







](https://img-blog.csdnimg.cn/21dd41dce63a4f2da07b9d879ad0120b.png#pic_center)
🌈个人主页: Aileen_0v0
🔥热门专栏: 华为鸿蒙系统学习|计算机网络|数据结构与算法|MySQL|
💫个人格言:“没有罗马,那就自己创造罗马~”
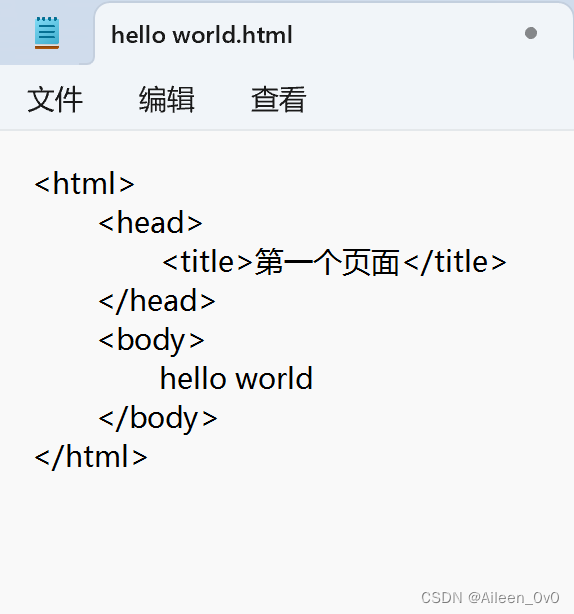
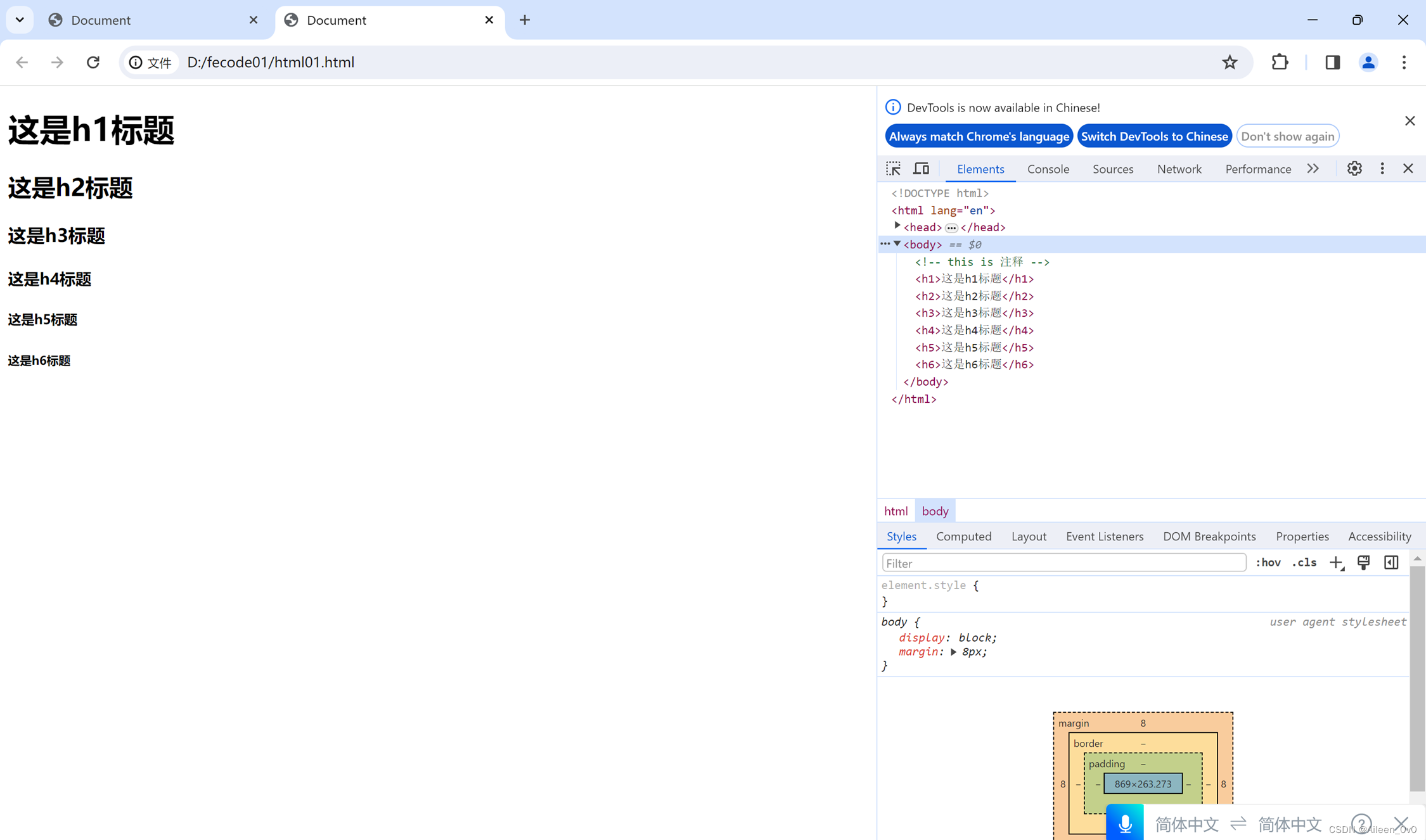
Html:html文件根标签
Head:编写页面相关的属性
Title:页面标题
Body:页面内容展示
Dom树
- 所有的标签都是html子标签
- Head和body是兄弟标签
