







数学理论
线性回归
- 线性回归: y = w T x + b y=w^Tx+b y=wTx+b
- 对数线性回归: ln y = w T x + b \ln{y}=w^Tx+b lny=wTx+b
- 广义线性模型:
y
=
g
−
1
(
w
T
x
+
b
)
y=g^{-1}(w^Tx+b)
y=g−1(wTx+b)
- g ( ⋅ ) g(\cdot) g(⋅) :联系函数,必须单调可微
对数几率回归
- 线性回归模型产生的预测值: z = w T x + b z=w^Tx+b z=wTx+b
- 对数几率函数: y = 1 1 + e − z y=\frac{1}{1+e^{-z}} y=1+e−z1
- 将对数几率函数作为 g − 1 ( ⋅ ) g^{-1}(\cdot) g−1(⋅)代入广义线性模型: y = 1 1 + e − ( w T x + b ) y=\frac{1}{1+e^{-(w^Tx+b)}} y=1+e−(wTx+b)1
- 等价变换:
ln
y
1
−
y
=
w
T
x
+
b
\ln{\frac{y}{1-y}}=w^Tx+b
ln1−yy=wTx+b
- 将 y y y 视为样本 x x x 作为正例的可能性,则 1 − y 1-y 1−y 是其反例可能性
- 两者的比例 y 1 − y \frac{y}{1-y} 1−yy 即为几率
- ln y 1 − y \ln{\frac{y}{1-y}} ln1−yy 即为对数几率
- 等价变换:
ln
p
(
y
=
1
∣
x
)
p
(
y
=
0
∣
x
)
=
w
T
x
+
b
\ln{\frac{p(y=1|x)}{p(y=0|x)}}=w^Tx+b
lnp(y=0∣x)p(y=1∣x)=wTx+b
- p ( y = 1 ∣ x ) = e w T x + b 1 + e w T x + b p(y=1|x)=\frac{e^{w^Tx+b}}{1+e^{w^Tx+b}} p(y=1∣x)=1+ewTx+bewTx+b
- p ( y = 0 ∣ x ) = 1 1 + e w T x + b p(y=0|x)=\frac{1}{1+e^{w^Tx+b}} p(y=0∣x)=1+ewTx+b1
- 最大似然估计
- 最大化对数似然函数:
l
(
w
,
b
)
=
∑
i
=
1
m
ln
p
(
y
i
∣
x
i
;
w
,
b
)
l(w,b)=\sum\limits_{i=1}^m\ln{p(y_i|x_i;w,b)}
l(w,b)=i=1∑mlnp(yi∣xi;w,b)
- 令 β = ( w ; b ) , x ^ = ( x ; 1 ) , 则 w T x + b = β T x ^ 令\beta=(w;b),\hat{x}=(x;1),则w^Tx+b=\beta^T\hat{x} 令β=(w;b),x^=(x;1),则wTx+b=βTx^
- 令 p 1 ( x ^ ; β ) = p ( y = 1 ∣ x ^ ; β ) 令p_1(\hat{x};\beta)=p(y=1|\hat{x};\beta) 令p1(x^;β)=p(y=1∣x^;β)
- 令 p 0 ( x ^ ; β ) = p ( y = 0 ∣ x ^ ; β ) = 1 − p 1 ( x ^ ; β ) 令p_0(\hat{x};\beta)=p(y=0|\hat{x};\beta)=1-p_1(\hat{x};\beta) 令p0(x^;β)=p(y=0∣x^;β)=1−p1(x^;β)
- 等价变换: p ( y i ∣ x i ; w , b ) = y i p 1 ( x ^ i ; β ) + ( 1 − y i ) p 0 ( x ^ i ; β ) {p(y_i|x_i;w,b)}=y_ip_1(\hat{x}_i;\beta)+(1-y_i)p_0(\hat{x}_i;\beta) p(yi∣xi;w,b)=yip1(x^i;β)+(1−yi)p0(x^i;β)
- 等价于最小化凸函数: l ( β ) = ∑ i = 1 m [ − y i β T x ^ i + ln ( 1 + e β T x ^ i ) ] l(\beta)=\sum\limits_{i=1}^m[-y_i\beta^T\hat{x}_i+\ln{(1+e^{\beta^T\hat{x}_i})}] l(β)=i=1∑m[−yiβTx^i+ln(1+eβTx^i)]
- 用梯度下降法或牛顿法可求出: β ∗ = arg min β l ( β ) \beta^*=\argmin\limits_{\beta}l(\beta) β∗=βargminl(β)
- 最大化对数似然函数:
l
(
w
,
b
)
=
∑
i
=
1
m
ln
p
(
y
i
∣
x
i
;
w
,
b
)
l(w,b)=\sum\limits_{i=1}^m\ln{p(y_i|x_i;w,b)}
l(w,b)=i=1∑mlnp(yi∣xi;w,b)
线性判别分析LDA(二分类)
- 给定训练样例集,设法将样例投影到一条直线上, 使得同类样例的投影点尽可能接近、异类样例的投影点尽可能远离;在对新样 本进行分类时,将其投影到同样的这条直线上,再根据投影点的位置来确定新样本的类别
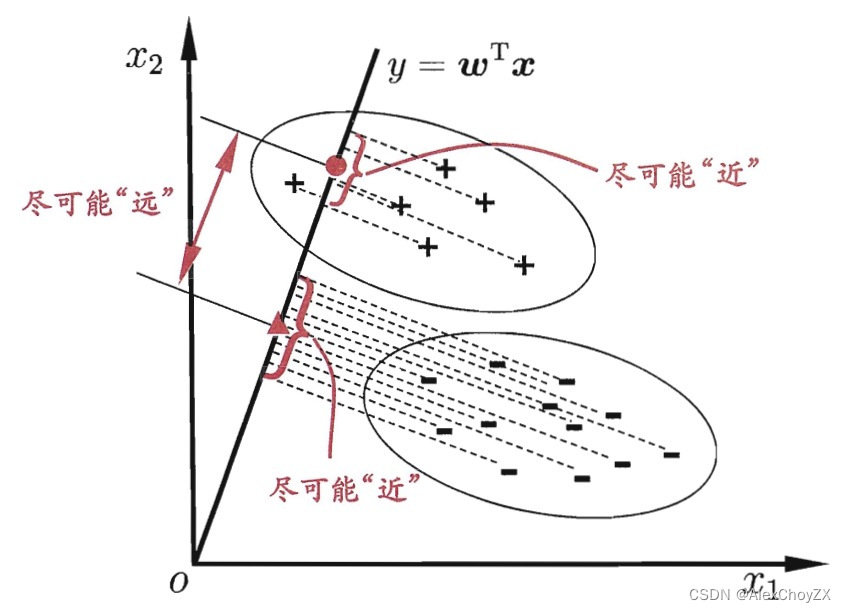
- 符号设定
- 数据集: D = { ( x i , y i ) } i = 1 m , y i ∈ { 0 , 1 } D=\{(x_i,y_i)\}_{i=1}^m,y_i\in\{0,1\} D={(xi,yi)}i=1m,yi∈{0,1}
- 第 i ∈ { 0 , 1 } i\in\{0,1\} i∈{0,1}类示例的集合: X i X_i Xi
- 第 i ∈ { 0 , 1 } i\in\{0,1\} i∈{0,1}类示例的均值向量: μ i \mu_i μi
- 第 i ∈ { 0 , 1 } i\in\{0,1\} i∈{0,1}类示例的协方差矩阵: Σ i \Sigma_i Σi
