






文章目录
1. 重排序缓存
本质上是FIFO. 存储指令的类型,结果,目的寄存器和异常的类型。ROB容量决定了流水线中最多可以同时执行的指令个数。


4-way超标量处理器ROB端口需求:
- 读端口
- 寄存器重命名阶段 :四条指令源操作数ROB需要8个读端口
- 提交阶段:四条指令退休(最少,实际issue width更宽)需要4个读端口
- 写端口
- 分发阶段:写入ROB四条指令,需要4个写端口
- 写回阶段:写入四条指令结果,最少需要4个写端口
2. 管理处理器状态
Architecture State 和 Speculative State
2.1 使用ROB管理指令集定义的状态
ARF也称为RRF(retire register file)。
一般配合数据捕捉。payload RAM.
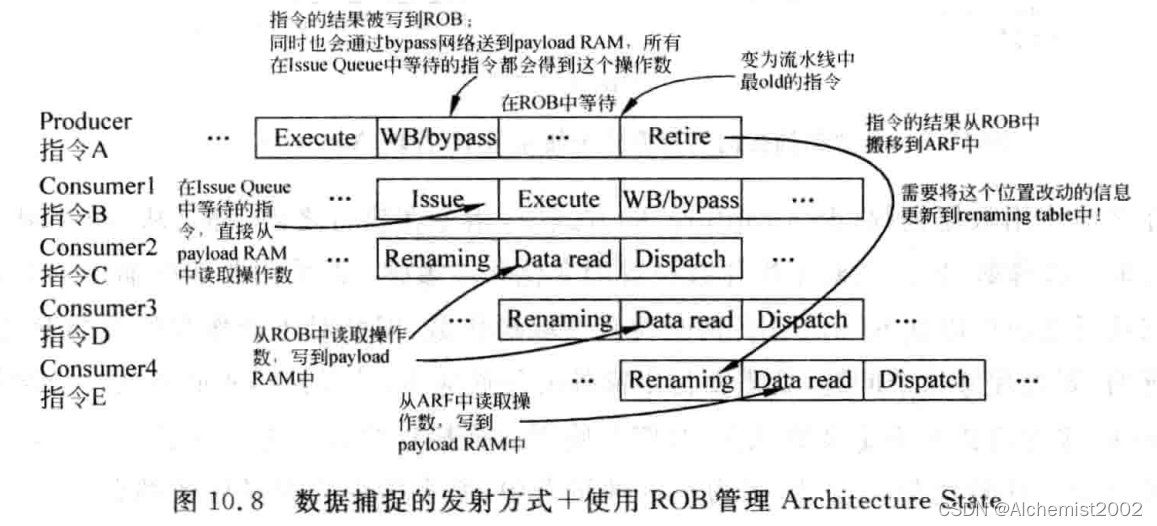
不管指令从旁路网络、ROB还是通用寄存器中取得操作数,最后都需要在进入流水线执行阶段之前,从payload RAM中得到操作数,这种方式不关心操作数位置变化。
ROB+非数据捕捉有较高的硬件复杂度。
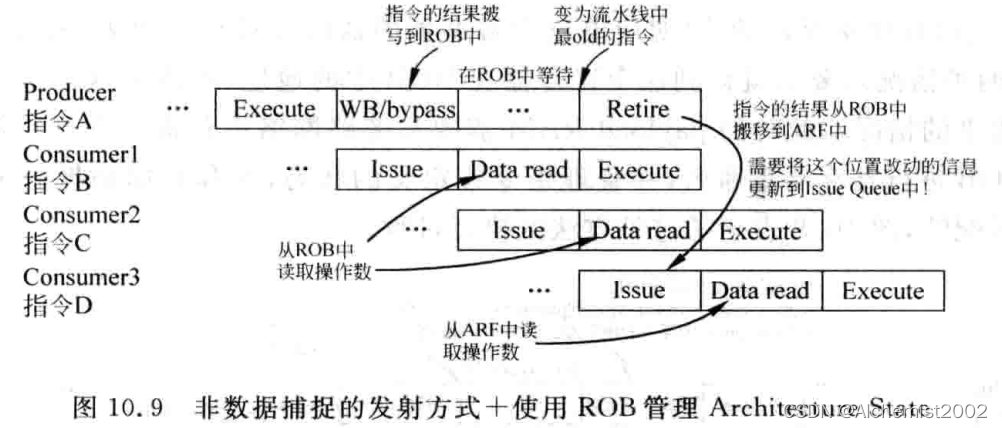
2.2. 使用物理寄存器管理指令集定义的状态
使用统一的物理寄存器堆PRF。指令集中定义的所有寄存器堆都混在这个寄存器堆中。
一条指令退休时,这条指令结果仍然占据原来对应的物理寄存器,状态会标记为Architecture state,等到后续有另外一条指令也写到同一个目的寄存器,并且这条后续指令退休时,才可以将当前这条指令对应的物理寄存器释放。
优点:
