







目录
2.2.3 Lambda表达式遍历(JDK1.8开始之后可用)
1.泛型
概述:泛型是一个标签:<数据类型>
泛型可以在编译阶段约束只能操作某种数据类型。
注意:JDK1.7开始之后,泛型后面的申明可以省略不写
泛型和集合都只支持引用数据类型,不支持基本数据类型。
例:
public class GenericityDemo {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
//jdk1.7之后不用写后面的泛型new ArrayList<>();
list.add("Java");
list.add("MySQl");
// list.add(false);
// list.add(99.9);
System.out.println(list);
}
}
1.1泛型的优点
1.泛型在编译阶段约束了操作的数据类型,从而不会出现类型转换异常。
2.体现的是Java的严谨性和规范性,数据类型经常需要进行统一。
1.2自定义泛型类
我们在之前使用泛型呢,都是别人写好给我们使用的,我们应该如何自定义自己的泛型类来使用。
泛型类的概念:使用了泛型的类。
泛型类的格式:
修饰符 class 类名<泛型变量>{
}
泛型变量建议使用E、T、K、V
例:
* 需求,模拟ArrayList自定义一个集合MyArrayList集合。
* 泛型类的核心思想:是把出现泛型的变量的地方全部替换成传输的真实数据类型。
public class GenericDemo {
public static void main(String[] args) {
MyArrayList<String> lists = new MyArrayList<>();
lists.add("java");
lists.add("mysql");
}
}
class MyArrayList<E>{
private ArrayList<E> list =new ArrayList();
public void add(E e){
list.add(e);
}
public void remove(E e){
list.remove(e);
}
@Override
public String toString() {
return list.toString();
}
}1.3自定义泛型方法
什么是泛型方法?
定义了泛型的泛型方法。
泛型方法的定义格式:
修饰符<泛型变量> 返回值类型 方法参数(形参){
}
注意:方法定义了是什么泛型变量,后面就用什么泛型变量。
泛型类的核心思想:是把泛型变量的地方全部替换成传输的真实数据类型。
public class GenericityDemo {
public static void main(String[] args) {
Integer[] nums ={10,20,30,40,50};
String string = arrToString(nums);
System.out.println(string);
}
//需求:给你任何一个类型的数组,都能返回它的内容。
public static <T> String arrToString(T[] nums){
StringBuilder sb = new StringBuilder();
sb.append("[");
if(nums!=null && nums.length > 0){
for(int i=0;i<nums.length;i++){
T ele=nums[i];
sb.append(i== nums.length-1?ele:ele+",");
}
}
sb.append("]");
return sb.toString();
}
}1.4自定义泛型接口
泛型接口的格式:
修饰符 interface 接口名称 <泛型变量>{
}
泛型接口的核心思想:在实现接口的时候传入真实的数据类型。
这样重写的方法就对该数据的操作。
例子:
package _12自定义泛型接口;
public class Student {
}
package _12自定义泛型接口;