- 投影到直线
w
w
w 上
- 两类样本中心的投影: w T μ 0 , w T μ 1 w^T\mu_0,w^T\mu_1 wTμ0,wTμ1
- 两类样本所有投影的协方差: w T Σ 0 w , w T Σ 1 w w^T\Sigma_0w,w^T\Sigma_1w wTΣ0w,wTΣ1w
- 类内散度矩阵: S w = Σ 0 + Σ 1 = ∑ x ∈ X 0 ( x − μ 0 ) ( x − μ 0 ) T + ∑ x ∈ X 1 ( x − μ 1 ) ( x − μ 1 ) T S_w=\Sigma_0+\Sigma_1=\sum\limits_{x\in X_0}(x-\mu_0)(x-\mu_0)^T+\sum\limits_{x\in X_1}(x-\mu_1)(x-\mu_1)^T Sw=Σ0+Σ1=x∈X0∑(x−μ0)(x−μ0)T+x∈X1∑(x−μ1)(x−μ1)T
- 类间散度矩阵: S b = ( μ 0 − μ 1 ) ( μ 0 − μ 1 ) T S_b=(\mu_0-\mu_1)(\mu_0-\mu_1)^T Sb=(μ0−μ1)(μ0−μ1)T
- 目标函数
- 同类样例的投影点尽可能接近: w T Σ 0 w + w T Σ 1 w w^T\Sigma_0w+w^T\Sigma_1w wTΣ0w+wTΣ1w尽可能小
- 异类样例的投影点尽可能远离: ∥ w T μ 0 − w T μ 1 ∥ 2 2 \Vert w^T\mu_0-w^T\mu_1\Vert_2^2 ∥wTμ0−wTμ1∥22尽可能大
- 同时考虑两者:最大化广义瑞利商
- max w J = max w ∥ w T μ 0 − w T μ 1 ∥ 2 2 w T Σ 0 w + w T Σ 1 w = max w w T ( μ 0 − μ 1 ) ( μ 0 − μ 1 ) T w w T ( Σ 0 + Σ 1 ) w = max w w T S b w w T S w w \max\limits_{w}J=\max\limits_{w}\frac{\Vert w^T\mu_0-w^T\mu_1\Vert_2^2}{w^T\Sigma_0w+w^T\Sigma_1w}=\max\limits_{w}\frac{w^T(\mu_0-\mu_1)(\mu_0-\mu_1)^Tw}{w^T(\Sigma_0+\Sigma_1)w}=\max\limits_{w}\frac{w^TS_bw}{w^TS_ww} wmaxJ=wmaxwTΣ0w+wTΣ1w∥wTμ0−wTμ1∥22=wmaxwT(Σ0+Σ1)wwT(μ0−μ1)(μ0−μ1)Tw=wmaxwTSwwwTSbw
- 等价于 { min w − w T S b w s . t . w T S w w = 1 \left\{ \begin{aligned} \min\limits_{w}-w^TS_bw \\ s.t. \quad w^TS_ww=1 \end{aligned} \right. ⎩ ⎨ ⎧wmin−wTSbws.t.wTSww=1
- 拉格朗日乘子法
- 拉格朗日函数: L ( w , λ ) = − w T S b w + λ ( w T S w w − 1 ) L(w, λ) = −w^TS_bw + λ(w^TS_ww − 1) L(w,λ)=−wTSbw+λ(wTSww−1)
- 解得:
S
b
w
=
λ
S
w
w
S_bw = λS_ww
Sbw=λSww
- 即: ( μ 0 − μ 1 ) ( μ 0 − μ 1 ) T w = λ S w w 即:(\mu_0-\mu_1)(\mu_0-\mu_1)^Tw=λS_ww 即:(μ0−μ1)(μ0−μ1)Tw=λSww
- 即: w = ( μ 0 − μ 1 ) T w λ S w − 1 ( μ 0 − μ 1 ) 即:w=\frac{(\mu_0-\mu_1)^Tw}{λ}S_w^{-1}(\mu_0-\mu_1) 即:w=λ(μ0−μ1)TwSw−1(μ0−μ1)
- 由于广义瑞利商 J J J 的分子分母均为关于 w w w 的二次项,因此不关心 w w w 的大小,只关心其方向。通过调整 w w w 的大小使得标量 ( μ 0 − μ 1 ) T w = λ (\mu_0-\mu_1)^Tw = λ (μ0−μ1)Tw=λ,得: w = S w − 1 ( μ 0 − μ 1 ) w=S_w^{-1}(\mu_0-\mu_1) w=Sw−1(μ0−μ1)
- 奇异值分解
- S w = U Σ V T S_w=U\Sigma V^T Sw=UΣVT
- S w − 1 = U Σ − 1 V T S_w^{-1}=U\Sigma^{-1} V^T Sw−1=UΣ−1VT
多分类学习
将LDA推广到多分类任务
- 符号设定
- 假设存在 N N N 个类,其中第 i i i 类示例数为 m i m_i mi
- 所有示例的均值向量: μ \mu μ
- 类内散度矩阵:
S
w
=
∑
i
=
1
N
S
w
i
S_w=\sum\limits_{i=1}^NS_{w_i}
Sw=i=1∑NSwi
- S w i = ∑ x ∈ X i ( x i − μ i ) ( x i − μ i ) T S_{w_i}=\sum\limits_{x\in X_i}(x_i-\mu_i)(x_i-\mu_i)^T Swi=x∈Xi∑(xi−μi)(xi−μi)T
- 全局散度矩阵: S t = ∑ i = 1 m ( x i − μ ) ( x i − μ ) T S_t=\sum\limits_{i=1}^m(x_i-\mu)(x_i-\mu)^T St=i=1∑m(xi−μ)(xi−μ)T
- 类间散度矩阵: S b = S t − S w = ∑ i = 1 N m i ( μ i − μ ) ( μ i − μ ) T S_b=S_t-S_w=\sum\limits_{i=1}^Nm_i(\mu_i-\mu)(\mu_i-\mu)^T Sb=St−Sw=i=1∑Nmi(μi−μ)(μi−μ)T
