







台大李宏毅Machine Learning 2017Fall学习笔记 (1)Introduction of machine Learning
台大李宏毅讲的这门课应该不错,课程链接:
http://blog.csdn.net/Allenlzcoder/article/details/78644733
http://blog.csdn.net/Allenlzcoder/article/details/78644838
现在将第1个视频的笔记记录于此。
机器学习的整体框架如下图:
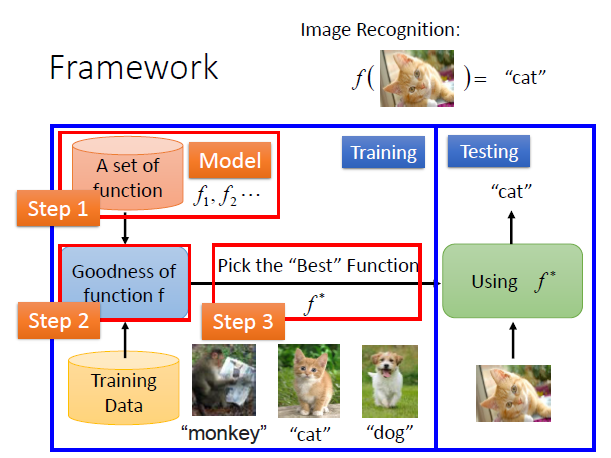
机器学习的步骤很简单,就像把大象装进冰箱里一样简单。主要分为3步:
(1)定义一组函数;(2)评价函数的好坏;(3)选择最好的函数。
这门课的学习图如下所示:
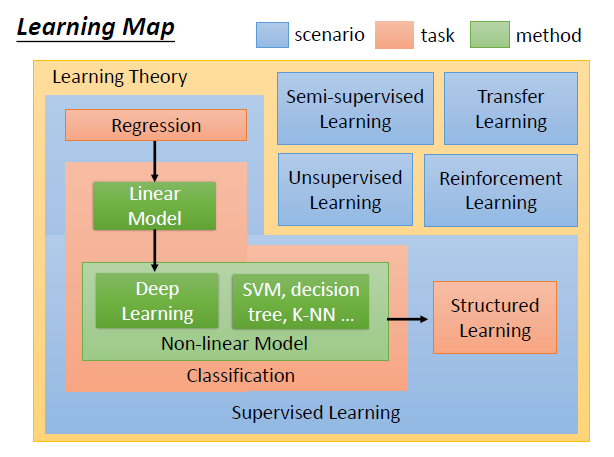
浅蓝色的表示学习情境(scenario),通常使不能选择的。主要分为:1)监督学习;2)半监督学习;3)迁移学习;4)无监督学习;5)增强学习。
学习的任务分为:回归、分类和结构化学习。回归和分类经常听到,结构化学习是未知的暗黑大陆。
学习的方法分为:1)线性模型;2)非线性模型。其中非线性模型包含深度学习和传统机器学习的算法。
先讲一下回归和分类问题。
回归问题的输出是一个标量(或数值),举例如下图。
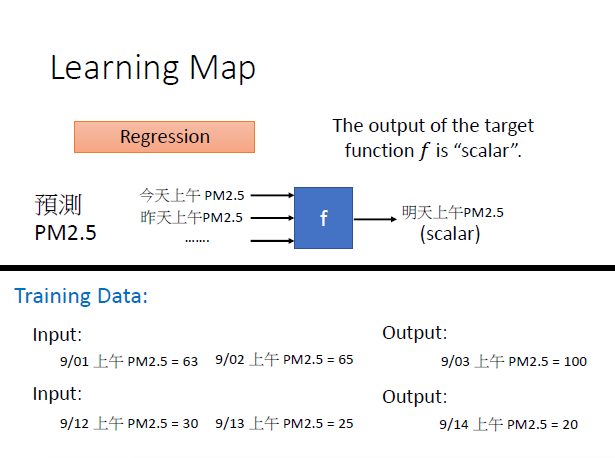
分类问题分为二分类和多分类,输出是label,举例如下。
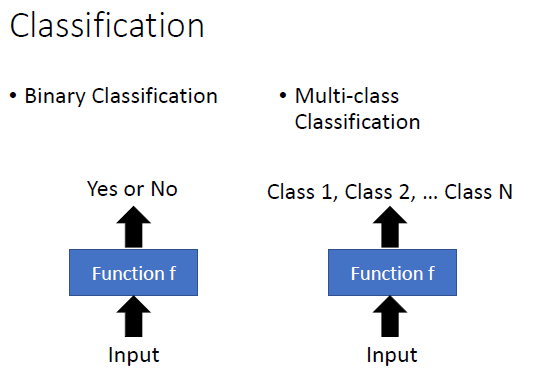
在分类问题中,一些很复杂的问题会使用深度学习的方法,比如图像识别和下围棋等问题。
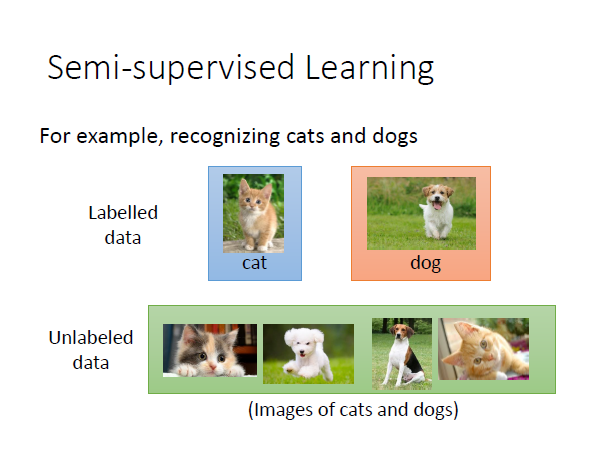
监督学习需要有大量的带标签的训练数据,如果很难收集大量(有一些有标签但不多)的有标签的数据,这种情景更适合用半监督学习。
半监督学习举例如下图:
迁移学习举例如下图:

用不带标签的数据进行学习训练就是无监督学习。
下面重点说下增强学习。
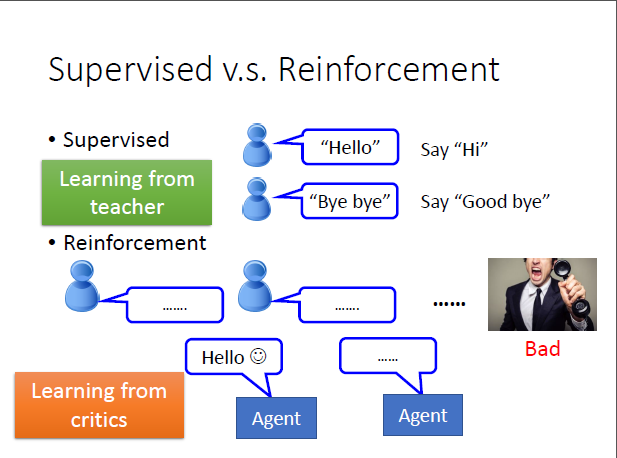
监督学习和增强学习的主要区别在于:
1)监督学习是从老师那里学习。相当于人当家教,手把手的教机器应该怎样做;
2)强化学习是从评价中学习。在强化学习中,未告知机器正确答案,机器所拥有的的只是一个分数,即代表着机器做的好或不好。比如说,刚才机器做错了,但是机器不知道错在哪里,需要机器自己反省检讨。增强学习更符合人类学习的情景。
让增强学习如此出名的原因是因为AlphaGo利用了监督学习和增强学习。
同学们!为了找个好饭碗,让我们为了成为一名优秀的AI训练师而继续前进!奋斗!
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