public class StudentImpl implements Data<Student>{
@Override
public boolean add(Student student) {
return false;
}
@Override
public boolean delete(Student student) {
return false;
}
@Override
public boolean update(Student student) {
return false;
}
@Override
public Student query(int id) {
return null;
}
}
package _12自定义泛型接口;
public class Teacher {
}
package _12自定义泛型接口;
public class TeacherImpl implements Data<Teacher>{
@Override
public boolean add(Teacher student) {
return false;
}
@Override
public boolean delete(Teacher student) {
return false;
}
@Override
public boolean update(Teacher student) {
return false;
}
@Override
public Teacher query(int id) {
return null;
}
}
public class GenericDemo {
public static void main(String[] args) {
Data<Student> studentData = new StudentImpl();
studentData.add(new Student());
Data<Teacher> teacherData =new TeacherImpl();
teacherData.add(new Teacher());
}
1.5泛型的通配符
泛型的通配符是:?,就是什么类型都可以。
泛型的上限:
上限:? extends Car:也就是?的数据类型是继承了Car的类或者Car本身。
泛型的下限:?super Car:也就是?的数据类型是Car的父类或者Car本身。
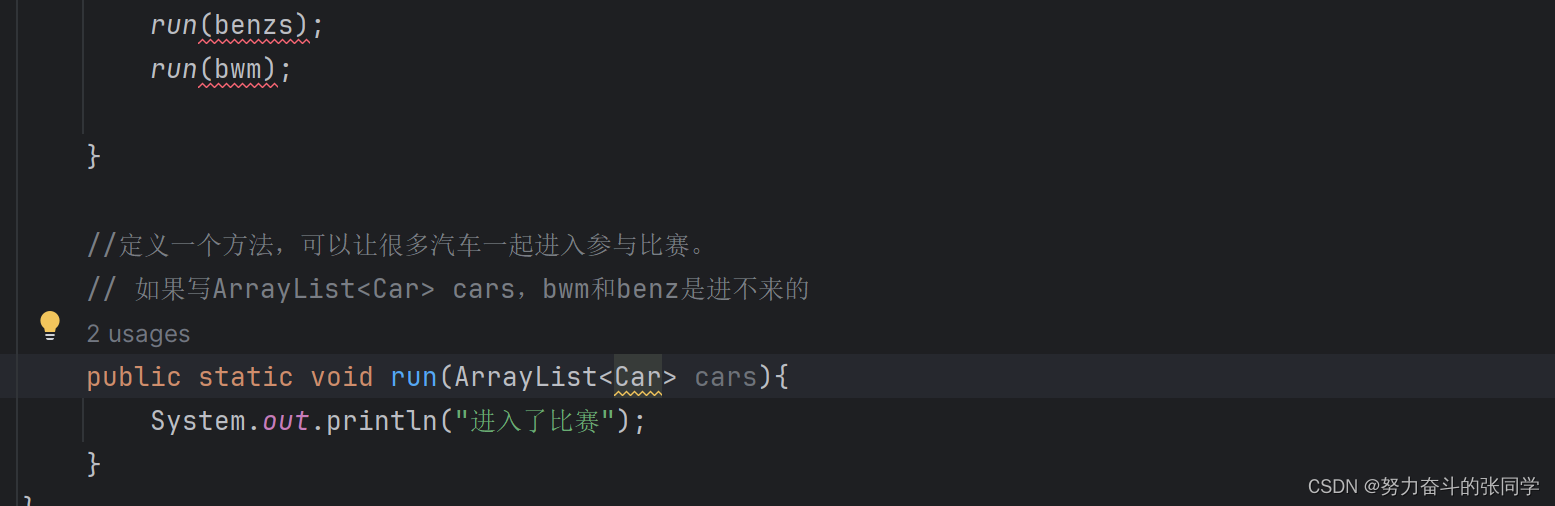
注意:泛型没有继承关系,也即是子类不可以直接填写由父类约束的类型,如下图:
public class GenericDemo {
public static void main(String[] args) {
ArrayList<BWM> bmws = new ArrayList<>();
bmws.add(new BWM());
bmws.add(new BWM());
bmws.add(new BWM());
ArrayList<BENZ> benzs= new ArrayList<>();
ArrayList<BWM> bwm = new ArrayList<>();
bwm.add(new BWM());
bwm.add(new BWM());
bwm.add(new BWM());
run(benzs);
run(bwm);
}
//定义一个方法,可以让很多汽车一起进入参与比赛。
// 如果写ArrayList<Car> cars,bwm和benz是进不来的
public static void run(ArrayList<? extends Car> cars){
System.out.println("进入了比赛");
}
}
class Car{
}
class BWM extends Car{
}
class BENZ extends Car{
}
2.Collection集合的概述
什么是集合?答:集合是一个大小可变的容器,集合中的每一个数据称为一个元素。
集合的特点:类型可以不确定,大小可以不固定,集合有很多种,不同的集合特点和使用场景不同。
与数组不同,数组的大小和类型是一般固定的。
集合有啥用?
