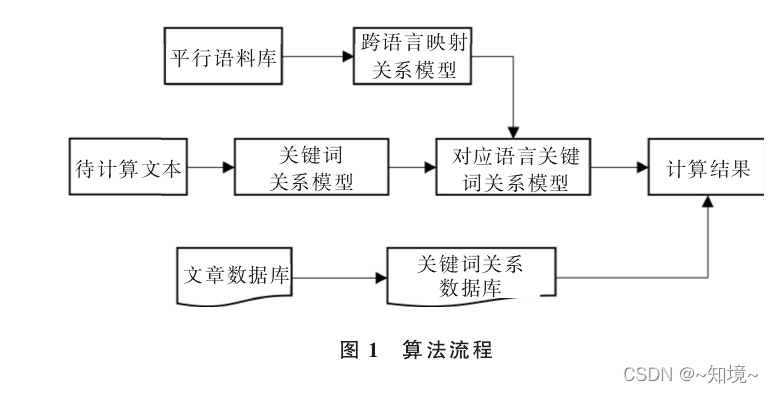
论文阅读笔记 1. title:基于文本加权词共现的跨语言文本相似度分析 张晓宇 中国传媒大学 软件导刊 跨语言文本相似度计算三种方法: (1)基于全文机器翻译方法:把源语言和目标语言映射到中间语言 (2)基于统计翻译模型方法:建立两种语言之间生成翻译概念词典,因此要大规模对齐语料 (3)CL-ESA算法 explicit semantic analysis 两个阶段: 匹配阶段和映射阶段 跨语言映射关系模型 输入: 平行语料 输出:<源语F, 目标语言F’>映射关系


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











 该文综述了跨语言文本相似度的计算方法,包括基于机器翻译、统计翻译模型和CL-ESA算法。同时,探讨了结合预训练模型和语言知识库的文本匹配技术,指出BERT在处理固定词组结构和语义时的局限性。此外,还介绍了针对长文本匹配的图分类框架,并讨论了图表示学习、图卷积神经网络在节点特征抽取中的应用。研究进一步提出了利用先验知识指导BERT注意力机制在语义匹配任务中的方法。
该文综述了跨语言文本相似度的计算方法,包括基于机器翻译、统计翻译模型和CL-ESA算法。同时,探讨了结合预训练模型和语言知识库的文本匹配技术,指出BERT在处理固定词组结构和语义时的局限性。此外,还介绍了针对长文本匹配的图分类框架,并讨论了图表示学习、图卷积神经网络在节点特征抽取中的应用。研究进一步提出了利用先验知识指导BERT注意力机制在语义匹配任务中的方法。



 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章