- Head和title父子标签
每一个标签相当于一个对象,我们可以通过代码拿到这些对象,然后对这些对象进行增删查改.
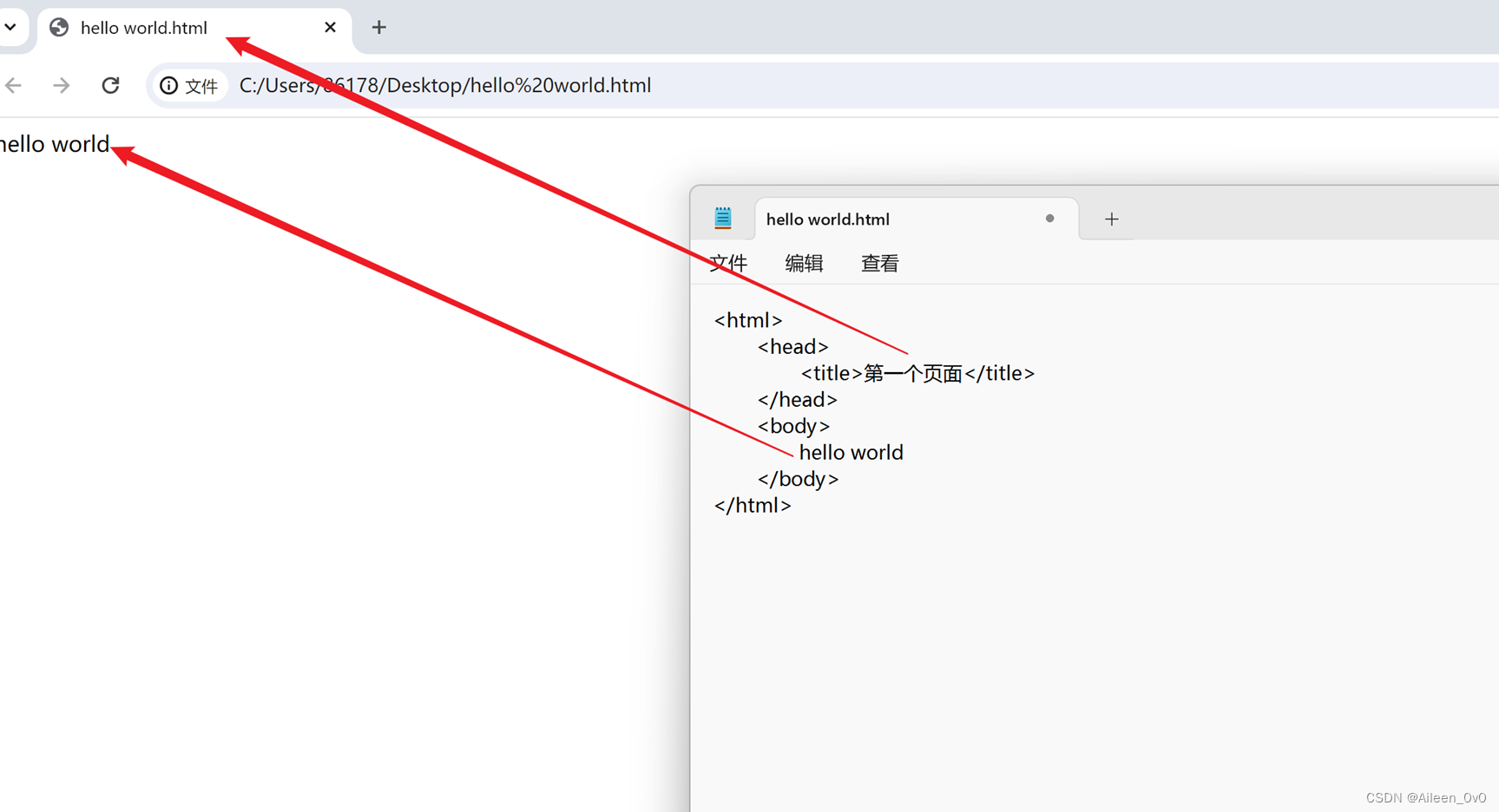
| 快速生成代码框架 Shift+!+Enter 生成代码框架的含义 |
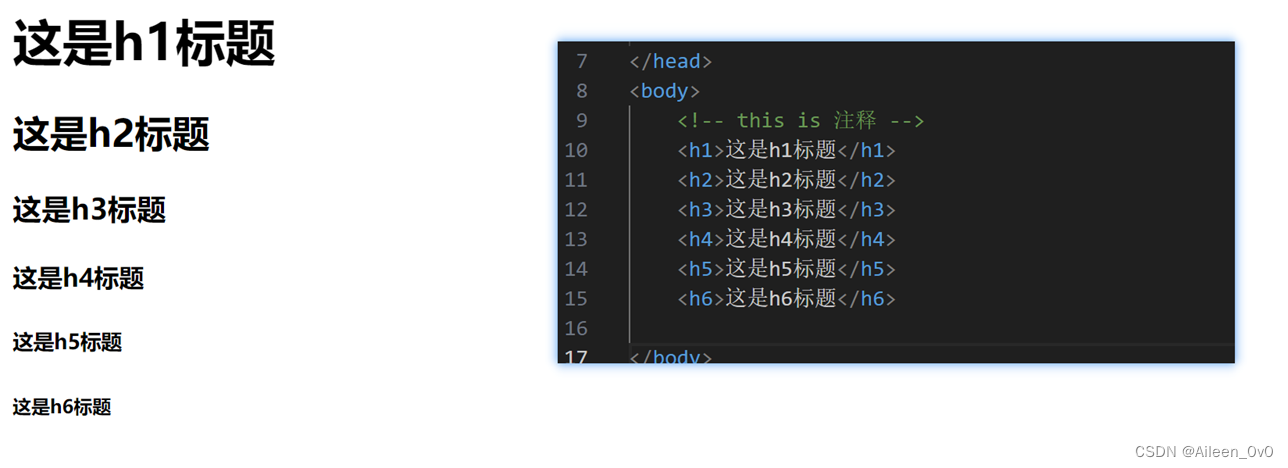
