







 本文深入探讨HDFS的Upgrade Domain,解释其确保数据可用性和集群高效重启的原理。Upgrade Domain是对DataNode逻辑划分,保证在升级过程中副本分布在不同域,避免数据丢失。关键实现包括新的BlockPlacementPolicyWithUpgradeDomain策略,影响副本放置和多余副本选择。通过配置和脚本,可以实现升级域策略的启用和旧块的同步迁移。
本文深入探讨HDFS的Upgrade Domain,解释其确保数据可用性和集群高效重启的原理。Upgrade Domain是对DataNode逻辑划分,保证在升级过程中副本分布在不同域,避免数据丢失。关键实现包括新的BlockPlacementPolicyWithUpgradeDomain策略,影响副本放置和多余副本选择。通过配置和脚本,可以实现升级域策略的启用和旧块的同步迁移。
前言
在前面的文章HDFS的滚动升级: Rolling Upgrade中,介绍了HDFS滚动升级相关的内容。在HDFS滚动升级的过程中,会涉及到DataNode重启服务的操作。对于这里的DataNode服务重启的操作,其实是有一定讲究的。比如说,我们批量重启部分节点的时候,不能同时重启过多的节点,否则会造成部分块副本所在节点都处于正在重启的机器中,导致数据不可用的情况发生。如果我们想依然保证集群数据的可用性,可能想到的最简单的办法就是逐个重启。但是这又会有一个问题:如果集群规模达到1w个节点,假设集群每个DataNode重启服务大约花2~3分钟,那么重启一次集群估计要花1周的时间了。所以本文将要关注的一个主题是我们如何保证集群重启服务时同时保证高效性与数据可用性。对于此问题,HDFS引入了Upgrade Domain(升级域)的概念。在下文中,将会对此功能进行详细的介绍,包括它的概念的定义,核心原理以及部分关键代码的实现。
HDFS Upgrade Domain概念
HDFS Upgrade Domain本质上来理解指的是HDFS对各个同一个块的各个副本进行了逻辑上的划分,使之位于不同的域下。然后进行升级操作的时候,按照各个域依次进行重启服务即可。因为块的各个副本分别位于不同的域下,就不会存在数据不可用的情况了。升级域对副本块的逻辑划分效果如图1-1所示。
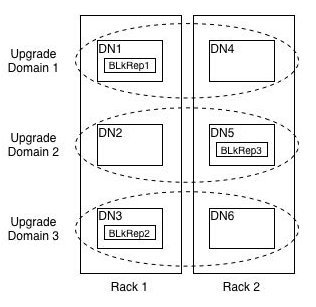
图 1-1 HDFS升级域
从图1-1中可以看出,升级域与机架类似,都是将DataNode进行划分的一个维度,唯一的不同点,是机架位置信息是物理上的,而升级域则表现在逻辑空间上的。DataNode所在机架我们可以用机架名称来表示,那么升级域我们用什么名称表示呢,答案如下:
HDFS节点的升级域可以采用指定升级域的方式,否则用DataNodeId作为当前DataNode的升级域(在这种情况下,每个DataNode的升级域都不相同)。
指定升级域的方式,可以写相应脚本进行获取,与机架感知时的获取脚本完全类似。节点->机架位置->升级域关系映射如图1-2所示。

图 1-2 DataNode节点映射关系
HDFS Upgrade Domain核心实现点
HDFS升级域的引入对于现有HDFS最为核心的影响是副本块的放置选择。因此在此功能中,我们将会引入一种新的副本放置策略:BlockPlacementPolicyWithUpgradeDomain。在此放置策略类中,我们将会多考虑到升级域的影响,保证块的各个副本位于不同的升级域下。
除了以上这个核心需要点外,我们还需要实现周边相关的操作。
第一点,每个块放置策略类会有自身的待删除多余副本的选择逻辑,同样在BlockPlacementPolicyWithUpgradeDomain类中,我们也需要对此进行实现。
第二点,Balancer数据平衡工具在移动块的时候,依然要遵循当前放置策略的原则。目前Balancer在数据平衡时保持的一个原则是保证各个机架内block的数量不变。这个原则表明了它更多的使用场合在于同一机架内的数据平衡。
HDFS Upgrade Domain关键代码实现
根据上节提到的关键实现点,在本节中我们对应核心代码的分析。首先,这里的主要逻辑都是实现在新的放置策略类BlockPlacementPolicyWithUpgradeDomain中的。在这里,我们要重载isGoodDatanode和pickupReplicaSet方法。
升级域放置策略下的放置位置选择
首先是isG
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1491
1491

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