- 指令从ROB中退休时,不需要将指令结果搬移,仍存在于物理寄存器中。低功耗设计。
- 一部分指令没有目的寄存器,该方式占用的物理寄存器个数小于此时ROB中指令个数。
- ROB需要大量读写端口,而使用PRF状态管理,可以对PRF采用cluster结构等,采用一些灵活方式避免多端口的负面影响。
缺点:
需要额外表格存放那些物理寄存器是空闲的;需要额外表格存放哪些物理寄存器是Architecture state。
3. 特殊情况处理
- 分支预测失败
- 异常
- store
3.1 分支预测失败
以寄存器重命名阶段为界:
- 前端恢复 front-end recovery:重命名阶段之前的指令抹掉,分支预测器中的历史状态表(GHR、BHR等)进行恢复,并使用正确的地址取指令。
- 后端恢复 back-end recovery:Issue Queue、Store buffer和ROB错误的指令抹掉,将RAT恢复,同时被错误指令占据的物理寄存器和ROB的空间也需要被释放。
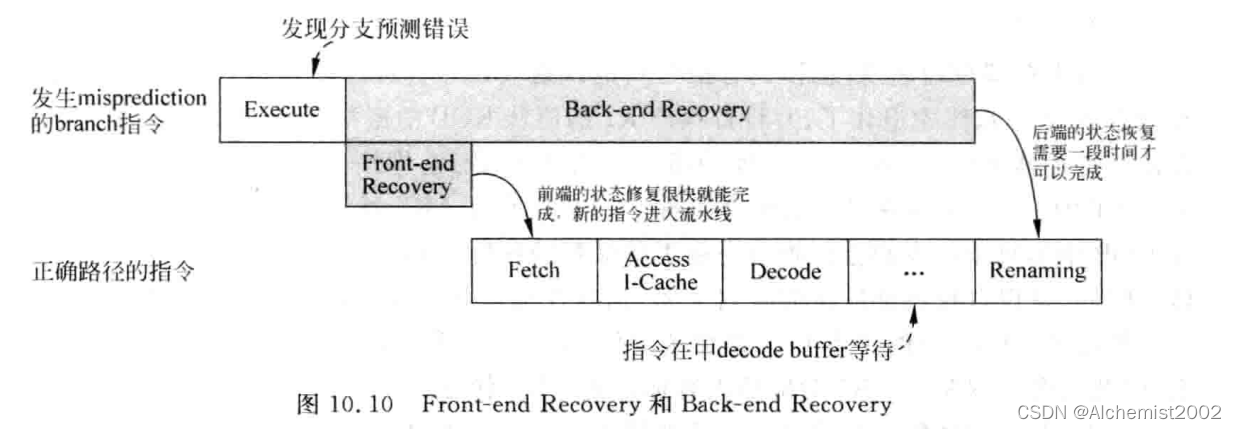
当 T i m e ( b a c k − e n d r e c o v e r y ) < T i m e ( f r o n t − e n d r e c o v e r y ) + T i m e ( f e t c h − r e n a m i n g ) Time_{(back-end\ recovery)}<Time_{(front-end\ recovery)}+Time_{(fetch-renaming)} Time(back−end recovery)<Time(front−end recovery)+Time(fetch−renaming)此时,流水线不需要暂停。