| 标题标签:h1-h6 有六个,从h1-h6,数字越大,则则字体越小. |
| 注释:ctrl+/ 我们可以通过快捷键:Fn + F12 查看到页面的源代码. |
段落标签:p是双标签
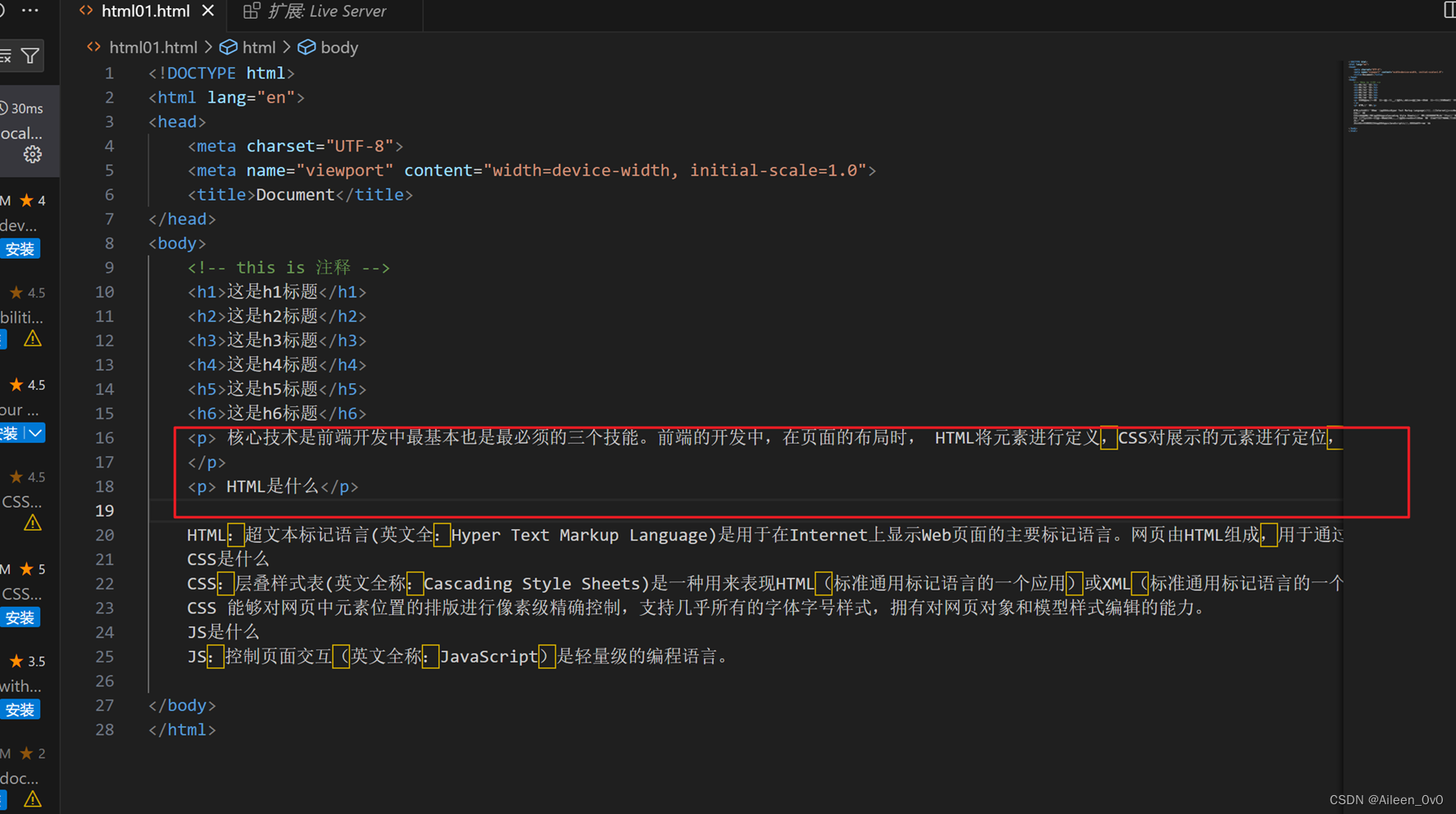

换行标签:br是单标签
- Br是break的缩写,表示换行.
