







条款18 让接口容易被正确使用,不易被误用
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
class Date
{ public: Date( int month, int day, int year); ... }; //因为month和day以及year,容易输入错误,我们会限定客户的输入 class Month { public: static Month Jan() { return Month( 1); //函数,返回有效月份 } static Month Feb() { return Month( 2); //这些是函数而非对象 } ... static Month Dec() { return Month( 12); } private: explicit Month( int m); //阻止生成新的鱼粉,这是月份专属数据。 }; //我们可以这样调用 Date d(Month::Mar(), Day( 30), Year( 1995)); |
|
1
|
Investment* createInvestment();
|
|
1
2 3 4 |
std::tr1::shared_ptr<Investment> createInvestment()
{ return std::tr1::shared_ptr<Investment>( new Stock); } |
返回的 tr1::shared_ptr 能在 DLL 之间进行传递,而不必关心 cross-DLL 问题。指向这个 Stock 的tr1::shared_ptr 将保持对“当这个 Stock 的引用计数变为零的时候,哪一个 DLL 的 delete 应该被使用”的跟踪。
这个 Item 不是关于 tr1::shared_ptr 的——而是关于使接口易于正确使用,而难以错误使用的——但tr1::shared_ptr 正是这样一个消除某些客户错误的简单方法,值得用一个概述来看看使用它的代价。最通用的tr1::shared_ptr 实现来自于 Boost(参见 Item 55)。Boost 的 shared_ptr 的大小是裸指针的两倍,将动态分配内存用于簿记和 deleter 专用(deleter-specific)数据,当调用它的 deleter 时使用一个虚函数来调用,在一个它认为是多线程的应用程序中,当引用计数被改变,会导致线程同步开销。(你可以通过定义一个预处理符号来使多线程支持失效。)在缺点方面,它比一个裸指针大,比一个裸指针慢,而且要使用辅助的动态内存。在许多应用程序中,这些附加的运行时开销并不显著,而对客户错误的减少却是每一个人都看得见的。
Things to Remember
- 好的接口易于正确使用,而难以错误使用。你应该在你的所有接口中为这个特性努力。
- 使易于正确使用的方法包括在接口和行为兼容性上与内建类型保持一致。
- 预防错误的方法包括创建新的类型,限定类型的操作,约束对象的值,以及消除客户的资源管理职责。
- tr1::shared_ptr 支持自定义 deleter。这可以防止 cross-DLL 问题,能用于自动解锁互斥体(参见 Item 14)等。
条款19 设计class犹如设计type
条款20 宁可pass-by-reference-to-const 替换pass-by-value
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 |
// refer_value.cpp : 定义控制台应用程序的入口点。 #include <iostream> using namespace std; class Base { public: Base() { cout << "Base()" << endl; } Base( const Base &rhs) { cout << "Base copy" << endl; } ~Base() { cout << "~Base()" << endl; } private: string str1; string str2; }; class Derived: public Base { public: Derived() { cout << "Derived()" << endl; } Derived( const Derived &rhs): Base(rhs) { cout << "Derived copy" << endl; } ~Derived() { cout << "~Derived()" << endl; } bool retTrue() const { return true; } private: string str1; string str2; }; bool validateDerived( const Derived d) //传值 { return d.retTrue(); } void test() { Derived d; //派生类 bool bb = validateDerived(d); //pass by value } int main() { test(); system( "pause"); return 0; } |
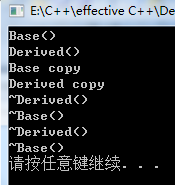
|
1
2 3 4 5 6 7 8 9 10 |
bool validateDerived( const Derived &d) //传引值 { return d.retTrue(); } |
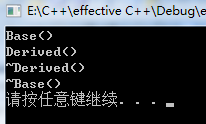
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
#include <iostream>
using namespace std; class Window //基类 { public : Window() {}; void name() const; virtual void display() const; }; void Window::name() const { cout << "window name" << endl; } void Window::display() const { cout << " window display()" << endl; } class WindowWithScrollBars: public Window //派生类 { public: WindowWithScrollBars() {}; virtual void display() const; }; void WindowWithScrollBars::display() const { cout << "WindowWithScrollBars display()" << endl; } void pintNaandWind(Window w) { w.name(); w.display(); } int main() { WindowWithScrollBars wwsb; pintNaandWind(wwsb); //打印结果变成基类的display() system( "pause"); return 0; } |