大部分恢复任务都是对寄存器重命名相关的部件进行的,重命名的方式直接决定了使用何种方法进行状态恢复。
基于ROB和使用扩展的ARF进行重命名在本质上一样,因此这里主要总结两种分支预测失败时进行状态恢复的方法。
3.1.1 基于ROB进行重命名的架构中进行状态恢复
使用ARF对重命名阶段使用的RAT进行恢复
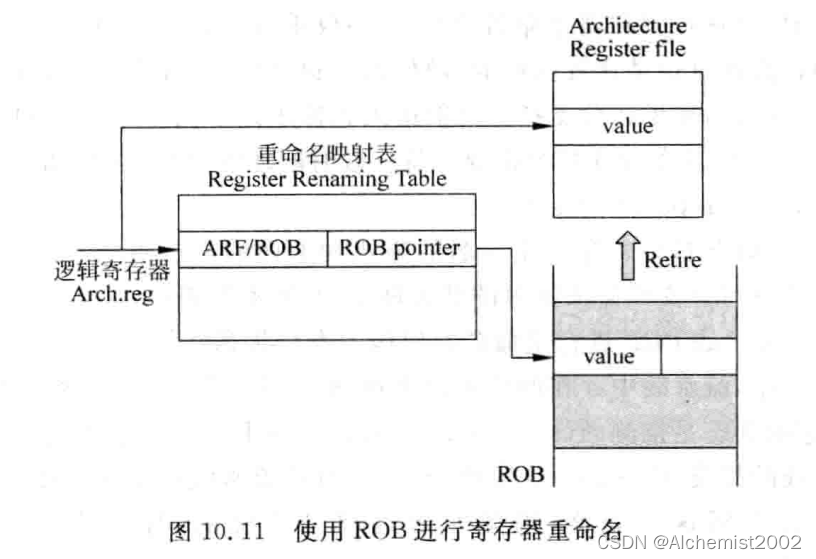
只有一条指令从ROB退休时,发现自身时最新的映射关系,才能够将RAT中对应的内容改为ARF状态。
流水线抽干 drain out. 分支指令之前的所有指令退休,抹掉流水线的错误指令,然后将RAT中的所有内容都标记为ARF状态。但是分支指令前有load指令D-cache misss时,miss-prediction penalty变大。
3.1.2 在基于同一的PRF进行重命名的架构中进行状态修复
该架构中,流水线存在两个重命名映射表。
- 寄存器重命名阶段的前端RAT:状态是推测的,也称作Speculative RAT.
- 提交阶段的后端RAT:Architecture RAT
1. drain out 后使用后端RAT对分支预测失败时的处理器进行状态恢复(将后端RAT复制到前端RAT)。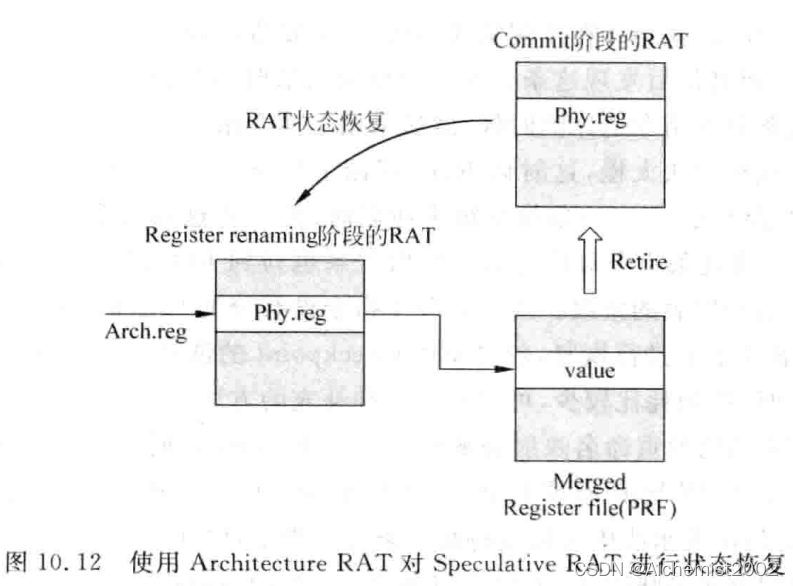
这种方式分支指令前有load指令D-cache misss时,miss-prediction penalty变大。跟ROB状态恢复方法一样,都需要等待预测失败的分支指令退休的时候,才能进行处理器的状态恢复。这类方法称作Recovery at Retire.
