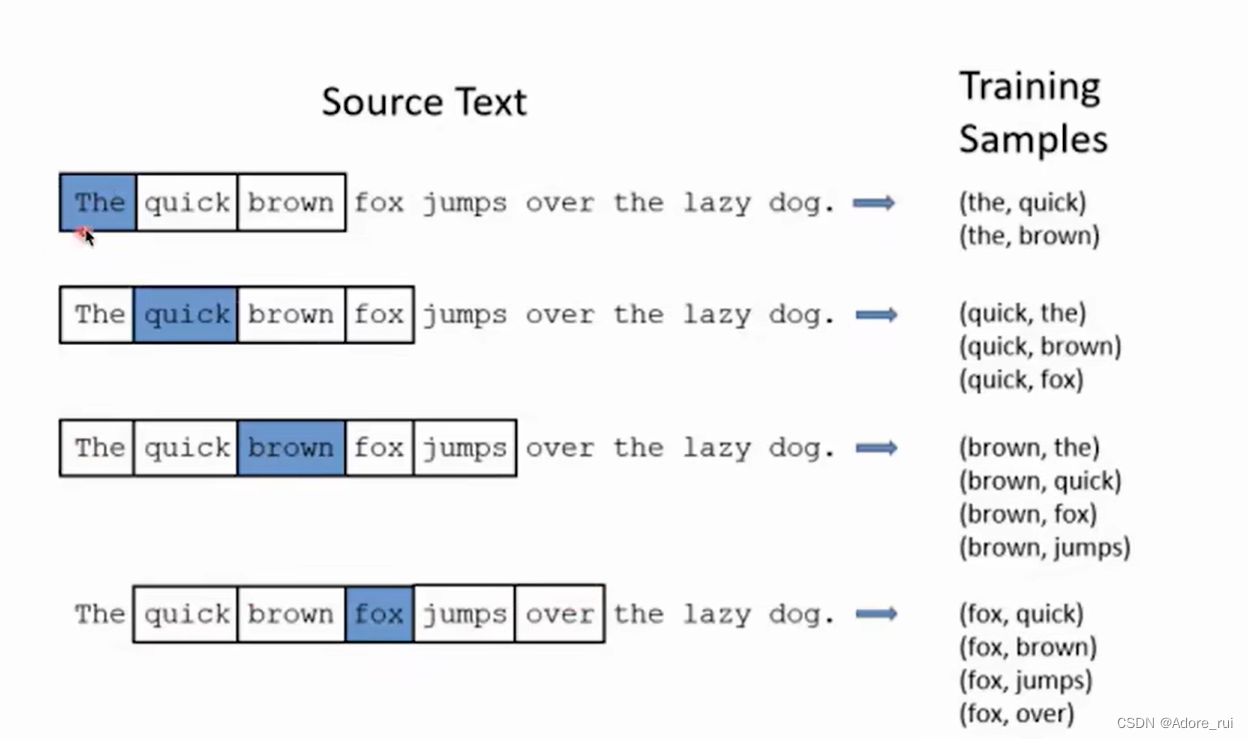
窗口滑动
 CBOW原理:
CBOW原理: 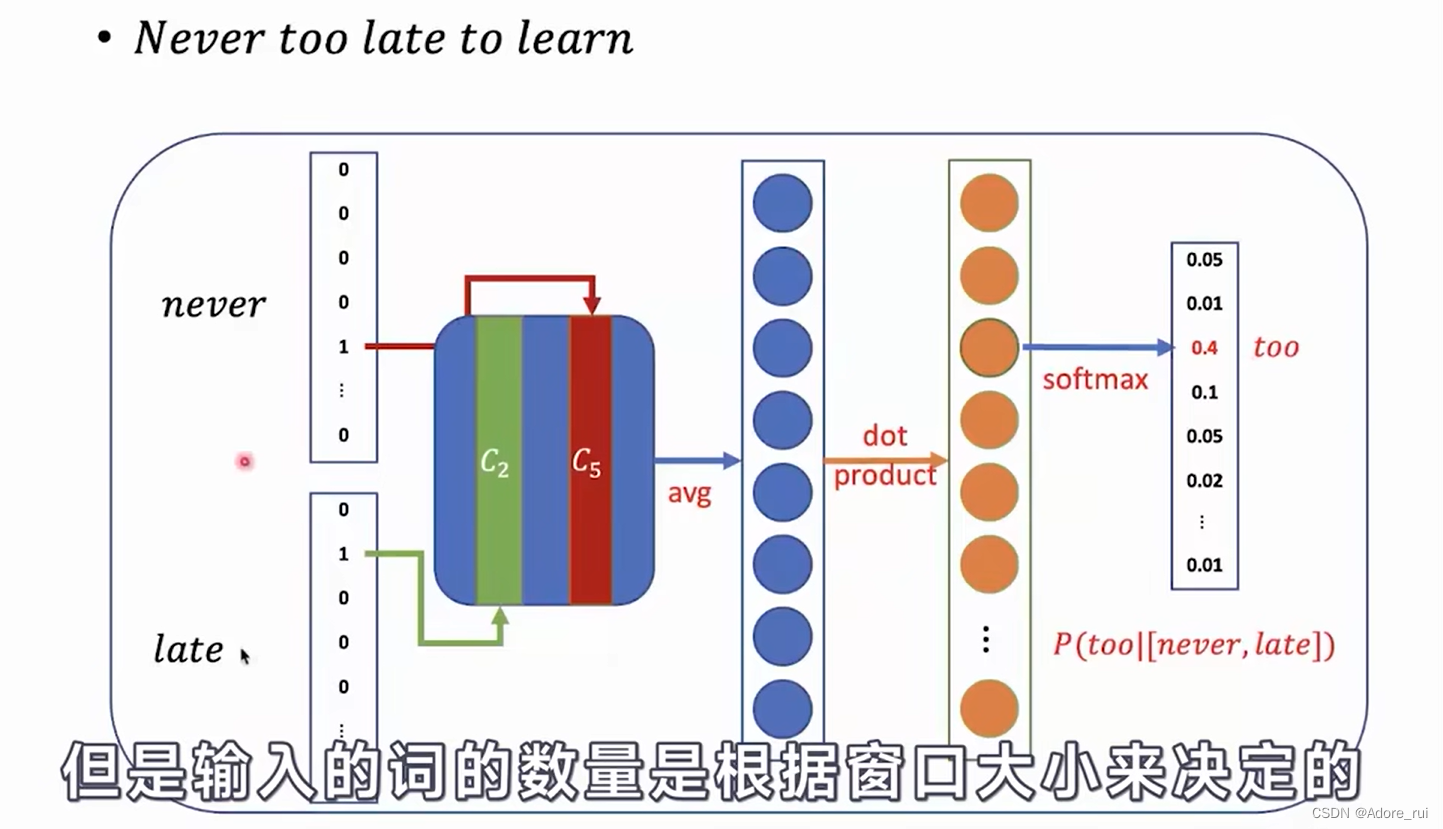
SOFTMAX
在机器学习和深度学习中,softmax层是一种常用于多分类问题的激活函数。它的作用是将神经网络输出的原始分数(logits)转换成概率分布,使得每个类别的概率值非负且总和为1。

特点
- 非负性:softmax函数的输出都是非负的。
- 归一化:softmax函数的输出是一个有效的概率分布,所有元素的和为1。
- 多分类:softmax通常用于多分类问题,可以处理两个以上的类别。
应用
softmax层通常位于神经网络的最后,将网络的输出转换为概率分布,以便用于分类任务。例如,在图像识别任务中,softmax层可以将网络的输出转换为每个类别的概率,选择概率最高的类别作为预测结果。
损失函数