- 目标函数
-
max
W
∑
i
=
1
N
−
1
w
i
T
S
b
w
i
∑
i
=
1
N
−
1
w
i
T
S
w
w
i
=
max
W
t
r
(
W
T
S
b
W
)
t
r
(
W
T
S
w
W
)
\max\limits_{W}\frac{\sum\limits_{i=1}^{N-1} w_i^TS_bw_i}{\sum\limits_{i=1}^{N-1} w_i^TS_ww_i}=\max\limits_{W}\frac{tr(W^TS_bW)}{tr(W^TS_wW)}
Wmaxi=1∑N−1wiTSwwii=1∑N−1wiTSbwi=Wmaxtr(WTSwW)tr(WTSbW)
- 其中 W = ( w 1 , w 2 , . . . , w N − 1 ) ∈ R d × ( N − 1 ) W=(w_1,w_2,...,w_{N-1})\in\mathbb{R}^{d\times(N-1)} W=(w1,w2,...,wN−1)∈Rd×(N−1)
- 等价于: { min W − t r ( W T S b W ) s . t . t r ( W T S w W ) = 1 \left\{ \begin{aligned} \min\limits_{W}-tr(W^TS_bW) \\ s.t. \quad tr(W^TS_wW) =1 \end{aligned} \right. ⎩ ⎨ ⎧Wmin−tr(WTSbW)s.t.tr(WTSwW)=1
- 另一种常见的优化目标形式: max W ∏ i = 1 N − 1 w i T S b w i ∏ i = 1 N − 1 w i T S w w i = max W ∏ i = 1 N − 1 w i T S b w i w i T S w w i \max\limits_{W}\frac{\prod\limits_{i=1}^{N-1} w_i^TS_bw_i}{\prod\limits_{i=1}^{N-1} w_i^TS_ww_i}=\max\limits_{W}\prod\limits_{i=1}^{N-1}\frac{ w_i^TS_bw_i}{w_i^TS_ww_i} Wmaxi=1∏N−1wiTSwwii=1∏N−1wiTSbwi=Wmaxi=1∏N−1wiTSwwiwiTSbwi
-
max
W
∑
i
=
1
N
−
1
w
i
T
S
b
w
i
∑
i
=
1
N
−
1
w
i
T
S
w
w
i
=
max
W
t
r
(
W
T
S
b
W
)
t
r
(
W
T
S
w
W
)
\max\limits_{W}\frac{\sum\limits_{i=1}^{N-1} w_i^TS_bw_i}{\sum\limits_{i=1}^{N-1} w_i^TS_ww_i}=\max\limits_{W}\frac{tr(W^TS_bW)}{tr(W^TS_wW)}
Wmaxi=1∑N−1wiTSwwii=1∑N−1wiTSbwi=Wmaxtr(WTSwW)tr(WTSbW)
- 拉格朗日乘子法
- 拉格朗日函数:
L
(
W
,
λ
)
=
−
t
r
(
W
T
S
b
W
)
+
λ
[
t
r
(
W
T
S
w
W
)
−
1
]
L(W,\lambda)=-tr(W^TS_bW)+\lambda[tr(W^TS_wW) -1]
L(W,λ)=−tr(WTSbW)+λ[tr(WTSwW)−1]
- 解得: S b W = λ S w W S_bW = λS_wW SbW=λSwW
- W W W 的闭式解是 S w − 1 S b S_w^{-1}S_b Sw−1Sb的 N − 1 N-1 N−1 个最大广义特征值所对应的特征向量组成的矩阵。但此处并不能直观地解释为什么要这么构造,因此改用下面的拉格朗日函数求解。
- 拉格朗日函数:
L
(
W
,
Λ
)
=
−
t
r
(
W
T
S
b
W
)
+
t
r
[
Λ
(
W
T
S
w
W
−
I
)
]
L(W,Λ)=−tr(W^TS_bW)+tr [Λ(W^TS_wW−I)]
L(W,Λ)=−tr(WTSbW)+tr[Λ(WTSwW−I)]
- 其中: I ∈ R ( N − 1 ) × ( N − 1 ) I\in\mathbb{R}^{(N-1)\times(N-1)} I∈R(N−1)×(N−1) 为单位矩阵; Λ = d i a g ( λ 1 , λ 2 , . . . , λ N − 1 ) ∈ R ( N − 1 ) × ( N − 1 ) Λ=diag(\lambda_1,\lambda_2,...,\lambda_{N-1})\in\mathbb{R}^{(N-1)\times(N-1)} Λ=diag(λ1,λ2,...,λN−1)∈R(N−1)×(N−1) 是由 N − 1 N−1 N−1 个拉格朗日乘子构成的对角矩阵
- 解得:
S
b
W
=
S
w
W
Λ
S_bW = S_wWΛ
SbW=SwWΛ;
- 展开得: S b w i = λ i S w w i , i = 1 , 2 , . . . , N − 1 S_bw_i =λ_iS_ww_i, i=1,2,...,N−1 Sbwi=λiSwwi,i=1,2,...,N−1
- λ i λ_i λi对应的是广义特征值, w i w_i wi 是 λ i λ_i λi 所对应的特征向量
- 代回目标函数:
- min W − t r ( W T S b W ) = max W t r ( W T S b W ) = max W ∑ i = 1 N − 1 w i T S b w i = max W ∑ i = 1 N − 1 λ i w i T S w w i \min\limits_{W}-tr(W^TS_bW)=\max\limits_{W}tr(W^TS_bW)=\max\limits_{W}\sum\limits_{i=1}^{N-1}w_i^TS_bw_i=\max\limits_{W}\sum\limits_{i=1}^{N-1}λ_iw_i^TS_ww_i Wmin−tr(WTSbW)=Wmaxtr(WTSbW)=Wmaxi=1∑N−1wiTSbwi=Wmaxi=1∑N−1λiwiTSwwi