使用后端的映射表对重命名阶段使用的RAT恢复。
2. Checkpoint方法快速状态恢复。不需要等分支指令退休,而是预测失败时马上状态恢复。
在分支指令及后面的指令对RAT更改之前,将RAT的内容保存起来。预测失败时,使用这条分支指令编号将错误路径上的指令抹掉,同时使用checkpoint资源将处理器状态恢复,然后就可以从正确路径上取指令执行。
-
对基于SRAM的RAT. 硬件资源昂贵,无法支持个数很多的checkpoint。因此,当分支预测正确率很高时,可以对分支指令预测的正确率进行预测。

A six-transistor CMOS SRAM cell 当一条分支指令对应的饱和计数器处于饱和状态,说明它的预测正确率比较高,对这样的分支指令不分配checkpoint资源。对经常预测错误的分支指令才进行checkpoint。
当一条分支指令没有分配checkpoint最后又分支预测失败时,可以采用等到这条分支指令退休时,使用Recovery at retire。这种方式较慢,因此也可以通过ROB将RAT恢复。ROB记录RAT被修改的历史。当一条指令重命名时,除了将这条指令当前的映射关系写到ROB之外,还需要将这条指令对应的旧的映射关系也写道ROB中,ROB记录每条指令对RAT的修改,因此一条分支指令没有分配checkpoint时,可以通过ROB将RAT恢复。
-
对基于CAM结构

CMOS binary CAM Cell 6T SRAM cell plus 4 comparison transistors
BL: bit line ML: match line SL: search line进行checkpoint只需要对RAT中的状态位保存。需要的硬件资源少。可以支持很多checkpoint。
缺点是电路面积和延迟很大,表格容量正比于物理寄存器个数,PR很多RAT电路面积就很大;而且CAM寻址延迟很大。
3.2 异常处理
精确异常:处理器知道哪条指令发生异常,并且这条发生异常的指令之后所有指令都不允许改变处理器的状态,好像这些指令从来没有发生过一样。对异常处理完后可以精确返回,可以返回发生异常的指令本身(TLB miss),也可以返回到它的下一条指令开始执行(syscall)。
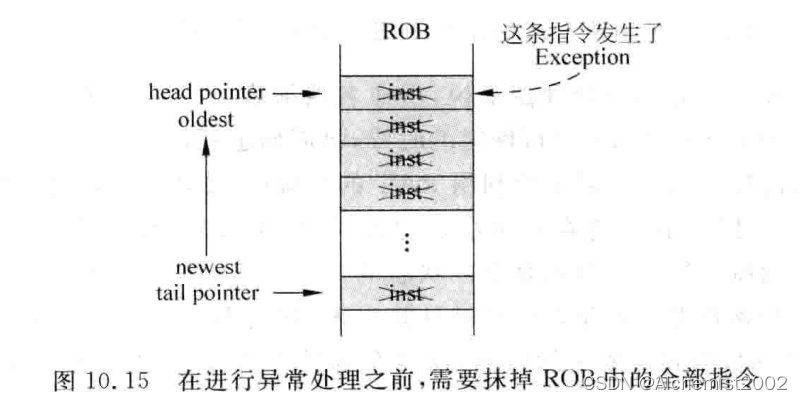
1. recovery at retire 式处理
此时要完成的任务和recovery at retire情形一样。处理器状态恢复后,可以跳转到对应的异常处理程序的入口地址,取新的指令执行。
这种方法好处是,假如异常处于分支预测失败的路径上,其实异常是无效的,因此会被抹掉不被处理。
2. WALK方法
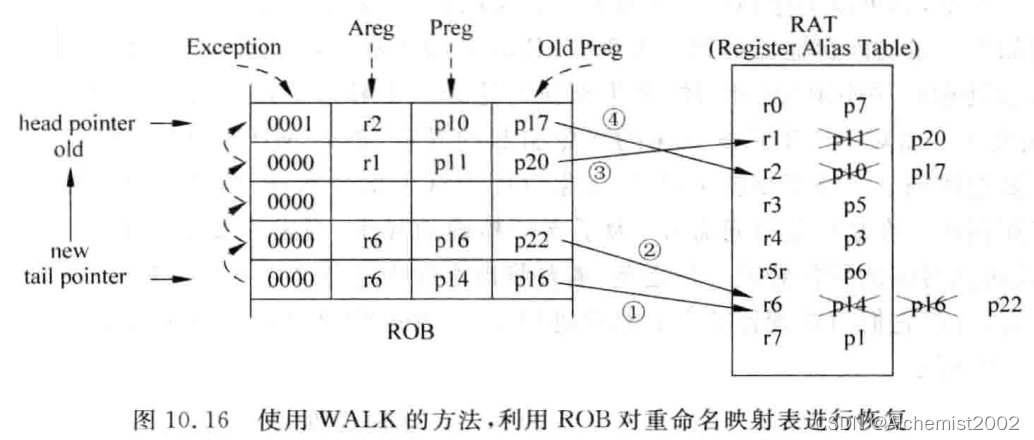
从tail pointer开始将对应的旧的映射关系写到重命名映射表中。