softmax层通常与交叉熵损失函数一起使用。对于一个训练样本,真实标签可以用one-hot编码表示,softmax层的输出是每个类别的概率。交叉熵损失函数可以衡量预测概率分布与真实标签之间的差异,用于训练过程中的优化。
数学特性
softmax函数具有一些重要的数学特性:
- 单调性:当 zi 增加时,Softmax(zi) 也会增加。
- 可微性:softmax函数是连续可微的,这使得它适合于梯度下降等优化算法。
skip gram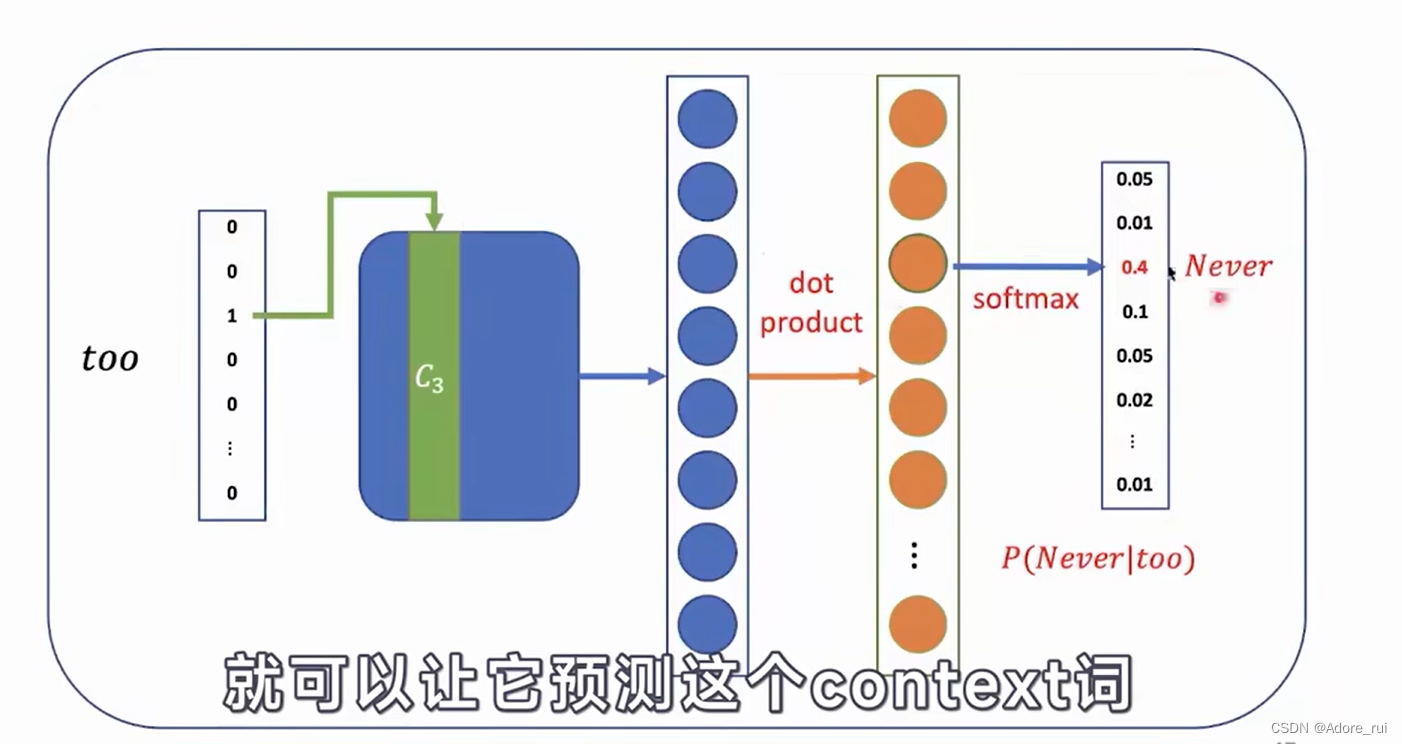

在深度学习领域,特别是在神经网络架构中,"L"、"N"和"H"通常指代以下概念:
-
L (层数): 表示神经网络中层的数量。每一层都可以看作是一个处理单元,它接收输入,通过某种变换(如矩阵乘法、激活函数等)产生输出,然后将这个输出传递给下一层。层数越多,网络的深度越深,理论上网络的学习能力越强,但同时也会面临过拟合和计算成本增加的风险。
-
N (注意力头数): 在注意力机制中,特别是在多头注意力机制(Multi-Head Attention)中,"N"表示注意力头的数量。多头注意力机制允许模型同时在不同的表示子空间中关注输入的不同部分,这样可以捕捉到更加丰富的信息。每个头可以独立地处理输入数据的一部分,并最终将这些处理结果合并,以获得一个综合的输出。
-
H (隐藏状态的大小): 通常指的是神经网络中隐藏层神经元的数量,或者在某些上下文中,它可能指的是隐藏层的维度大小。隐藏状态的大小直接影响到网络的容量和它能够捕捉的信息量。较大的隐藏状态可以提供更多的参数来学习复杂的模式,但也可能导致过拟合。
这些概念在设计和讨论神经网络模型时非常重要,尤其是在处理自然语言处理(NLP)、图像识别、语音识别等任务时。















 2724
2724

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