- 又: t r ( W T S w W ) = ∑ i = 1 N − 1 w i T S w w i = 1 tr(W^TS_wW) =\sum\limits_{i=1}^{N-1}w_i^TS_ww_i= 1 tr(WTSwW)=i=1∑N−1wiTSwwi=1,故在这 N − 1 N-1 N−1 个 λ i \lambda_i λi 都取最大值时上式取最大值
- 对于 w i w_i wi 的实际个数及相关证明,见南瓜书
- 拉格朗日函数:
L
(
W
,
λ
)
=
−
t
r
(
W
T
S
b
W
)
+
λ
[
t
r
(
W
T
S
w
W
)
−
1
]
L(W,\lambda)=-tr(W^TS_bW)+\lambda[tr(W^TS_wW) -1]
L(W,λ)=−tr(WTSbW)+λ[tr(WTSwW)−1]
拆解法
- 将多分类任务拆为若干个二分类任务求解
- 先对问题进行拆分,然后为拆出的每个二分类任务训练一个分类器
- 在测试时,对这些分类器的预测结果进行集成以获得最终的多分类结果
- 考虑 N N N 个类别 C 1 , C 2 , . . . , C N C_1,C_2,...,C_N C1,C2,...,CN,给定数据集 D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x m , y m ) } , y i ∈ { C 1 , C 2 , . . . , C N } D=\{(x_1,y_1),(x_2,y_2),...,(x_m,y_m)\},y_i\in\{C_1,C_2,...,C_N\} D={(x1,y1),(x2,y2),...,(xm,ym)},yi∈{C1,C2,...,CN}
- 一对一:One vs One,简称 OvO
- 将这 N N N 个类别两两配对,从而产生 N ( N − 1 ) / 2 N(N-1)/2 N(N−1)/2 个二分类任务
- OvO 将为区分类别 C i C_i Ci和 C j C_j Cj,训练一个分类器,该分类器把 D D D 中的 C i C_i Ci 类样例作为正例, C j C_j Cj 类样例作为反例
- 在测试阶段,新样本将同时提交给所有分类器,将得到 N ( N − 1 ) / 2 N(N-1)/2 N(N−1)/2 个分类结果
- 最终结果通过投票产生:即把被预测得最多的类别作为最终分类结果
- 一对其余:One vs Rest,简称 OvR
- OvR每次将一个类的样例作为正例、所有其他类的样例作为反例来训练 N N N 个分类器
- 在测试时若仅有一个分类器预测为正类,则对应的类别标记作为最终分类结果
- 若有多个分类器预测为正类,则通常考虑各分类器的预测置信度,选择置信度最大的类别标记作为分类结果
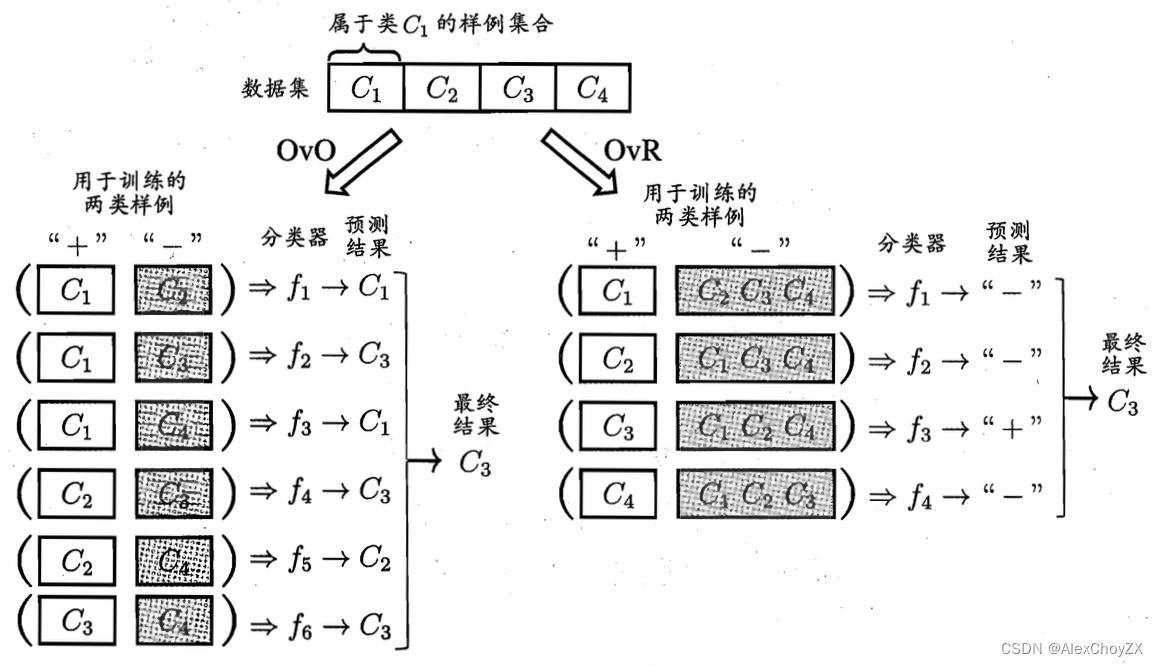
- 多对多:Many vs Many,简称 MvM
- MvM 是每次将若干个类作为正类,若干个其他类作为反类
- OvO 和OvR 是 MvM 的特例
- MvM 的正、反类构造必须有特殊的设计,不能随意选取
类别不平衡问题
- 如果不同类别的训练样例数目稍有差别,通常影响不大,但若差别很大,则会对学习过程造成困扰。类别不平衡(clas s-imbal ance)就是指分类任务中不同类别的训练样例数目差别很大的情况
- 再缩放
- 几率 y 1 − y \frac{y}{1-y} 1−yy 反映了正例可能性与反例可能性之比值
- 阈值设置为 0.5 0.5 0.5 表明分类器认为真实正、反例可能性相同:分类器决策规则为 若 y 1 − y > 1 则预测为正例 若\frac{y}{1-y}>1则预测为正例 若1−yy>1则预测为正例
- 当训练集中正、反例的数目不同时,令 m + m+ m+ 表示正例数目, m − m- m−表示反例数目,则观测几率是 m + m − \frac{m^+}{m^-} m−m+ ,假设训练集是真实样本总体的无偏采样,因此观测几率就代表了真实几率。于是,只要分类器的预测几率高于观测几率就应判定为正例: 若 y 1 − y > m + m − ,即 y ′ 1 − y ′ = y 1 − y × m − m + > 1 则预测为正例 若\frac{y}{1-y}>\frac{m^+}{m^-},即\frac{y'}{1-y'}=\frac{y}{1-y}\times\frac{m^-}{m^+}>1则预测为正例 若1−yy>m−m+,即1−y′y′=1−yy×m+m−>1则预测为正例
- 推断
m
+
m
−
\frac{m^+}{m^-}
m−m+ 的方法
- 欠采样
- 去除一些反例使得正、反例数目接近,然后再进行学习
- 过采样
- 增加一些正例使得正、反例数目接近,然后再进行学习
- 阈值异动
- 直接基于原始训练集进行学习,但在用训练好的分类器进行预测时,将 y ′ 1 − y ′ = y 1 − y × m − m + \frac{y'}{1-y'}=\frac{y}{1-y}\times\frac{m^-}{m^+} 1−y′y′=1−yy×m+m− 嵌入到其决策过程中
- 对比
- 欠采样法的时间开销通常远小于过采样法,因为前者丢弃了很多反例,使得分类器训练集远小于初始训练集,而过采样法增加了很多正例,其训练集大于初始训练集
- 过采样法不能简单地对初始正例样本进行重复采样,否则会招致严重的过拟合;过采样法的代表性算法 SMOTE 是通过对训练集里的正例进行插值来产生额外的正例
- 欠采样法若随机丢弃反例,可能丢失一些重要信息;欠采样法的代表性算法EasyEnsemble 是利用集成学习机制,将反例划分为若干个集合供不同学习器使用,这样对每个学习器来看都进行了欠采样,但在全局来看却不会丢失重要信息
