







https://arxiv.org/pdf/2307.08925.pdf
这篇文章算是一篇position paper,阐述了作者对联邦大模型的理解与看大。初学者可以当一篇综述来看。文章思想很朴素,也很容易理解,基本就是有大模型基础和联邦学习基础的人都能想到或是理解的。
联邦大模型的两种学习方式
两种非常直观的方法:一种是从头训练,一种是利用私有数据集进行微调。优劣也非常直观:第一种方法允许特定任务的模型设计和潜在的优越性能,但需要更高的计算和通信成本。另一方面,第二种方法减少了开销,但可能会牺牲一定程度的任务适应性。
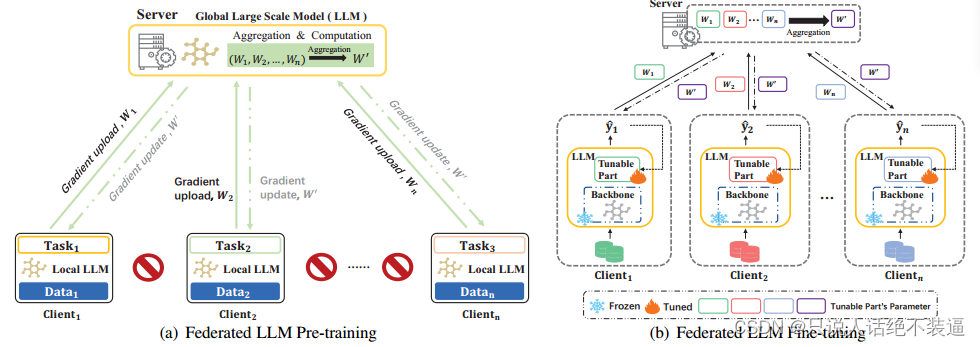
联邦微调
联邦微调是微调阶段进行联邦学习,也就是模型不但可以用本地数据进行个性化微调,还可以习得其余客户端的知识。微调有两种思路:一种是直接微调(就是最传统的fedavg式的微调),另一种是用一些微调技术,比如adapter tuning, prefix tuning, prompt tuning, and low-rank adaptation (LoRA).
联邦大语言模型提示工程( Federated LLM Prompt Engineering)
啥是提示工程(promote engineering)?我问chatgpt居然不知道。。。看来是个新词,学术界的造词能力真强啊。

提示工程(Prompt Engineering)是一门较新的学科,关注提示词开发和优化,帮助用户将大语言模型(Large Language Model, LLM)用于各场景和研究领域。
简单讲,就是我们该怎么提问,大模型才能给出更好的输出?大模型不是人,本质还是输入输出的对应,我们的提问方式变一变,哪怕从人类的理解上提问的内容是一样的,但模型很有可能给出不同的输出。
传统的提示工程都是在公开数据集上操作,这可能很难引导模型做出非常个性化的回答。联邦学习利用了很多私域数据,这使得在提示学习中可以习得与私域数据相关联的提示词。
关于联邦提示学习,可以参考论文:《PROMPTFL: Let Federated Participants Cooperatively Learn Prompts Instead of Models — Federated Learning in Age of Foundation Mode》
挑战
作者随后附上了联邦大模型领域的挑战。其实说实话,很多问题来自FL本身。因此要解决的问题跟联邦学习很像。这一部分可得好好看,这可是获得文章灵感的好部分。
模型安全问题
安全问题,比如对抗攻击和后门攻击(参考我之前的文章《联邦后门攻防综述【一】》)。大模型结构复杂,后门会更加隐蔽,也更难清除。
基于相似性和鲁棒性的聚合算法直接应用上来的话也会有挑战,作者指明的方向是利用深度学习训练中损失函数和多轮训练结构的特点作为可能的方向。
隐私保护问题
首先是大模型固有的隐私问题,跟联邦不联邦没关系,这个就不多赘述了,不属于联邦范畴。
其次,transformer很容易携带用户的数据信息,服务器很容易从用户上传的模型中提取信息。
提示攻击:提示工程能让模型给出更个性化的回答,但也会诱导模型给出涉及隐私的回答。
Non-iid和效率问题
看完之后感觉都是联邦中的那些东西,没什么新的东西。
总结
其实联邦大模型和联邦学习有很多问题时重合的,特异性的问题主要来自于transformer。transformer相比之前各种啥NN网络会有独特的问题,这是可以着力下手的地方。















 1050
1050











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









