







目录
自从chatGPT掀起的AI大模型热潮以来,国内大模型研究的开源活动进展也如火如荼,模型需要群众的打磨。
本实战专栏将评估一系列的开源模型,尤其关注国产大模型,重点在于可私有化、轻量化部署,比如推理所需的GPU资源控制在24G显存内。
一、百川2(Baichuan 2)模型介绍
百川自身宣称介绍如下:
-
Baichuan 2 是百川智能推出的新一代开源大语言模型,采用 2.6 万亿 Tokens 的高质量语料训练。
-
Baichuan 2 在多个权威的中文、英文和多语言的通用、领域 测试集benchmark 上取得同尺寸最佳的效果。
-
本次发布包含有 7B、13B 的 Base 和 Chat 版本,并提供了 Chat 版本的 4bits 量化。
-
所有版本对学术研究完全开放。同时,开发者通过邮件申请并获得官方商用许可后,即可免费商用
免部署的体验:百川大模型-汇聚世界知识 创作妙笔生花-百川智能
二、资源需求
模型文件类型
7B模型,又分为基座,对齐,对齐的4bits量化模型3个子类型。
13B模型,又分为基座,对齐,对齐的4bits量化模型3个子类型。
一共6种类型,可根据自身情况选择。
推理的GPU资源要求
| 类型 | base | chat | chat-4bits |
|---|---|---|---|
| 13B | 27.5G | 27.5G | 8.6G |
| 7B | 15.3G | 15.3G | 5.1G |
模型获取途径
下载链接:
国外: Huggingface
Baichuan2-13B-Base : https://huggingface.co/baichuan-inc/Baichuan2-13B-Base
国内:ModelScope
Baichuan2-13B-Base : 百川2-13B-预训练模型
三、部署安装
配置环境
ubuntu 20.04
python 3.10版本,推荐3.8以上版本
pytorch 2.01,推荐2.0及以上版本
CUDA 11.4,建议使用11.4及以上版本
安装过程
创建虚拟环境
conda create -n baichuan python==3.10.6 -y conda activate baichuan
安装Baichuan2 依赖配套软件
git clone --recursive https://github.com/baichuan-inc/Baichuan2.git; pip install -r requirements.txt
下载模型文件
推理所需的模型权重、源码、配置已发布在 Hugging Face,见上面的下载链接。
模型权重可以手动下载,程序代码也会自动从 Hugging Face 下载所需资源。
四、启动 百川2大模型
命令行对话界面
python cli_demo.py
命令行工具是为 Chat 场景设计,因此不支持使用该工具调用 Base 模型。
网页对话页面
streamlit run web_demo.py
依靠 streamlit 运行命令,会在本地启动一个 web 服务,把控制台给出的地址放入浏览器即可访问。网页 demo 工具是为 Chat 场景设计,因此不支持使用该工具调用 Base 模型。
五、功能测试
认识自己问题:你是谁

鸡土同笼问题:鸡兔共有100只,鸡的脚比兔的脚多80只,问鸡与兔各多少只?


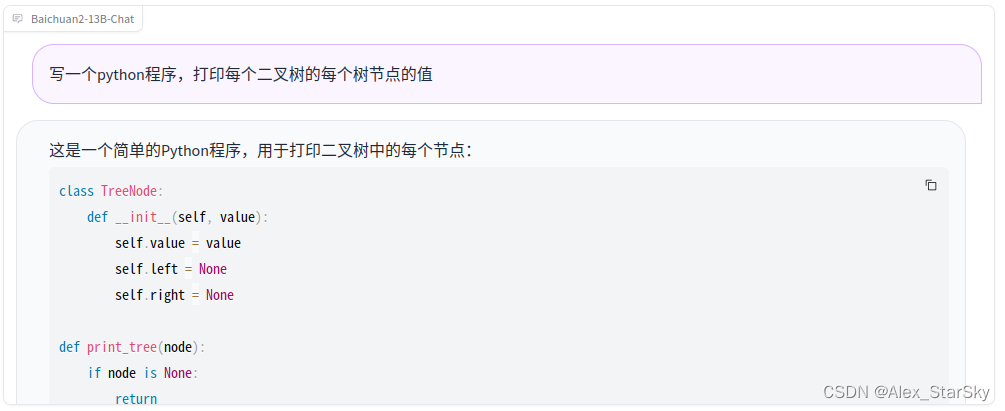
python编程:写一个python程序,打印每个二叉树的每个树节点的值

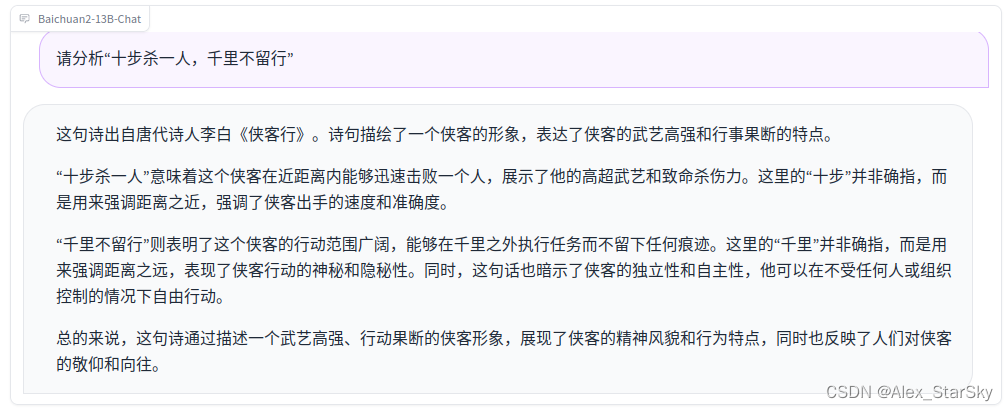
文学题:请分析“十步杀一人,千里不留行”
点个赞 点个赞 点个赞
觉得有用 收藏 收藏 收藏
End
LLM专栏文章:
GPT实战系列-ChatGLM3本地部署CUDA11+1080Ti+显卡24G实战方案
GPT实战系列-P-Tuning本地化训练ChatGLM2等LLM模型,到底做了什么?(一)
GPT实战系列-ChatGLM2部署Ubuntu+Cuda11+显存24G实战方案
















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