- 欠采样
习题
西瓜数据集 3.0α
| 编号 | 色泽 | 根蒂 | 敲声 | 纹理 | 脐部 | 触感 | 密度 | 含糖率 | 好瓜 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 青绿 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 0.697 | 0.46 | 是 |
| 2 | 乌黑 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 硬滑 | 0.774 | 0.376 | 是 |
| 3 | 乌黑 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 0.634 | 0.264 | 是 |
| 4 | 青绿 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 硬滑 | 0.608 | 0.318 | 是 |
| 5 | 浅白 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 0.556 | 0.215 | 是 |
| 6 | 青绿 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 软粘 | 0.403 | 0.237 | 是 |
| 7 | 乌黑 | 稍蜷 | 浊响 | 稍糊 | 稍凹 | 软粘 | 0.481 | 0.149 | 是 |
| 8 | 乌黑 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 硬滑 | 0.437 | 0.211 | 是 |
| 9 | 乌黑 | 稍蜷 | 沉闷 | 稍糊 | 稍凹 | 硬滑 | 0.666 | 0.091 | 否 |
| 10 | 青绿 | 硬挺 | 清脆 | 清晰 | 平坦 | 软粘 | 0.243 | 0.267 | 否 |
| 11 | 浅白 | 硬挺 | 清脆 | 模糊 | 平坦 | 硬滑 | 0.245 | 0.057 | 否 |
| 12 | 浅白 | 蜷缩 | 浊响 | 模糊 | 平坦 | 软粘 | 0.343 | 0.099 | 否 |
| 13 | 青绿 | 稍蜷 | 浊响 | 稍糊 | 凹陷 | 硬滑 | 0.639 | 0.161 | 否 |
| 14 | 浅白 | 稍蜷 | 沉闷 | 稍糊 | 凹陷 | 硬滑 | 0.657 | 0.198 | 否 |
| 15 | 乌黑 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 软粘 | 0.36 | 0.37 | 否 |
| 16 | 浅白 | 蜷缩 | 浊响 | 模糊 | 平坦 | 硬滑 | 0.593 | 0.042 | 否 |
| 17 | 青绿 | 蜷缩 | 沉闷 | 稍糊 | 稍凹 | 硬滑 | 0.719 | 0.103 | 否 |
3.2.编程实现对率回归,并给出西瓜数据集 3.0α 上的结果
'''
与原书不同,原书中一个样本xi 为列向量,本代码中一个样本xi为行向量
尝试了两种优化方法,梯度下降和牛顿法。两者结果基本相同,不过有时因初始化的原因,
会导致牛顿法中海森矩阵为奇异矩阵,np.linalg.inv(hess)会报错。以后有机会再写拟牛顿法吧。
'''
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
from sklearn import linear_model
def sigmoid(x):
s = 1 / (1 + np.exp(-x))
return s
def J_cost(X, y, beta):
'''
:param X: sample array, shape(n_samples, n_features)
:param y: array-like, shape (n_samples,)
:param beta: the beta in formula 3.27 , shape(n_features + 1, ) or (n_features + 1, 1)
:return: the result of formula 3.27
'''
X_hat = np.c_[X, np.ones((X.shape[0], 1))]
beta = beta.reshape(-1, 1)
y = y.reshape(-1, 1)
Lbeta = -y * np.dot(X_hat, beta) + np.log(1 + np.exp(np.dot(X_hat, beta)))
return Lbeta.sum()
def gradient(X, y, beta):
'''
compute the first derivative of J(i.e. formula 3.27) with respect to beta i.e. formula 3.30
----------------------------------
:param X: sample array, shape(n_samples, n_features)
:param y: array-like, shape (n_samples,)
:param beta: the beta in formula 3.27 , shape(n_features + 1, ) or (n_features + 1, 1)
:return:
'''
X_hat = np.c_[X, np.ones((X.shape[0], 1))]
beta = beta.reshape(-1, 1)
y = y.reshape(-1, 1)
p1 = sigmoid(np.dot(X_hat, beta))