在开发中,很多元素的个数是不确定的。
而且经常要进行元素的增删改查,集合是比较适合的。
Java中集合的代表是Collection.
Collection是Java集合中的祖宗类。
那么我们就可以知道,学习Collection集合的功能,那么一切集合都是通用的!!
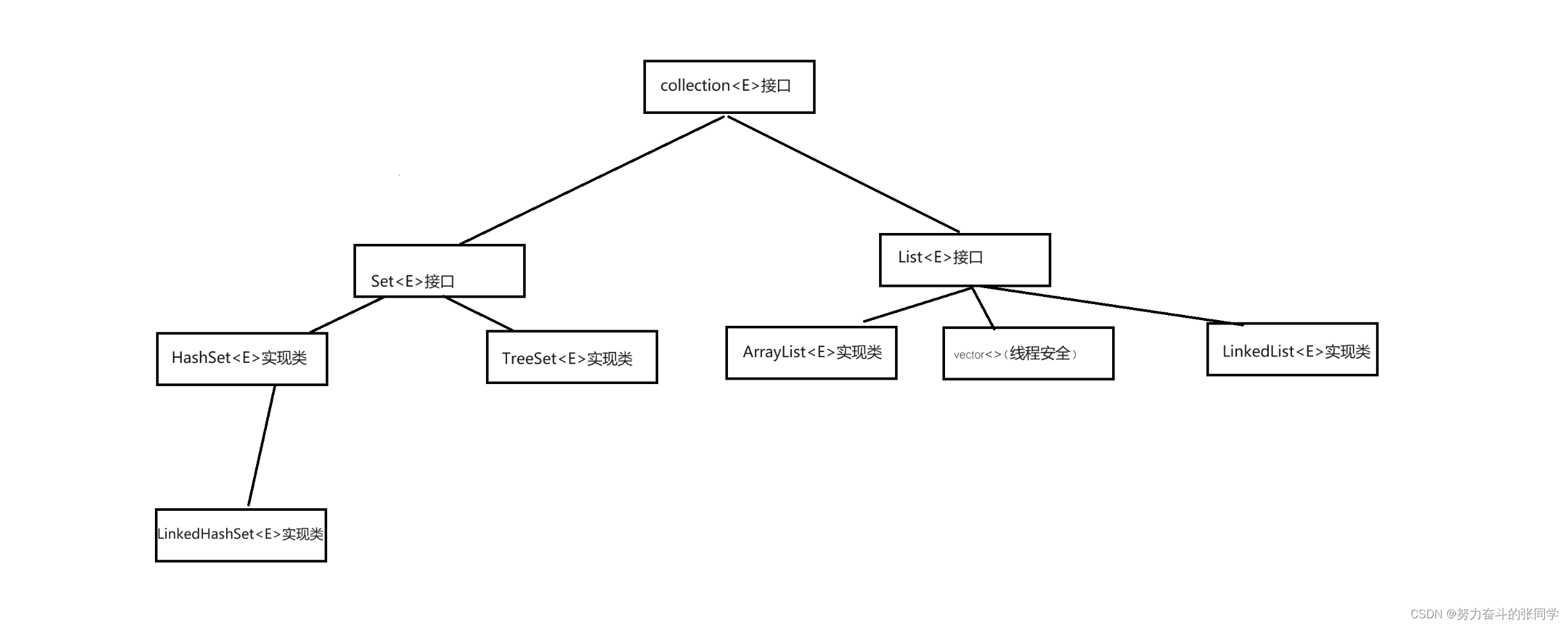
集合的特点:
Set系列集合,添加元素是无序不重复,无索引的。
--HashSet:添加的元素无序,不重复,无索引。
--LinkedHashSet:添加的元素是有序,不重复,无索引
--TreeSet:按照升序默认排序!!