- Br是一个单标签(不需要结束标签)
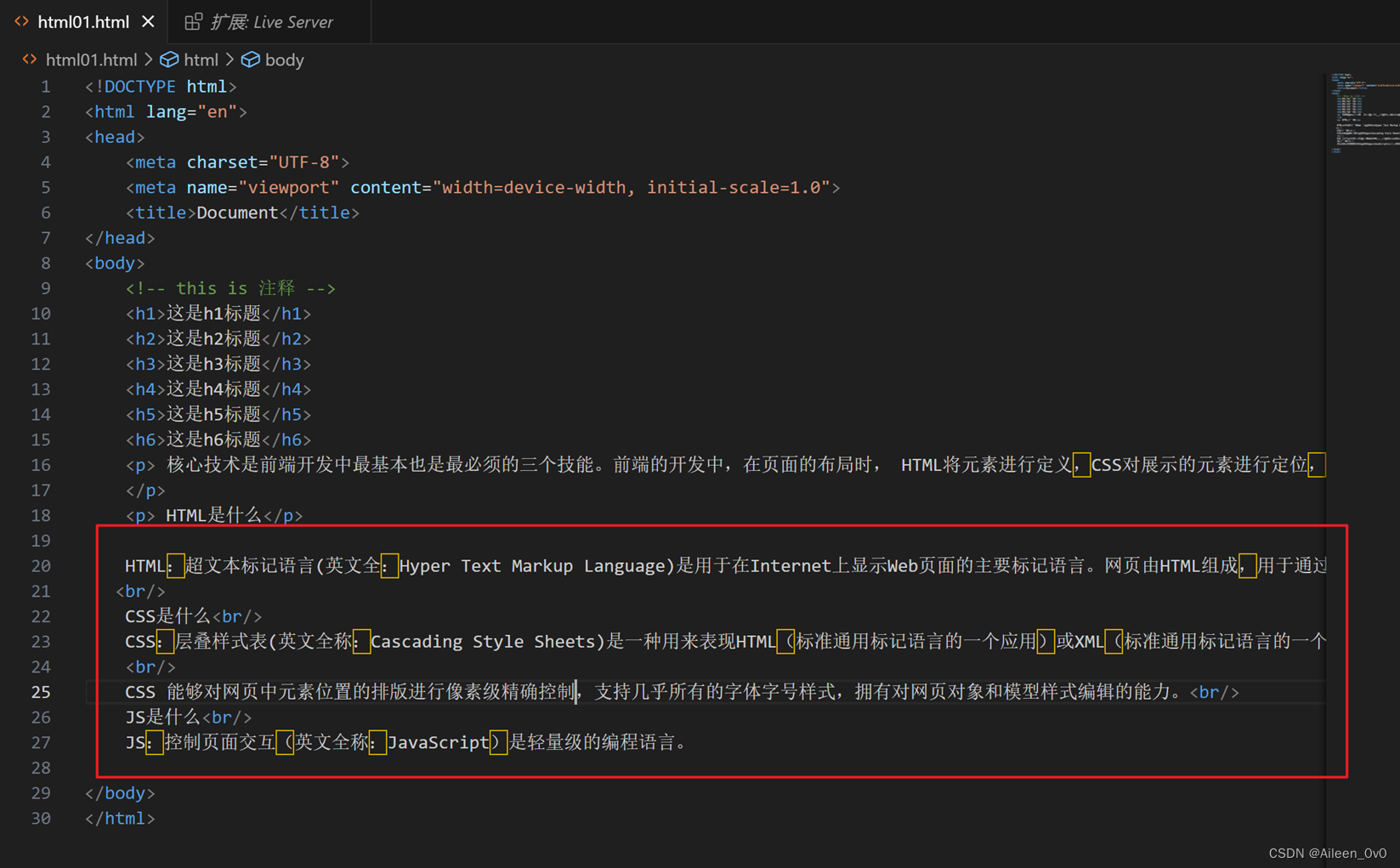

| 换行标签和段落标签的区别:换行标签换行后的间隙比段落标签小. |
格式化标签
- 加粗:strong标签 和 b标签
- 斜线:em 标签 和 I 标签
- 删除线:del 标签 和 s 标签
- 下划线:ins 标签 和 u 标签
Img标签
属性1:
| Src属性 Img标签必须搭配着src使用(指定图片路径) |
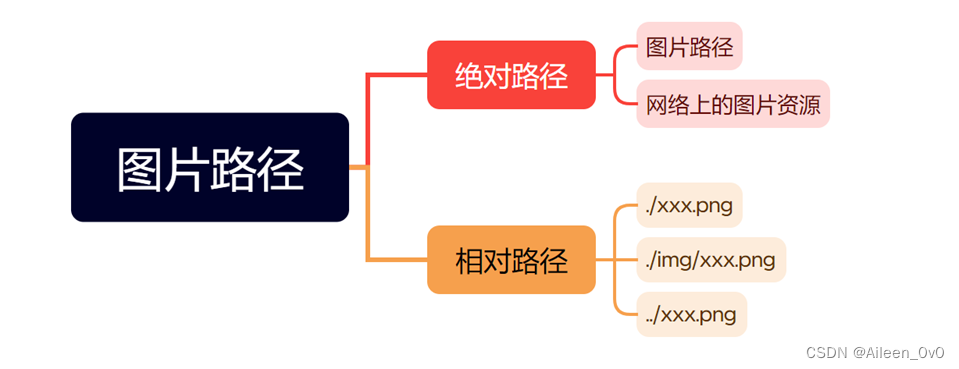
属性2
- alt:替换文本,当文本不能正确显示的时候,会显示一个替换的文字.(alt后面的文案,只有当图片加载出错的时候才会展示,如果图片加载成功,这个文案就不会展示)
- title:提示文本,鼠标放到图片上,就会有提示.