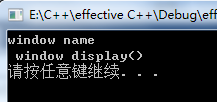
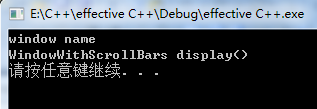
|
1
2 3 4 5 6 7 8 |
void pintNaandWind(
const Window &w)
{ w.name(); w.display(); } |
解释一下:
(1)所谓的slicing问题,也就是如果你把子类的对象赋值给父类的对象,如果用reference和指针,当然是可以的,而且这也是virtual的实现必需品。但是,如果用pass-by-value,就会出现,传进去的总是父类的对象,在传递对象的时候出现了切割问题。
(2)如果窥视c++编译器的底层,你会发现,references往往以指针实现出来,因此pass-by-reference通常意味着这真正传递的是指针。因此如果你有个对象属于内置类型(如int),pass by reference或pass by reference to const时,选择pass by value并非没有道理。这个忠告也适用于STL的迭代器和函数对象,因为习惯上它们都被设计为pass by value。迭代器和函数对象的实践者有责任看看他们是否高效且不受切割问题的影响。
(3)内置类型都相当的小。因此有人认为,所有小类型的types都是pass by value的合格候选人,甚至他们是用户自定义的class亦然。这是个不可靠的推论。对象小并不就意味其copy构造函数不昂贵。许多对象,包括STL容器,内含的东西只比一个指针多一些,但复制这种东西对象却需要承担“复制那些指针的每一样东西”。那将非常昂贵。
即使小型对象拥有并不昂贵的copy构造函数,还是可能有效率上的争议。某些编译器对待“内置类型”和“用户自定义类型”的态度截然不同,总是两者有相同的底层表述。举个例子,某些编译器拒绝把只由一个double组成的对象放进缓存器内,却很乐意在一个正规基础上对光秃秃的double那么做。当这种事发生,你更应该以by reference方式传递此等对象,因为编译器当然会将指针(references的实现体)放进缓存器内,绝无问题。
小型的用户自定义类型并不必然成为pass by value优良候选人的另一个理由是,作为一个用户自定义类型,其大小容易有所改变。甚至当你改用另一个c++编译器都有可能改变type的大小。举个例子,某些标准程序库实现版本中的string类型比其他版本大七倍!
▲ 尽量以pass-by-reference-to-const替换pass-by-value.前者通常比较高效,并可避免切割问题(slicing
problem).
▲ 以上规则并不适合与内置类型,以及STL的迭代器和函数对象.对它们而言,pass-by-value往往比较适合.
条款21 必须返回对象时,别妄想返回其reference
|
1
2 3 4 5 6 7 8 9 10 11 12 |
class Rational
{ private: int numerator; int denominator; public: Rational(): numerator( 0), denominator( 1) {} friend const Rational & operator* ( const Rational &r1, const Rational &r2) { … } }; |
|
1
2 3 4 5 6 7 |
friend
const Rational &
operator* (
const Rational &r1,
const Rational &r2)
{ Rational temp; temp.numerator = r1.numerator * r2.numerator; temp.denominator = r1.denominator * r2.denominator; return temp; } |
这是一种最容易想到的实现方式,在栈上创建对象temp,分子、分母分别相乘后,将之返回。
但仔细再想想,调用函数真的能收到这个temp吗?它是在operator*函数调用时的栈上产生的,当这个函数调用结束后,栈上的temp也会被pop掉,换言之,temp的生命周期仅存在于operator*函数内,离开这个函数,返回的引用将指向一个已经不在的对象!
对此,VS编译器已经给出了warning,如下:
“warning C4172: returning address of local variable or temporary”
千万不能忽略它。
那既然栈上创建对象不行,还可以在堆上创建嘛(new出来的都是在堆上创建的),于是我们有:|
1
2 3 4 5 6 7 |
friend
const Rational &
operator* (
const Rational &r1,
const Rational &r2)
{ Rational *temp = new Rational(); temp->numerator = r1.numerator * r2.numerator; temp->denominator = r1.denominator * r2.denominator; return *temp; } |
这下VS编译器没有warning了,之前在资源管理那部分说过,new和delete要配对,这里只有new,那delete了?delete肯定不能在这个函数里面做,只能放在外面,这样new和delete实际位于两个不同的模块中了,程序员很容易忘记回收,而且给维护也带来困难,所以这绝对不是一种好的解决方案。书上举了一个例子,比如:
1 Rational w, x, y, z; 2 w = x * y * z;
连乘操作会有两次new的过程,我们很难取得operator*返回的reference背后隐藏的那个指针。
当然,如果把new换成auto_ptr或者是shared_ptr,这种资源泄露的问题就可以避免。
栈上创建的临时对象不能传入主调模块,堆上创建的对象就要考虑资源管理的难题,还有其他解决方法吗?