List系列集合:添加的元素有序,可重复,有索引。
--ArrayList:添加的元素有序,可重复,有索引。
--LinkedList:添加的元素有序,可重复,有索引。
--vector:无需掌握,已经淘汰,从jdk1.0便存在了。
注意:Collection是集合的祖宗类,Collection集合的功能是一切集合可以使用的。
2.1 Collection集合的常用API
public boolean add(E e):把给定的对象添加到当前集合中。
public boolean remove(E e):把给定的对象从当前对象中删除。
public void clear():清空集合中所有的元素。
public boolean contains(Object obj):判断当前集合中是否包含给定的对象。
public boolean isEmpty():判空
public int size():集合元素个数。
扩展:
public boolean addAll(Object o):把集合o倒入当前集合。
public class CollectionDemo {
public static void main(String[] args) {
Collection<String> lists = new ArrayList<>();
System.out.println(lists.add("贾乃亮"));
System.out.println(lists.add("张三"));
System.out.println(lists.add("张三"));
System.out.println(lists.add("李四"));
System.out.println(lists);//集合已经重写了toString方法
//清空集合元素
// lists.clear();
// System.out.println(lists);
//判断集合是否为空
System.out.println(lists.isEmpty());
//判断集合个数
System.out.println(lists.size());
//删除某个元素,默认删除第一个。
System.out.println(lists.remove("张三"));
System.out.println(lists);
//把集合转换成数组
Object[] array = lists.toArray();
System.out.println(Arrays.toString(array));
}
}
2.2 Collection集合的遍历方法
2.2.1 迭代器遍历
public Iterator iterator():获取集合对应的迭代器,用来遍历集合中元素的。
E next():获取下一个迭代器。
boolean hasNext():判断是否有下一个元素,有返回true否则false.
public class CollectionDemo01 {
public static void main(String[] args) {
ArrayList<String> lists = new ArrayList<>();
lists.add("赵敏");
lists.add("张三");
lists.add("周芷若");
//1.迭代器遍历
Iterator<String> iterator = lists.iterator();
// System.out.println(iterator.next());
// System.out.println(iterator.next());
// System.out.println(iterator.next());
// System.out.println(iterator.next());//报错,没有此元素Exception in thread "main" java.util.NoSuchElementException
while(iterator.hasNext()){
System.out.println(iterator.next());
}
}
}
2.2.2 foreach集合遍历
public class CollectionDemo02 {
/*
*foreach遍历集合
* for(类型 变量名称:被遍历的数组或者集合)
* */
public static void main(String[] args) {
ArrayList<String> lists = new ArrayList<>();
lists.add("赵敏");
lists.add("赵四");
lists.add("张三");
for (String s : lists){
System.out.println(s);
}
}
}
2.2.3 Lambda表达式遍历(JDK1.8开始之后可用)
public class CollectionDemo03 {
public static void main(String[] args) {
ArrayList<String> lists = new ArrayList<>();
lists.add("张三");
lists.add("李四");
lists.add("王五");
System.out.println(lists);
lists.forEach(s->{
System.out.println(s);
});
}
}
3. List系列集合的使用
List集合继承了Collection集合的全部功能,同时因为List集合有索引,自己也重载了一些方法。
3.1 ArrayList集合
特点:基于顺序表(数组)实现,查询快,增删慢。
List集合多了个索引,所以多了许多按照索引操作数据的功能:
-public void add(int index,E element):将指定的元素。
-public E get(int index):返回集合中的指定位置的元素。
-public E remove(int index):移除指定位置的元素,并返回被删除元素的值。
-public E set(int index,E element):用指定元素替换指定的元素,返回的是更新后的值。
public class ListDemo01 {
public static void main(String[] args) {
//创建一个ArrayList集合对象,这是一行经典代码!!
