







 本文介绍了联邦学习后门攻击的评价指标,如攻击成功率(ASR)和主任务准确率(MTA),对比了后门攻击与拜占庭攻击的区别。还分析了三篇联邦学习后门攻击鼻祖文章,包括攻击方法、聚合公式等,如模型替换、利用尾部数据攻击等。
本文介绍了联邦学习后门攻击的评价指标,如攻击成功率(ASR)和主任务准确率(MTA),对比了后门攻击与拜占庭攻击的区别。还分析了三篇联邦学习后门攻击鼻祖文章,包括攻击方法、聚合公式等,如模型替换、利用尾部数据攻击等。
话不多说,直接上干货。
评价指标
ASR、MTB
ASR
攻击成功率:
A
S
R
=
∑
x
∈
D
~
f
w
(
x
)
=
τ
∣
D
~
∣
ASR = \sum_{x\in\tilde{D}}\frac{f_w(x) = \tau}{|\tilde{D}|}
ASR=x∈D~∑∣D~∣fw(x)=τ
其中D(头顶小波浪)为中毒数据样本集,
τ
\tau
τ为目标类,|D|为中毒数据集的大小。一句话总结ARS就是中毒数据被分类为中毒目标类别的比率。
100个中毒样本,99个成功误导模型进行错误分类,ASR就是99%。
MTA
主任务准确率,模型在良性样本集上的表现:
M
T
A
=
∑
x
i
∈
D
f
w
(
x
i
)
=
y
i
∣
D
∣
MTA = \sum_{x_i\in{D}}\frac{f_w(x_i) = y_i}{|{D}|}
MTA=xi∈D∑∣D∣fw(xi)=yi
完全可以理解为在良性数据集上的正确率。
后门攻击与拜占庭攻击的区别
拜占庭旨在破坏模型,让你模型不收敛或者不能用。而后门攻击旨在注入后门,你的模型看起来似乎没啥问题,也很管用,但实际上一旦带触发器的样本被输入到模型,模型就会产生我想要的分类结果。拜占庭攻击相当于我去刺杀敌方精锐,而后门攻击则是选择策反敌方精锐,把他变成间谍。
后门攻击技术
三篇鼻祖文章
1、《How to Backdoor Federated Learning》论文链接
2、《Can You Really Backdoor Federated Learning?》论文链接
3、《Attack of the Tails: Yes, You Really Can Backdoor Federated Learning》论文链接
这三篇文章可谓是典中典,探讨了联邦学习中后门攻击的方法与防御思路以及可行性。
how to这篇文章中,作者提出的攻击方法是模型替换(model replacement)。文章指出,幼稚的方法(naive approach)难以起作用,因为聚合会将后门抹去,导致全局模型中毒极缓甚至无法中毒(除非恶意客户端数量较多、占比较大)。所谓的“幼稚的方法”,就是恶意客户端啥额外手脚也不做,就老老实实地用本地恶意数据集参与训练上传。
本文中,作者所使用的联邦场景中的聚合公式是这样的:
G
t
+
1
=
G
t
+
η
n
∑
i
=
1
m
(
L
i
t
+
1
−
G
t
)
G^{t+1}=G^{t}+\frac{\eta}{n}\sum_{i=1}^{m}(L_i^{t+1}-G^t)
Gt+1=Gt+nηi=1∑m(Lit+1−Gt)
n表示所有客户端的数量,m表示本轮所选择的客户端的个数,
η
\eta
η是个超参数。
η
n
\frac{\eta}{n}
nη可以视为每个客户端的更新参与全局模型更新的比例。如果
η
=
n
m
\eta=\frac{n}{m}
η=mn,则展开计算之后会发现此时全局模型完全被当前所选择的m个客户端的模型聚合结果所取代。
注意:作者在此选择的聚合公式和FedAvg并不相同。fedavg中,每个客户端参与更新的比例(权重)为该客户端上数据集的大小与本轮全部客户端数据集加起来的大小的比值。本文作者的权重是固定的,而fedavg中的每个客户端更新的权重是不一定相等的(除非两个客户端数据集大小相同)。