gra = (-X_hat * (y - p1)).sum(0)
return gra.reshape(-1, 1)
def hessian(X, y, beta):
'''
compute the second derivative of J(i.e. formula 3.27) with respect to beta i.e. formula 3.31
----------------------------------
:param X: sample array, shape(n_samples, n_features)
:param y: array-like, shape (n_samples,)
:param beta: the beta in formula 3.27 , shape(n_features + 1, ) or (n_features + 1, 1)
:return:
'''
X_hat = np.c_[X, np.ones((X.shape[0], 1))]
beta = beta.reshape(-1, 1)
y = y.reshape(-1, 1)
p1 = sigmoid(np.dot(X_hat, beta))
m, n = X.shape
P = np.eye(m) * p1 * (1 - p1)
assert P.shape[0] == P.shape[1]
return np.dot(np.dot(X_hat.T, P), X_hat)
def update_parameters_gradDesc(X, y, beta, learning_rate, num_iterations, print_cost):
'''
update parameters with gradient descent method
--------------------------------------------
:param beta:
:param grad:
:param learning_rate:
:return:
'''
for i in range(num_iterations):
grad = gradient(X, y, beta)
beta = beta - learning_rate * grad
if (i % 10 == 0) & print_cost:
print('{}th iteration, cost is {}'.format(i, J_cost(X, y, beta)))
return beta
def update_parameters_newton(X, y, beta, num_iterations, print_cost):
'''
update parameters with Newton method
:param beta:
:param grad:
:param hess:
:return:
'''
for i in range(num_iterations):
grad = gradient(X, y, beta)
hess = hessian(X, y, beta)
beta = beta - np.dot(np.linalg.inv(hess), grad)
if (i % 10 == 0) & print_cost:
print('{}th iteration, cost is {}'.format(i, J_cost(X, y, beta)))
return beta
def initialize_beta(n):
beta = np.random.randn(n + 1, 1) * 0.5 + 1
return beta
def logistic_model(X, y, num_iterations=100, learning_rate=1.2, print_cost=False, method='gradDesc'):
'''
:param X:
:param y:~
:param num_iterations:
:param learning_rate:
:param print_cost:
:param method: str 'gradDesc' or 'Newton'
:return:
'''
m, n = X.shape
beta = initialize_beta(n)
if method == 'gradDesc':
return update_parameters_gradDesc(X, y, beta, learning_rate, num_iterations, print_cost)
elif method == 'Newton':
return update_parameters_newton(X, y, beta, num_iterations, print_cost)
else:
raise ValueError('Unknown solver %s' % method)
def predict(X, beta):
X_hat = np.c_[X, np.ones((X.shape[0], 1))]
p1 = sigmoid(np.dot(X_hat, beta))
p1[p1 >= 0.5] = 1
p1[p1 < 0.5] = 0
return p1
if __name__ == '__main__':
data_path = r'C:\Users\hanmi\Documents\xiguabook\watermelon3_0_Ch.csv'
#
data = pd.read_csv(data_path).values
is_good = data[:, 9] == '是'
is_bad = data[:, 9] == '否'
X = data[:, 7:9].astype(float)
y = data[:, 9]
y[y == '是'] = 1
y[y == '否'] = 0
y = y.astype(int)