ArrayList<String> lists = new ArrayList<>();
//在某个索引位置插入元素。
lists.add(0,"张三");
lists.add(1,"李四");
lists.add(2,"王五");
lists.add(3,"赵六");
//根据索引删除元素
lists.remove(0);
lists.forEach(s-> System.out.println(s));
//根据索引获取元素
System.out.println("-------");
System.out.println(lists.get(0));
//修改索引位置的元素
System.out.println("---------");
lists.set(0,"张三");
lists.forEach(s-> System.out.println(s));
}
}
注意:因为ArrayList集合有索引,所以我们也可以用for遍历
public class ListDemo02 {
public static void main(String[] args) {
ArrayList<String> lists = new ArrayList<>();
lists.add("java1");
lists.add("java2");
lists.add("java3");
lists.add("java4");
for(int i=0;i<lists.size();i++){
System.out.println(lists.get(i));
}
}
}3.2 LinkedList集合
LinkedList底层是基于链表,增删比较快,查询比较慢(这是相对而言比较慢 )
LinkedList是支持双链表的,定位前后的元素是非常快的,增删前后的元素也是最快的!!!
--public void addFirst():头插法。
--public void addLast():尾插法。
--public E getFirst():返回第一个元素。
--public E getLast():返回最后一个元素。
--public E removeFirst():头插法
--public E removeLast():尾删法
--public E pop():从此列表所表示的堆栈中弹出一个元素。
--public void push(E e):压栈。
注:可用来做栈或者队列。
public class ListDemo03 {
public static void main(String[] args) {
//用Linked做一个队列
LinkedList<String> strings = new LinkedList<>();
strings.addFirst("1");
strings.addFirst("2");
strings.addFirst("3");
System.out.println(strings.removeLast());
//栈
LinkedList<String> Stack = new LinkedList<>();
// Stack.addFirst("1");
// Stack.addFirst("2");
// Stack.addFirst("3");
// System.out.println(Stack.removeFirst());
Stack.push("1");
Stack.push("2");
Stack.push("3");
System.out.println(Stack.pop());
}
}4.Set系列集合的使用
特征:无序,不重复,无索引的。