我们还有static对象可以用,static对象位于全局静态区,它的生命周期与这个程序的生命周期是相同的,所以不用担心它会像栈对象那样很快消失掉,也不用担心它会像堆对象那样有资源泄露的危险。可以像这样写:
|
1
2 3 4 5 6 7 |
friend
const Rational &
operator* (
const Rational &r1,
const Rational &r2)
{ static Rational temp; temp.numerator = r1.numerator * r2.numerator; temp.denominator = r1.denominator * r2.denominator; return temp; } |
这样写编译器同样不会报错,但考虑一下这样的式子:
1 Rational r1, r2, r3; 2 if(r1 * r2 == r1 * r3){…}
if条件恒为真,这就是静态对象做的!因为所有对象共享这个静态对象,在执行r1*r2时,temp的值为t1,但执行r1*r3之后,temp的值统一都变成t2了。它在类中只有一份,明白这个原因后就不难理解了。
既然一个static对象不行,那弄一个static数组?把r1*r2的值放在static数组的一个元素里,而把r1*r3放在static数组的另一个元素里?仔细想想就知道这个想法是多么的天马行空。
一个必须返回新对象的正确写法是去掉引用,就这么简单!|
1
2 3 4 5 6 7 |
inline const Rational
operator* (
const Rational &r1,
const Rational &r2)
{ Rational temp; temp.numerator = r1.numerator * r2.numerator; temp.denominator = r1.denominator * r2.denominator; return temp; } |
该让编译器复制的时候就要放手去复制,就像花钱买东西一样,必须花的终究是要花的。
最后总结一下:
绝对不要返回pointer或reference指向一个local stack对象,指向一个heap-allocated对象也不是好方法,更不能指向一个local static对象(数组),该让编译器复制对象的时候,就让它去复制!
条款22 将成员变量声明为private
条款23 宁以non-member、non-friend 替换member函数
思考下面的问题:
一个网页浏览器类
|
1
2 3 4 5 6 7 8 9 |
class WebBrowser
{ public: ... void clearCache(); //清除Cache void clearHistory(); //清除History void removeCookies(); //清除Cookies ... }; |
|
1
2 3 4 5 6 |
class WebBrowser
{ ... void clearEverything(); ... }; |
|
1
2 3 4 5 6 |
void clearBrowser(WebBrowser &wb)
{ wb.clearCache(); wb.clearHistory(); wb.clearCoockies(); } |
现在的问题是哪个好?为什么?
|
1
2 3 4 5 6 7 8 9 |
namespace WebBrowserStuff
{ class WebBrowser { ... }; void clearBrowser(WebBrowser &wb); ... } |
将所有便利函数放在多个头文件中但隶属同一个命名空间,意味着客户可以轻松扩展这一组便利函数。他们所要做的就是添加更多non-member non-friend函数到此命名空间内。例如:如果客户想写些与影像下载相关的便利函数,只要在WebBrowserStuff命名空间内建立一个头文件,内含那些函数的声明即可。新函数就像其他旧函数一样可用且整合为一体。这是class无法提供的另一个性质,因为class定义对客户是不能扩展的。
请记住:
拿non-member non-friend函数替换member函数。可以增加封装性、包裹弹性(packaging flexibility)、和机能扩充性
条款24 若所有参数皆须类型转换,请为此采用non-member函数。
|
1
2 3 4 5 6 7 |
class Rational
{ public: Rational( int numerator = 0, int denominator = 1); //刻意不为explicit;允许int-to-Rational隐式转换 int numerator() const; int denominator() const; }; |
在支持算术运算符时考虑该由member函数、还是non-member函数来实现:
先看成员函数的写法:
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
class Rational
{ public: const Rational operator*( const Rational &rhs) const; }; Rational oneEight( 1, 8); Rational onehalf( 1, 2); Rational result = oneHalf * oneEight; //nice result = result * oneEight; //ok //但是你希望支持混合运算: result = oneHalf * 2; //ok 2发生了隐式类型转换。 result = 2 * oneHalf; //wrong ! //这样便一目了然: result = oneHalf. operator * ( 2); //ok result = 2. operator * (oneHalf); //wrong! |
|
1
|
result =
operator*(
2, oneHalf);
//wrong!