plt.scatter(data[:, 7][is_good], data[:, 8][is_good], c='k', marker='o')
plt.scatter(data[:, 7][is_bad], data[:, 8][is_bad], c='r', marker='x')
plt.xlabel('密度')
plt.ylabel('含糖量')
# 可视化模型结果
beta = logistic_model(X, y, print_cost=True, method='gradDesc', learning_rate=0.3, num_iterations=1000)
w1, w2, intercept = beta
x1 = np.linspace(0, 1)
y1 = -(w1 * x1 + intercept) / w2
ax1, = plt.plot(x1, y1, label=r'my_logistic_gradDesc')
lr = linear_model.LogisticRegression(solver='lbfgs', C=1000) # 注意sklearn的逻辑回归中,C越大表示正则化程度越低。
lr.fit(X, y)
lr_beta = np.c_[lr.coef_, lr.intercept_]
print(J_cost(X, y, lr_beta))
# 可视化sklearn LogisticRegression 模型结果
w1_sk, w2_sk = lr.coef_[0, :]
x2 = np.linspace(0, 1)
y2 = -(w1_sk * x2 + lr.intercept_) / w2
ax2, = plt.plot(x2, y2, label=r'sklearn_logistic')
plt.legend(loc='upper right')
plt.show()
3.3.选择两个 UCI数据集,比较 10 折交叉验证法和留一法所估计出的对率回归的错误率
import numpy as np
from sklearn import linear_model
from sklearn.model_selection import LeaveOneOut
from sklearn.model_selection import cross_val_score
data_path = r'C:\Users\hanmi\Documents\xiguabook\Transfusion.txt'
data = np.loadtxt(data_path, delimiter=',').astype(int)
X = data[:, :4]
y = data[:, 4]
m, n = X.shape
# normalization
X = (X - X.mean(0)) / X.std(0)
# shuffle
index = np.arange(m)
np.random.shuffle(index)
X = X[index]
y = y[index]
# 使用sklarn 中自带的api先
# k-10 cross validation
lr = linear_model.LogisticRegression(C=2)
score = cross_val_score(lr, X, y, cv=10)
print(score.mean())
# LOO
loo = LeaveOneOut()
accuracy = 0
for train, test in loo.split(X, y):
lr_ = linear_model.LogisticRegression(C=2)
X_train = X[train]
X_test = X[test]
y_train = y[train]
y_test = y[test]
lr_.fit(X_train, y_train)
accuracy += lr_.score(X_test, y_test)
print(accuracy / m)
# 两者结果几乎一样
# 自己写一个试试
# k-10
# 这里就没考虑最后几个样本了。
num_split = int(m / 10)
score_my = []
for i in range(10):
lr_ = linear_model.LogisticRegression(C=2)
test_index = range(i * num_split, (i + 1) * num_split)
X_test_ = X[test_index]
y_test_ = y[test_index]
X_train_ = np.delete(X, test_index, axis=0)
y_train_ = np.delete(y, test_index, axis=0)
lr_.fit(X_train_, y_train_)
score_my.append(lr_.score(X_test_, y_test_))
print(np.mean(score_my))
# LOO
score_my_loo = []
for i in range(m):
lr_ = linear_model.LogisticRegression(C=2)
X_test_ = X[i, :]
y_test_ = y[i]
X_train_ = np.delete(X, i, axis=0)
y_train_ = np.delete(y, i, axis=0)
lr_.fit(X_train_, y_train_)
score_my_loo.append(int(lr_.predict(X_test_.reshape(1, -1)) == y_test_))
print(np.mean(score_my_loo))
# 结果都是类似
3.4.编程实现线性判别分析,并给出西瓜数据集 3.0a 上的结果
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
class LDA(object):
