







向导
1. 部署新版本hadoop
- 在一个节点部署,并拷贝所有配置文件到新版本文件夹中
- 分发到各个节点
- 切换环境变量
2. 切换zkfc和journalnode(也可以不动这俩,因为会引起namenode down)
因为zkfc和journalnode不需要更新,所以直接将原服务停掉,启动新的zkfc和journalnode即可
3. 切换namenode
- 运行
hdfs dfsadmin -rollingUpgrade prepare以创建用于回滚的fsimage
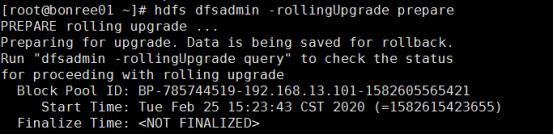
- 运行
hdfs dfsadmin -rollingUpgrade query以检查回滚映像的状态。等待并重新运行命令,直到显示Proceeding with Rolling Upgrade消息。
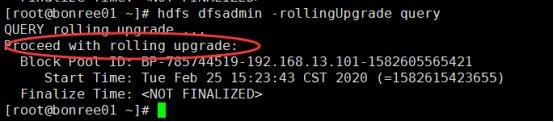
- 先升级standby的nn2,下掉namenode,hadoop-daemon.sh stop namenode
- 开始NN2 standby
-rollingUpgrade started选项。
hadoop-daemon.sh start namenode -rollingUpgrade started
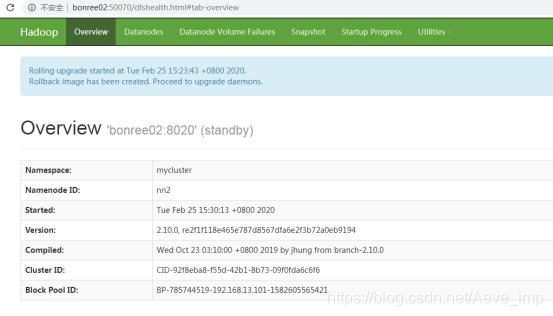
- 从NN1到NN2的故障转移,以便NN2变为active状态,而NN1变为standby状态。切换旧版active,使上一个新版的standby为active:
hadoop-daemon.sh stop namenode
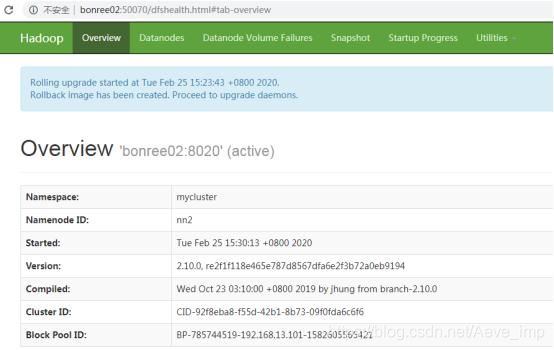
6.开始NN1与待机-rollingUpgrade开始 选项
hadoop-daemon.sh start namenode -rollingUpgrade started
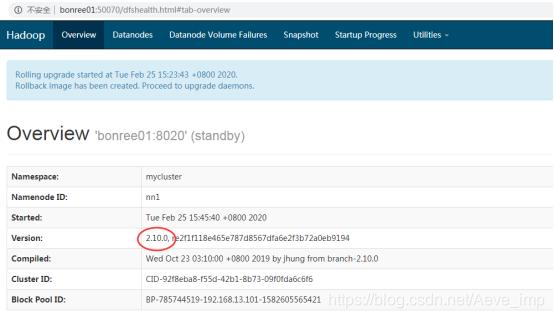
- 以上namenode进程升级为新版运行完毕,接下来滚动升级DN进程
4. 切换datanode
- 关闭旧版进程
hadoop-daemon.sh stop datanode - 启动新版进程
hadoop-daemon.sh start datanode - 重复上述步骤,直到升级群集中的所有数据节点
- 验证新版hadoop功能
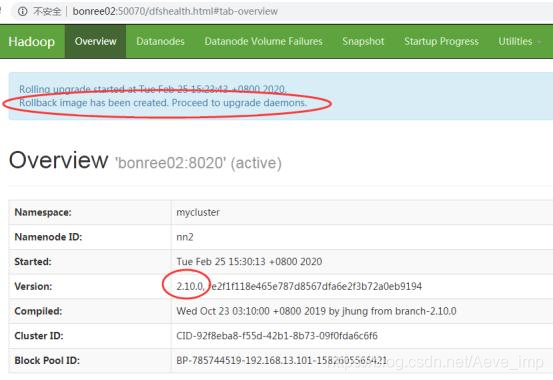
5. 切换yarn
直接挨个stop,挨个重启即可,没有数据需要交互
6. 提交完成滚动升级
若验证新版hadoop功能ok,则运行hdfs dfsadmin -rollingUpgrade finalize完成滚动升级。
hdfs dfsadmin -rollingUpgrade finalize















 1993
1993











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