- width/height:控制宽度高度,宽度和高度一般改一个就行,另外一个会等比例缩放,否则就会图片失衡.
- border:边框,参数是宽度的像素.但一般使用 CSS 来设定.
a标签
herg属性
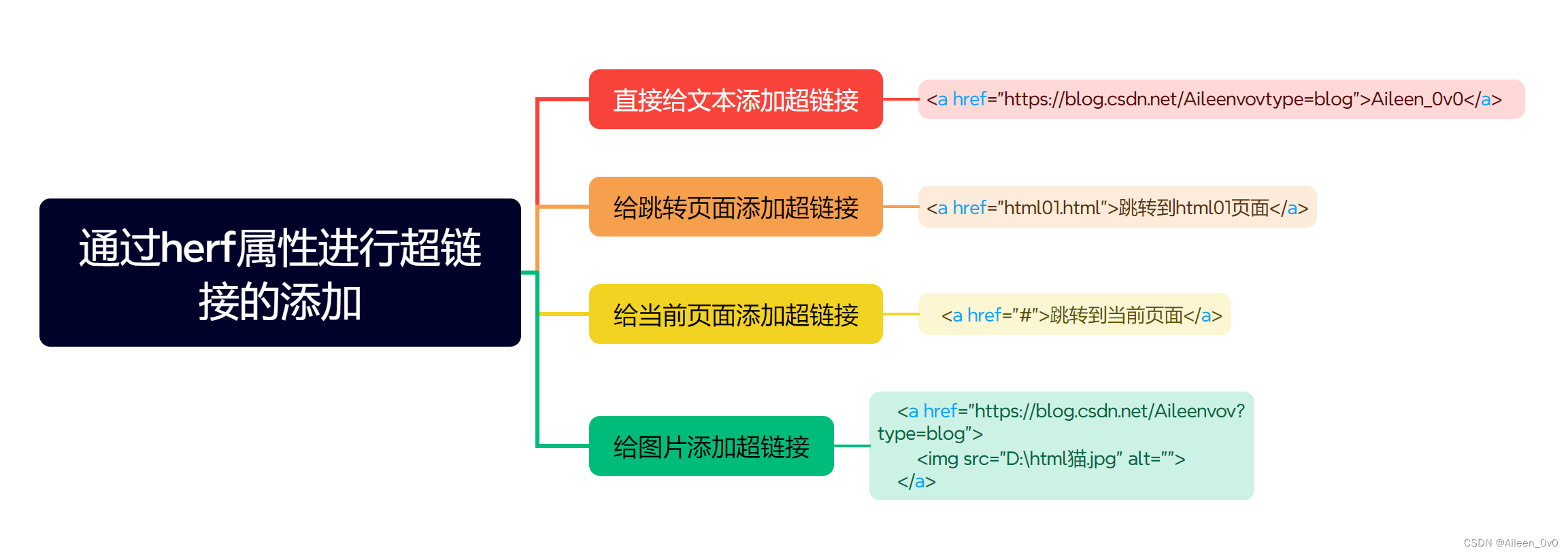
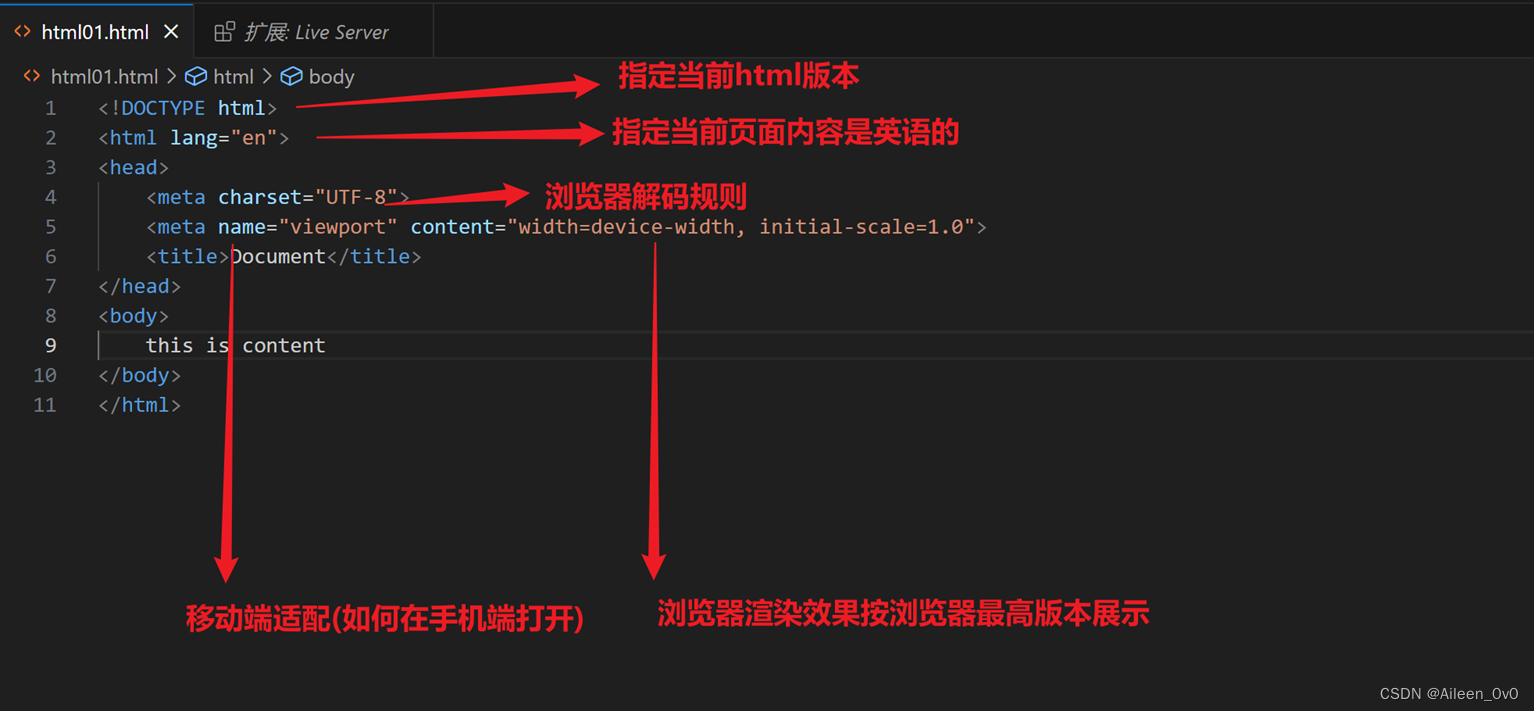
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
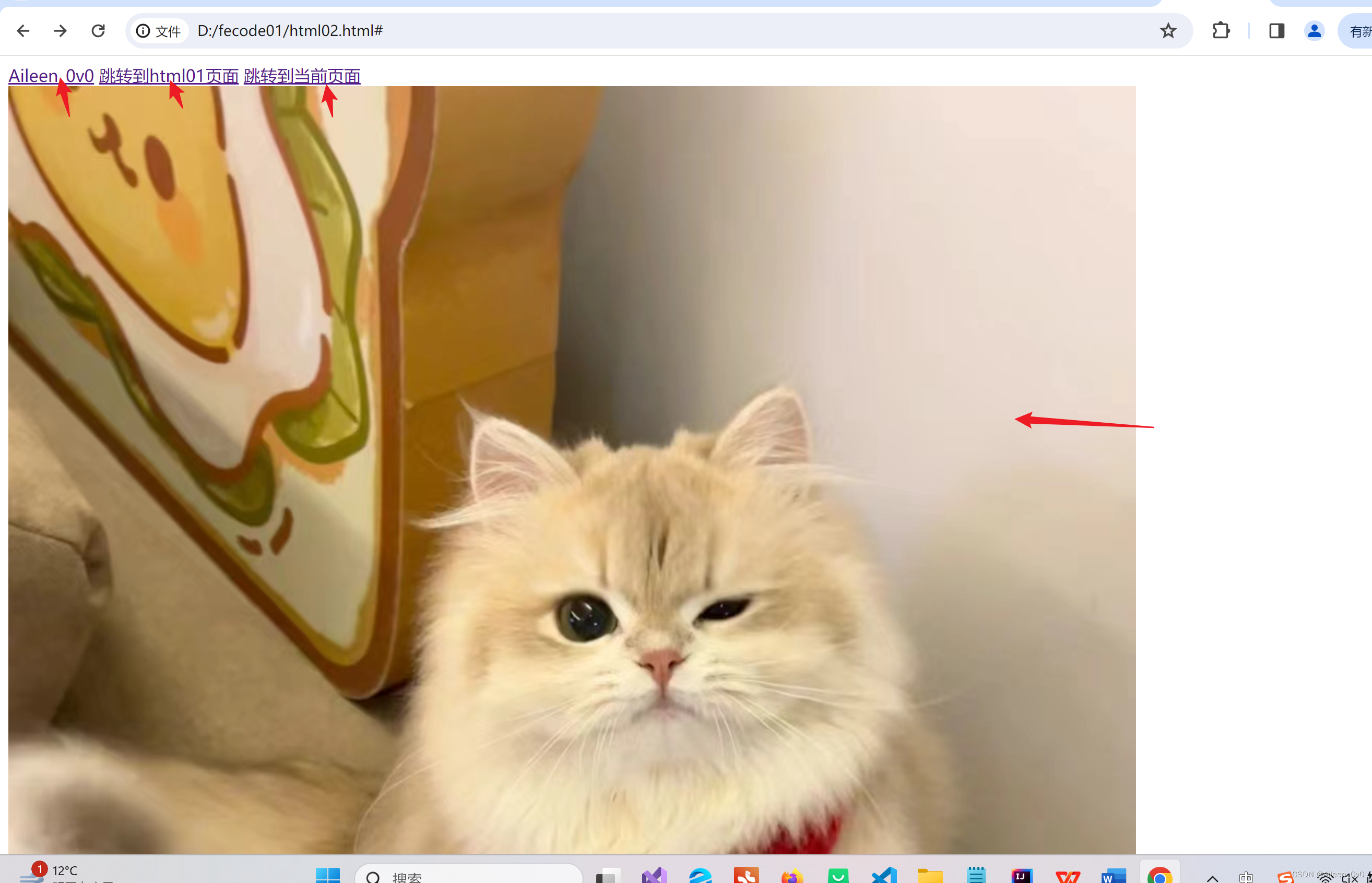
<a href="https://blog.csdn.net/Aileenvov?type=blog">Aileen_0v0</a>
<a href="html01.html">跳转到html01页面</a>
<a href="#">跳转到当前页面</a>
<a href="https://blog.csdn.net/Aileenvov?type=blog">
<img src="D:\html猫.jpg" alt="">
</a>
</body>
</html>
](https://img-blog.csdnimg.cn/0ee6c4ec414740b0a0404c5161cdadc7.gif#pic_center)
](https://img-blog.csdnimg.cn/cc002cbd5c414c5393e19c5e0a0dbf20.gif#pic_center#pic_center)
















 314
314











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