使用统一的PRF进行寄存器重命名方式中,还需要恢复与RAT相关的两个表格。即:
- Free Register Pool:存储哪些物理寄存器是空闲状态。
需要恢复读指针。每当ROB中读取一条存在目的寄存器的指令对RAT进行恢复时,就将Free Register Pool的读指针也变化一格。 - Busy Table:存储每个物理寄存器的值是否已经被计算出来。
指令将结果写到PRF时,将Busy Table对应状态进行修改。在从ROB中读取指令进行状态恢复时,每读取一条指令,就将这条指令的目的寄存器在Busy Table中对应的内容置为无效。这样即使这条指令将结果已经写到PRF中,也可以将其变为无效,后续指令不会使用错误的值。
对于异常发生时的处理器来说,如果采用ROB进行重命名的架构,使用recovery at retire 方法是合适的;而对于采用统一的PRF进行重命名的架构,使用WALK方法更好(recovery at retired方法对两个表格的状态恢复没那么直接)
3.3 中断的处理
中断是异步的,有两种方式对中断进行处理。
- 马上处理。流水线所有指令抹掉(用3.2介绍的方法恢复处理器状态),并将流水线中最旧的指令PC及一些状态寄存器保存。然后跳转到对应的中断处理程序(interrupt handler)中。返回时,使用中断发生时所保存的PC值重新取指。
- 延迟处理。等到流水线所有指令退休才对中断处理。
3.4 Store指令处理
一条store指令在缓存中有三个状态,即没有执行完毕(un-complete)、已经执行完毕(complete)和顺利离开流水线(retire)。处于retire状态的内容也成为处理器状态(architecture state)的一部分。
只有真正完成D-Cache操作的store指令才可以离开store buffer,会造成它实际可用容量降低,因此也可以将退休的store指令存储在write back buffer。
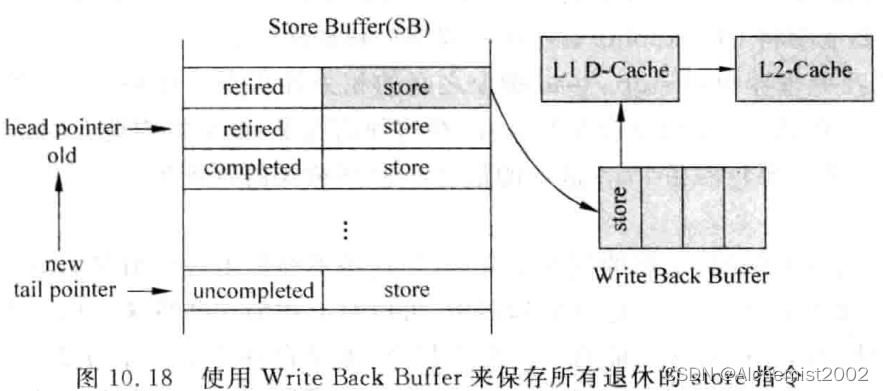
load指令需要在store buffer和write back buffer这两个缓存中都进行查找。
非阻塞结构的D-cache?
3.5 指令离开流水线的限制
因为不值得为不经常出现的情况而浪费硬件资源(比如一个周期需要四条branch\load\store退休,需要很多写端口;释放资源等),所以需要在提交阶段对分支指令、store指令和load指令的个数都进行限制。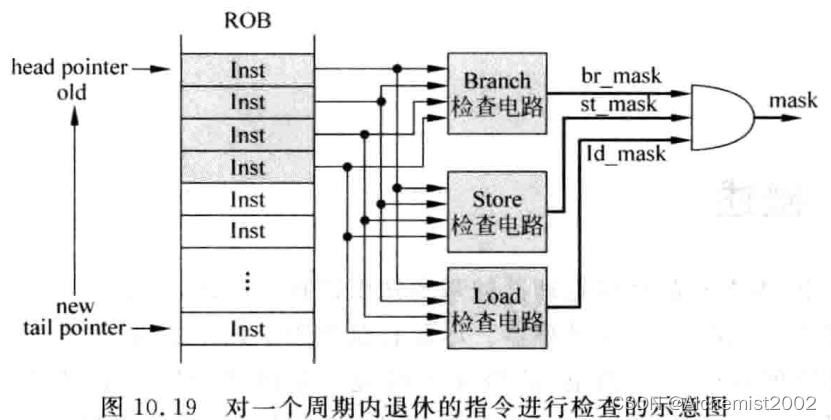
每周期也只能处理一条指令的异常。

















 2817
2817

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









