







背景
cache和unpersist没有使用好,跟根本没用没啥区别,例如下面的例子,有可能很多人这样用:
val rdd1 = ... // 读取hdfs数据,加载成RDD
rdd1.cache
val rdd2 = rdd1.map(...)
val rdd3 = rdd1.filter(...)
rdd1.unpersist
rdd2.take(10).foreach(println)
rdd3.take(10).foreach(println)
上面代码的意图是:既然rdd1会被利用两次,那么就缓存起来,用完后释放内存。问题是,rdd1还没有被复用,就被“释放”了,导致rdd2,rdd3在执行take时,仍然需要从hdfs中加载rdd1,没有到达cache效果。
这就是很多人使用cache和unpersist的误区,以为cache没起作用,其实是自己使用的问题。
原理
这里要从RDD的操作谈起,RDD的操作分为两类:action和tranformation。
区别是tranformation输入RDD,输出RDD,且是缓释执行的;而action输入RDD,输出非RDD,且是即刻执行的。
上面的代码中,hdfs加载数据,map,filter都是transformation,take是action。所以当rdd1加载时,并没有被调用,直到take调用时,rdd1才会被真正的加载到内存。
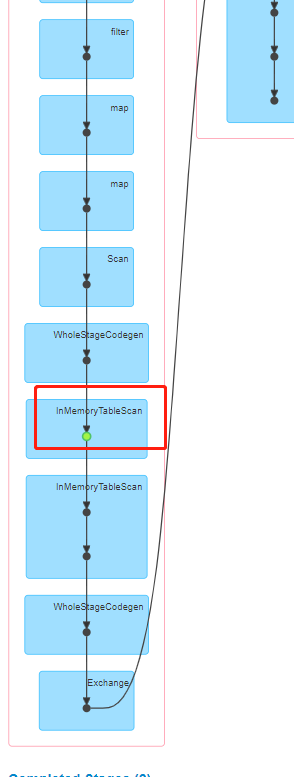
cache和unpersisit两个操作比较特殊,他们既不是action也不是transformation。cache会将标记需要缓存的rdd,真正缓存是在第一次被相关action调用后才缓存;unpersisit是抹掉该标记,并且立刻释放内存。
所以,综合上面两点,可以发现,在rdd2的take执行之前,rdd1,rdd2均不在内存,但是rdd1被标记和剔除标记,等于没有标记。所以当rdd2执行take时,虽然加载了rdd1,但是并不会缓存。然后,当rdd3执行take时,需要重新加载rdd1,导致rdd1.cache并没有达到应该有的作用。所以,正确的做法是将take提前到unpersist之前。
例子
失败案例
package com.wisers.spark.qc.cpc
import com.wisers.spark.utils.{DFUtil, IsNullUtil}
import org.apache.spark.sql.{DataFrame, RelationalGroupedDataset, SparkSession}
import org.apache.spark.sql.functions._
/**
* Created By TheBigBlue on 2020/8/6
* Description : 入文量统计和解析量统计:总的、pubcode级别的,listing级别的
*/
object EntryStatistics {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder()/*.master("local[6]")*/.appName("EntryStatistics").getOrCreate()
spark.sparkContext.setLogLevel("WARN")
val inputFile = if (args.size == 0) System.getProperty("user.dir") + "\\data\\input\\htmlparse\\*.data" else args(0)
) + "\\data\\output1" else args(1)
import spark.implicits._
//读文件、base64解码、解压缩、转json、获取属性
val inputDF = DFUtil.readAndDecomp(spark.sparkContext, inputFile)
.map(obj => {
val succFlag = if (IsNullUtil.isEmpty(obj.getString("data"))) 0 else 1
Data(obj.getString("pubcode"), obj.getString("listing"), succFlag)
}).toDF().cache()
//总入文量
val totalEntry = inputDF.agg(count("succFlag").alias("total"),
sum(when($"succFlag" === 1, 1).otherwise(0)).alias("succ"),
sum(when($"succFlag" === 0, 1).otherwise(0)).alias("err"))
//listing级别的入文量统计
val listingEntry = aggFunc(inputDF.groupBy("pubcode", "listing"), spark)
inputDF.unpersist()
DFUtil.saveAsExcel(totalEntry, outputFile, "入文量统计")
DFUtil.saveAsExcel(listingEntry, outputFile, "入文量listing级别统计")
spark.close()
}
def aggFunc(groupedDS: RelationalGroupedDataset, spark: SparkSession): DataFrame = {
import spark.implicits._
groupedDS.agg(count("succFlag").alias("总数量"),
sum(when($"succFlag" === 1, 1).otherwise(0)).alias("成功数量"),
sum(when($"succFlag" === 0, 1).otherwise(0)).alias("失败数量"))
.sort($"总数量".desc)
}
case class Data(pubcode: String, listing: String, succFlag: Int)
}


成功案例
package com.wisers.spark.qc.cpc
import com.wisers.spark.utils.{DFUtil, IsNullUtil}
import org.apache.spark.sql.{DataFrame, RelationalGroupedDataset, SparkSession}
import org.apache.spark.sql.functions._
/**
* Created By TheBigBlue on 2020/8/6
* Description : 入文量统计和解析量统计:总的、pubcode级别的,listing级别的
*/
object EntryStatistics {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder()/*.master("local[6]")*/.appName("EntryStatistics").getOrCreate()
spark.sparkContext.setLogLevel("WARN")
val inputFile = if (args.size == 0) System.getProperty("user.dir") + "\\data\\input\\htmlparse\\*.data" else args(0)
val outputFile = if (args.size == 0) System.getProperty("user.dir") + "\\data\\output1" else args(1)
import spark.implicits._
//读文件、base64解码、解压缩、转json、获取属性
val inputDF = DFUtil.readAndDecomp(spark.sparkContext, inputFile)
.map(obj => {
val succFlag = if (IsNullUtil.isEmpty(obj.getString("data"))) 0 else 1
Data(obj.getString("pubcode"), obj.getString("listing"), succFlag)
}).toDF().cache()
//总入文量
val totalEntry = inputDF.agg(count("succFlag").alias("total"),
sum(when($"succFlag" === 1, 1).otherwise(0)).alias("succ"),
sum(when($"succFlag" === 0, 1).otherwise(0)).alias("err"))
DFUtil.saveAsExcel(totalEntry, outputFile, "入文量统计")
//listing级别的入文量统计
val listingEntry = aggFunc(inputDF.groupBy("pubcode", "listing"), spark)
DFUtil.saveAsExcel(listingEntry, outputFile, "入文量listing级别统计")
inputDF.unpersist()
spark.close()
}
def aggFunc(groupedDS: RelationalGroupedDataset, spark: SparkSession): DataFrame = {
import spark.implicits._
groupedDS.agg(count("succFlag").alias("总数量"),
sum(when($"succFlag" === 1, 1).otherwise(0)).alias("成功数量"),
sum(when($"succFlag" === 0, 1).otherwise(0)).alias("失败数量"))
.sort($"总数量".desc)
}
case class Data(pubcode: String, listing: String, succFlag: Int)
}

















 5923
5923











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