|
本例不存在这样一个接受int和Rational作为参数的non-member operator* 因此查找失败。
只有当参数被列于参数列(parameter list)内,这个参数才是隐式类型转换的合格参与者。地位相当于“被调用之成员函数所隶属的那个对象”——即this对象——的那个隐喻参数,绝不是隐式转换的合格参与者。
|
1
2 3 4 5 6 |
const Rational
operator*(
const Rational &lhs,
const Rational &rhs)
{ return Rational(lhs.numerator() * rhs.numerator(), lhs.denominator() * rhs.denominator()); } result = 2 * oneHalf; //ok!终于编译通过了! |
operator*是否要成为Rational的friend函数呢?答案是否定的,因为operator*完全籍由Rational的public接口完成任务;无论何时如果你可以避免friend函数就该避免。
当让Rational成为一个class template, 又有一些新争议、解法、牵连形成了 条款46
条款25 考虑写出一个不抛出异常的swap函数。
|
1
2 3 4 |
int a =
1;
int b = 2; std::swap(a, b); cout << "a = " << a << " b = " << b << endl; |
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
class Test
{ public: Test( int i): val(i) {} int getVal() { return val; } private: int val; }; Test a( 1); Test b( 2); std::swap(a, b); cout << "a = " << a.getVal() << " b = " << b.getVal() << endl; return 0; |
相比之下,“以指针指向一个对象,内含真正的数据”的方法更受欢迎。比如pimpl(pointer to implementation)。然后交换它们的指针。按照这种方法,我们应该这样设计我们的类:
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
//类的具体实现 class TestImpl { public: TestImpl( int i): ival(i) {} int getVal() { return ival; } private: int ival; }; //指针 class Test { public: Test( int i): p( new TestImpl(i)) {} ~Test() { delete p; } Test operator=( const Test rhs) { *p = *(rhs.p); } int getVal() { return this->p->getVal(); } void swap(Test &other) { using std::swap; swap(p, other.p); } private: TestImpl *p; }; |
|
1
2 3 4 5 6 7 8 |
namespace std
{ template<> void swap<Test>(Test &a, Test &b) { a.swap(b); } } |
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
//类的具体实现 template < typename T1> class TestImpl { public: TestImpl(T1 i): ival(i) {} virtual T1 getVal() { return ival; } private: T1 ival; }; //指针 template < typename T1> class Test { public: Test(T1 i): p( new TestImpl(i)) {} ~Test() { delete p; } Test operator=( const Test rhs) { *p = *(rhs.p); } T1 getVal() { return this->p->getVal(); } void swap(Test &other) { using std::swap; swap(p, other.p); } private: TestImpl *p; }; |
|
1
2 3 4 5 6 7 8 |
namespace std
{ template< typename T1> void swap<Test<T1>>(Test<T1> &a, Test<T1> &b) { a.swap(b); } } |
有没有好的办法呢?其实很简单,只要把原来的函数重载就行了。
|
1
2 3 4 5 |
template<
typename T>
void swap(Test<T> &a, Test<T> &b) { a.swap(b); } |
现在的考虑另一种情况:假如你在一个函数模板中需要调用swap函数,该怎么做呢?首先,你希望的情况是:最好调用专属的swap,如果不存在,那么调用std下的swap:
|
1
2 3 4 5 6 7 |
template <
typename T>
void doSomething(T &obj1, T &obj2) { //其他操作省略 using std::swap; swap(obj1, obj2); } |
总而言之:
1.虽然std下提供了一个swap函数,但是由于这个函数效率不高,所以我们倾向于在交换类时,通过pimpl技术交换指针。
2.首先,我们需要定义一个public swap函数,在这个函数中调用std下的swap函数完成指针的交换。
3.然后定义一个非成员swap函数,这个函数调用public swap。
4.假如的是类模板,那么,需要重载一个swap函数,然后将这个函数与模板类一起放在一个命名空间中。
5.调用swap时应使用using std::swap;声明。这样对于与重载的swap函数类型不符的函数,会调用std下的swap完成。















 8853
8853

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