public class HashSetDemo01 {
public static void main(String[] args) {
HashSet<String> sets = new HashSet<>();
sets.add("mysql");
sets.add("Java");
sets.add("mybatis");//与添加的顺序不一样。
sets.forEach(s-> System.out.println(s));
}
}面试重点:
Set集合为什么是无序的??
Set集合为什么是无重复的??是如何去重的??
4.1 Set集合去重的方式
1.对于基本值类型,Set集合可以直接判断进行去重。
2.对于引用数据类型的类对象,Set集合是按照如下流程进行的。
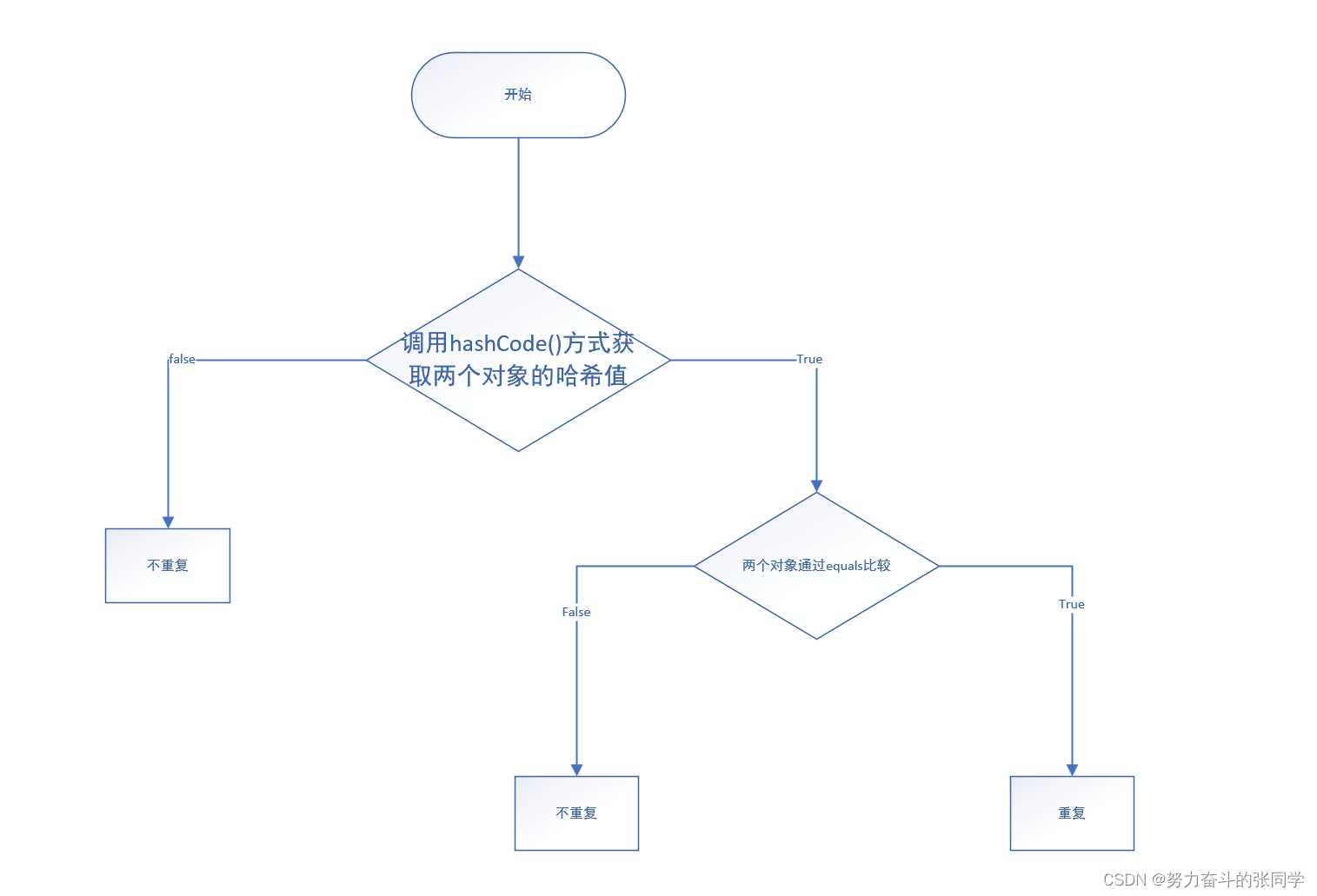
4.2 Set集合底层分析。
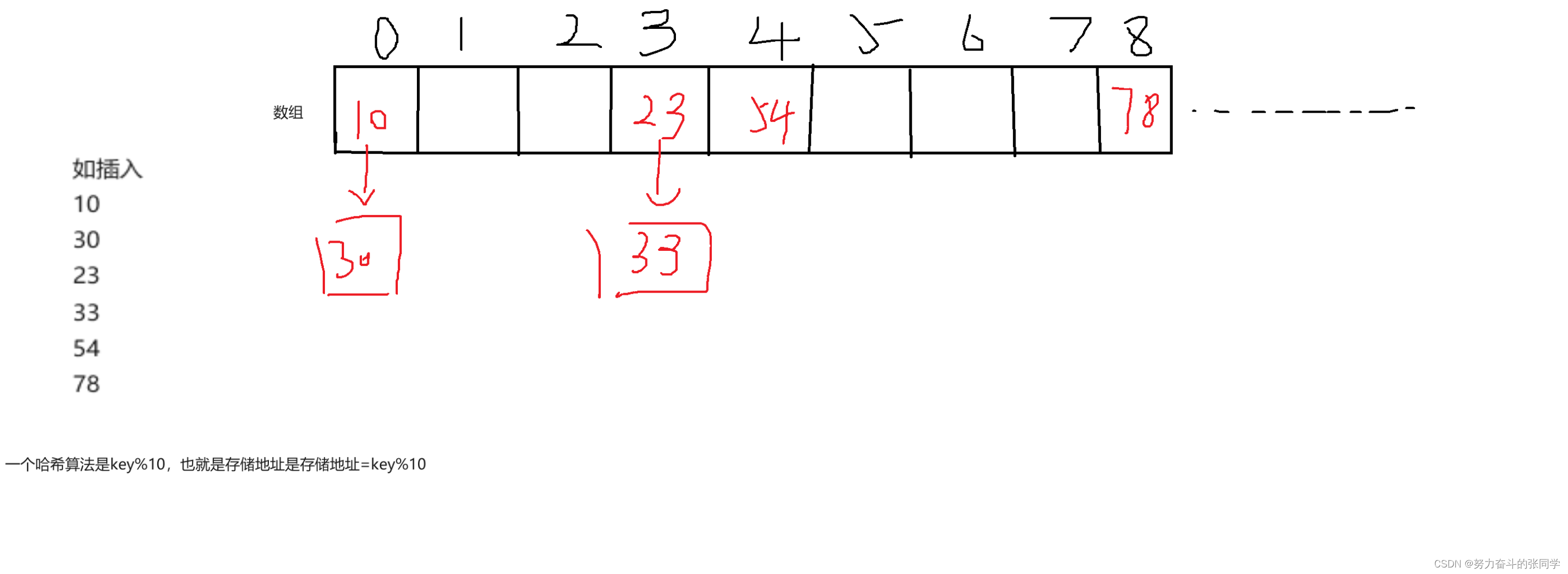
Set集合是基于哈希存储的。
它的增删改查的性能都很好!!,但是它是无序的不重复的。
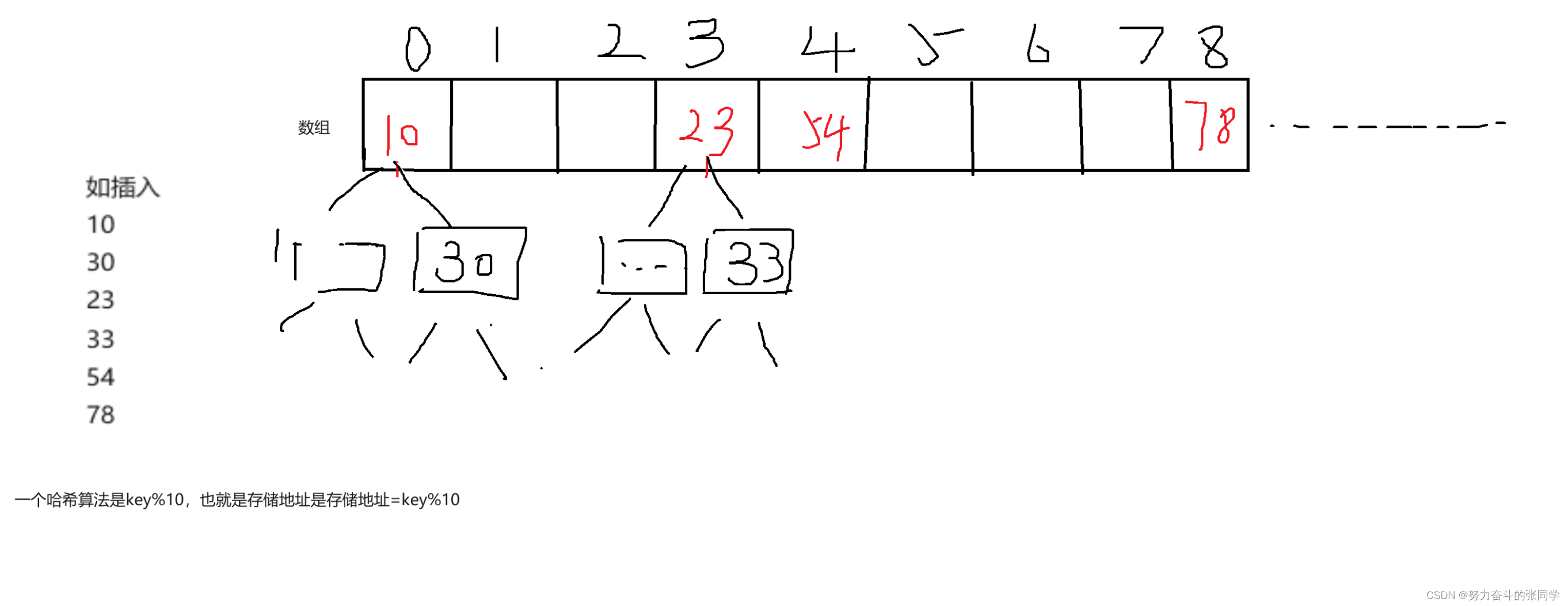
JDK1.8之前,哈希表 = 数组+链表+(哈希算法),如下图。
JDK1.8之后,哈希表=数组+链表+红黑树+(哈希算法),如下图。
4.3 LinkedHashSet集合
HashSet集合我们都知道,是无序的,上面的哈希表存储的方式我们就知道了,但是LinkedHashSet为什么又是有序的呢,其实LinkedHashSert也是哈希表存储,实现有序的方式就是每一个元素多一个值,用来记录下一个元素的地址,实质上是链表存储每一个元素。

4.4 TreeSet集合
排序不重复集合。
TreeSet集合:不重复,无索引,默认按照升序排列!!