作者的攻击方法之所谓被称为“模型替换”,是因为作者放大了模型的更新权重。直观上也好理解:你上传的模型被赋予极大的权重,那聚合之后自然就是你说了算。
攻击发生在模型即将收敛的阶段,因为此时模型即将收敛,良性模型的更新会非常小,对全局模型的更新影响有限。我们将恶意客户端的更新单独拿出来作为一项,公式变为(L波浪为恶意模型的更新):
G
t
+
1
=
G
t
+
η
n
(
∑
i
=
1
m
−
1
(
L
i
t
+
1
−
G
t
)
+
L
~
m
t
+
1
−
G
t
)
G^{t+1}=G^{t}+\frac{\eta}{n}(\sum_{i=1}^{m-1}(L_i^{t+1}-G^t)+\tilde{L}_m^{t+1}-G^t)
Gt+1=Gt+nη(i=1∑m−1(Lit+1−Gt)+L~mt+1−Gt)
作者认为恶意客户端只有一个,因此求和部分的上标变为m-1,后面的L波浪减G为恶意模型的更新。
由于模型即将收敛,因此求和部分可以视为0(良性模型的更新太小了,而且由于全局模型近乎收敛,良性模型更新相加会相互抵消),可写作
G
t
+
1
≈
G
t
+
η
n
(
L
~
m
t
+
1
−
G
t
)
G^{t+1}\approx{G^{t}+\frac{\eta}{n}(\tilde{L}_m^{t+1}-G^t)}
Gt+1≈Gt+nη(L~mt+1−Gt)
如果我们给L波浪一个权重,也就是提交的时候我们先乘个数,
γ
=
n
η
\gamma=\frac{n}{\eta}
γ=ηn,最后变成
G
t
+
1
≈
G
t
+
η
n
(
n
η
L
~
m
t
+
1
−
G
t
)
=
L
~
m
t
+
1
+
(
1
−
η
n
)
G
t
G^{t+1}\approx{G^{t}+\frac{\eta}{n}(\frac{n}{\eta}\tilde{L}_m^{t+1}-G^t)}=\tilde{L}_m^{t+1}+(1-\frac{\eta}{n})G^t
Gt+1≈Gt+nη(ηnL~mt+1−Gt)=L~mt+1+(1−nη)Gt
可以看到,最终的模型中。本次的恶意更新占有极大的话语权,而之前所积累的Gt反而被乘上了一个小于1的系数。因此,这种攻击是一种一次性攻击。在最后只攻击一次,便可有极高的成功率,全局模型在中毒后立即对后门任务显示出很高的准确性。
个人观点:如果是fedavg,则不用赋予一个权重,而是可以谎报本地数据集的大小,让服务器自动赋予一个很高的权重,就能实现攻击。
第二篇can you这篇文章更像是一种对之前工作的总结验证以及进一步的分析。在这篇文章中,作者采用的联邦算法是FdeAvg。fedavg里有两个超参数,分别是K(K是客户端总数,也可以认为不是超参数)、C(每轮选择的客户端比例),忘掉的小伙伴自行翻看论文《Communication-Efficient Learning of Deep Networks from Decentralized Data》)。设敌手的比例为
ϵ
\epsilon
ϵ,在随机抽取的情况下,则每轮训练中被选择中的敌手为0到
m
i
n
(
ϵ
K
,
C
K
)
min(\epsilon{K},CK)
min(ϵK,CK)。啥意思呢?最少有0个被选中,如果C<
ϵ
\epsilon
ϵ,则说明我们本轮要选的客户端比恶意客户端数量还少,此时被选中的客户端中恶意的数量最多为CK(也就是全都是恶意的)。如果C更大,则至多全部的恶意客户端被选中,也就是
ϵ
\epsilon
ϵk。综合写就是
m
i
n
(
ϵ
K
,
C
K
)
min(\epsilon{K},CK)
min(ϵK,CK)。这样下来,纵观整个训练过程,每轮恶意客户端被选择的数量符合超几何分布。
作者又提出另一种攻击方式:恶意客户端并不是被随机抽取,而是固定每f轮有一个恶意客户端被抽到。其中
f
=
1
/
(
ϵ
⋅
C
⋅
K
)
f=1/(\epsilon·{C·K})
f=1/(ϵ⋅C⋅K)。同时,作者假设攻击者的能力为:有中毒数据样本和真实的数据样本,同时在损失中加入范数优化项(就是防止裁剪,绕过服务器的范数限制)。
可以看到,本文作者并没有提出非常新颖的攻击方式,而是在已有的工作上进行了更为细节的思考和实验。
第三篇yes you really can中,作者做了大量的理论分析,证明了联邦中的后门攻击是难以防御的,防御联邦后门是一个np难问题(np难,就是那个p=np的世纪数学难题)。作者在本文中提出的攻击方法是edge-case backdoor attack,利用尾部数据去攻击模型。
所谓“尾部数据”,其实涉及到一种分布:重尾分布。重尾分布包含多种细分分布,简而言之就是差不多长这样
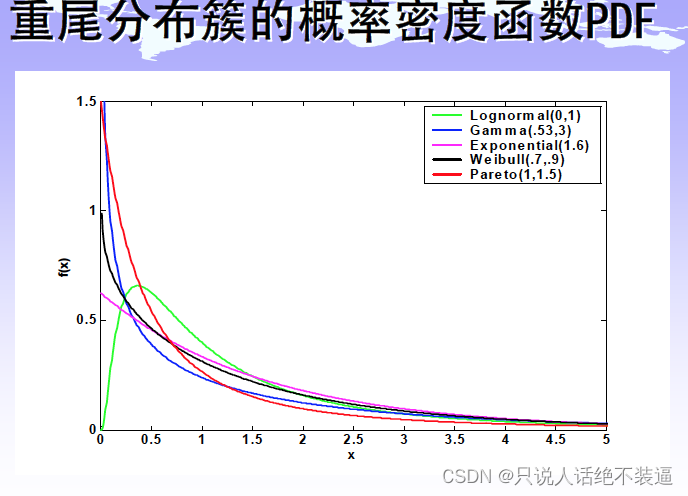
重尾分布的特点就是尾部(靠右侧的概率密度函数小的那边)数据众多,但出现的概率较小。通俗话语讲就类似我们日常说的“二八法则”。本文作者构造了p-edge-case数据集,就是概率小于p的那些数据,在这些数据中注入后门。
我们称p-edge-case的数据为
D
e
d
g
e
D_{edge}
Dedge,自然数据集为
D
D
D,攻击者从D和Dedge的并集中抽出数据集
D
′
D^{'}
D′做训练。
同样,作者提出了PGD来绕过范数检测。简单来讲方法就是对手可以周期性地将模型参数投影到以上一次迭代的全局模型为中心的球上,这样可以绕过范数检测。
综上所述,作者的攻击方法为1、精心构造数据集。2、PGD做范数压缩。3、模型替换。
先讲到这里,后续的以后再写。

















 1300
1300

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