def fit(self, X_, y_, plot_=False):
pos = y_ == 1
neg = y_ == 0
X0 = X_[neg]
X1 = X_[pos]
u0 = X0.mean(0, keepdims=True) # (1, n)
u1 = X1.mean(0, keepdims=True)
sw = np.dot((X0 - u0).T, X0 - u0) + np.dot((X1 - u1).T, X1 - u1)
w = np.dot(np.linalg.inv(sw), (u0 - u1).T).reshape(1, -1) # (1, n)
if plot_:
fig, ax = plt.subplots()
ax.spines['right'].set_color('none')
ax.spines['top'].set_color('none')
ax.spines['left'].set_position(('data', 0))
ax.spines['bottom'].set_position(('data', 0))
plt.scatter(X1[:, 0], X1[:, 1], c='k', marker='o', label='good')
plt.scatter(X0[:, 0], X0[:, 1], c='r', marker='x', label='bad')
plt.xlabel('密度', labelpad=1)
plt.ylabel('含糖量')
plt.legend(loc='upper right')
x_tmp = np.linspace(-0.05, 0.15)
y_tmp = x_tmp * w[0, 1] / w[0, 0]
plt.plot(x_tmp, y_tmp, '#808080', linewidth=1)
wu = w / np.linalg.norm(w)
# 正负样板店
X0_project = np.dot(X0, np.dot(wu.T, wu))
plt.scatter(X0_project[:, 0], X0_project[:, 1], c='r', s=15)
for i in range(X0.shape[0]):
plt.plot([X0[i, 0], X0_project[i, 0]], [X0[i, 1], X0_project[i, 1]], '--r', linewidth=1)
X1_project = np.dot(X1, np.dot(wu.T, wu))
plt.scatter(X1_project[:, 0], X1_project[:, 1], c='k', s=15)
for i in range(X1.shape[0]):
plt.plot([X1[i, 0], X1_project[i, 0]], [X1[i, 1], X1_project[i, 1]], '--k', linewidth=1)
# 中心点的投影
u0_project = np.dot(u0, np.dot(wu.T, wu))
plt.scatter(u0_project[:, 0], u0_project[:, 1], c='#FF4500', s=60)
u1_project = np.dot(u1, np.dot(wu.T, wu))
plt.scatter(u1_project[:, 0], u1_project[:, 1], c='#696969', s=60)
ax.annotate(r'u0 投影点',
xy=(u0_project[:, 0], u0_project[:, 1]),
xytext=(u0_project[:, 0] - 0.2, u0_project[:, 1] - 0.1),
size=13,
va="center", ha="left",
arrowprops=dict(arrowstyle="->",
color="k",
)
)
ax.annotate(r'u1 投影点',
xy=(u1_project[:, 0], u1_project[:, 1]),
xytext=(u1_project[:, 0] - 0.1, u1_project[:, 1] + 0.1),
size=13,
va="center", ha="left",
arrowprops=dict(arrowstyle="->",
color="k",
)
)
plt.axis("equal") # 两坐标轴的单位刻度长度保存一致
plt.show()
self.w = w
self.u0 = u0
self.u1 = u1
return self
def predict(self, X):
project = np.dot(X, self.w.T)
wu0 = np.dot(self.w, self.u0.T)
wu1 = np.dot(self.w, self.u1.T)
return (np.abs(project - wu1) < np.abs(project - wu0)).astype(int)
if __name__ == '__main__':
data_path = r'C:\Users\hanmi\Documents\xiguabook\watermelon3_0_Ch.csv'
data = pd.read_csv(data_path).values
X = data[:, 7:9].astype(float)
y = data[:, 9]
y[y == '是'] = 1
y[y == '否'] = 0
y = y.astype(int)
lda = LDA()
lda.fit(X, y, plot_=True)
print(lda.predict(X)) # 和逻辑回归的结果一致
print(y)















 421
421

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