TreeSet集合被称为排序不重复集合,可以对元素进行默认的升序排序。
排序规则:
- 数值类型:按照大小升序排序
- 字符串类型:按照首字母排序。
- 引用类型排序规则:对于自定义的引用规则,TreeSet默认规则无法排序,需要我们自己定制排序规则,有2重方式:
a.直接为对象的类实现comparable接口,重写比较方法.
b.直接在集合中设置比较器对象Comparator对象(优先级更高):
规则:
--当比较着大于被比较者,返回正数
--当比较着小于被比较者,返回负数
--当比较着等于被比较着,返回0
package _04Set系列集合;
import java.util.Objects;
public class Student implements Comparable<Student> {
private String name;
/*
* TreeSet集合想要对引用类型排序,那么必须重写comparableTo方法。
*
* 比较着:this
* 被比较者:o
* 需求:按照年龄比较
* */
@Override
public int compareTo(Student o) {
//规则:如果程序员认为比较着大于被比较者,返回正数!
//如果程序员认为比较着小于被比较者,返回负数!
//如果程序员认为比较者等于被比较者,返回0!
return this.age - o.age;
}
private int age;
public Student(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return age == student.age && Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
public class TreeSetDemo05 {
public static void main(String[] args) {
TreeSet<Integer> scores = new TreeSet<>();
scores.add(1);
scores.add(4);
scores.add(3);
scores.add(2);
System.out.println(scores);
//如果是字符串,按照首字母编号排序。
TreeSet<String> str = new TreeSet<>();
str.add("apple");
str.add("orange");
str.add("max");
str.add("min");
str.add("c");
System.out.println(str);
//a.引用数据类型定义TreeSet集合,报错,因为不知道怎么拍徐,默认无法排序。报错:Exception in thread "main" java.lang.ClassCastException: _04Set系列集合.Student cannot be cast to java.lang.Comparable
TreeSet<Student> stu = new TreeSet<>();
stu.add(new Student("张三", 18));
stu.add(new Student("李四", 16));
stu.add(new Student("王五", 20));
stu.add(new Student("赵六", 30));
System.out.println(stu);
//b.直接为集合自定义比较规则。这个的优先级比类的高。
TreeSet<Student> stu2 = new TreeSet<>(new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
return o1.getAge()-o2.getAge();
}
});
stu.add(new Student("张三", 18));
stu.add(new Student("李四", 16));
stu.add(new Student("王五", 20));
stu.add(new Student("赵六", 30));
System.out.println(stu);
}
}
4.5集合总结
1.如果希望元素可以重复,有索引,查询要快用ArrayList集合。
2.如果希望元素可以重复,又有索引,增删快用LinkedList集合。
3.如果希望增删改查都很快,但是元素不重复以及无序列无索引,那么用HashSet集合。
4.如果希望增删改查都很快且有序,但是元素不重复无索引,那么用LinkedHashSet集合。















 741
741











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











