






摘要
隐式神经表示在建模动态场景时,模型规模通常很大。为了解决这一问题,本文提出了动态码本这一新的神经表示方法,减少场景自相似性造成的时空冗余,实现以低存储成本表示高保真体积视频。
方法首先合并了相似的模型压缩特征,然后通过一组动态代码来补偿渲染质量的潜在下降。在NHR和DyNeRF数据集上的实验表明,该方法达到了最先进的渲染质量,同时能够实现更高的存储效率。
Introduction
体(Volumetric)视频记录的是动态3D场景的内容,允许用户从任意视点观看捕获的场景,具有广泛的应用范围,如虚拟现实、增强现实等。传统的方法通常将体积视频表示为一组由MVS或深度融合重建而成的有纹理的mesh。这种技术需要复杂、昂贵的硬件以实现较高的重建精度,且应用场景受限。
神经辐射场(NeRF)采用MLP网络预测任意三维点的密度和颜色,并通过体积渲染技术有效地从二维图像中学习模型参数。DyNeRF通过引入时变潜在代码作为MLP网络的附加输入,将NeRF扩展到动态场景,从而使模型能够对场景的每帧内容进行编码,虽然渲染质量令人印象深刻,但训练速度非常慢,例如,DyNeRF需要超过1000个GPU小时来学习一个10秒的体积视频。
为了克服这个问题,一些方法利用显式表示,如特征volume或特征plane来加速训练过程。它们通常在显式结构中存储可学习的特征向量,并使用插值技术进行渲染。通过减少MLP网络中的参数数量,这些方法实现了显著的训练速度。然而,显式表示会占用大的存储,很难扩展到动态3D场景。
一些方法基于场景内部(空间?)相似性降低存储冗余,在静态场景上获得了满意的压缩效果,直接应用于动态场景会导致不可忽视的性能下降。这是因为动态场景的特征冗余不仅反映在空间相关性中,本质上具有很强的时间相关性。有证据表明,当使用特征网格表示3D场景时,99.9%的重要性仅由10%的体素贡献。
因此,本文提出了动态码本这一新的表示方法,用于高效和紧凑的动态三维场景建模。码本的表示可以有效地缓解时间和空间上的代码冗余问题,从而显著减少不必要的存储。但是,这种表示可能会导致某些区域的代码不那么精确,从而降低渲染质量,特别是在动态详细区域。这些区域的空间分布可能会随时间的变化而发生显著的变化。因此,方法分别确定了代码中最必要的部分来优化每个小的时间片段?,并将它们逐步添加到代码本中,以提高这些区域的渲染质量。由于这些区域通常只占场景的一小部分,所以新的代码将不会占用太多的存储空间。
Method
模型输入为由同步和校准的相机捕获的多视图视频,目标是生成一个需要低磁盘存储的容量视频,同时保持高保真渲染的能力。如图所示,本文用多个特征平面来表示使用体积渲染技术从多视点视频中学习到的体视频。模型的主要框架为NeRF,用6个特征平面对动态场景进行建模,其中三个空间平面分别为Pxy、Pxz和Pyz,三个时空平面分别为Pxt、Pyt和Pzt。
Compression
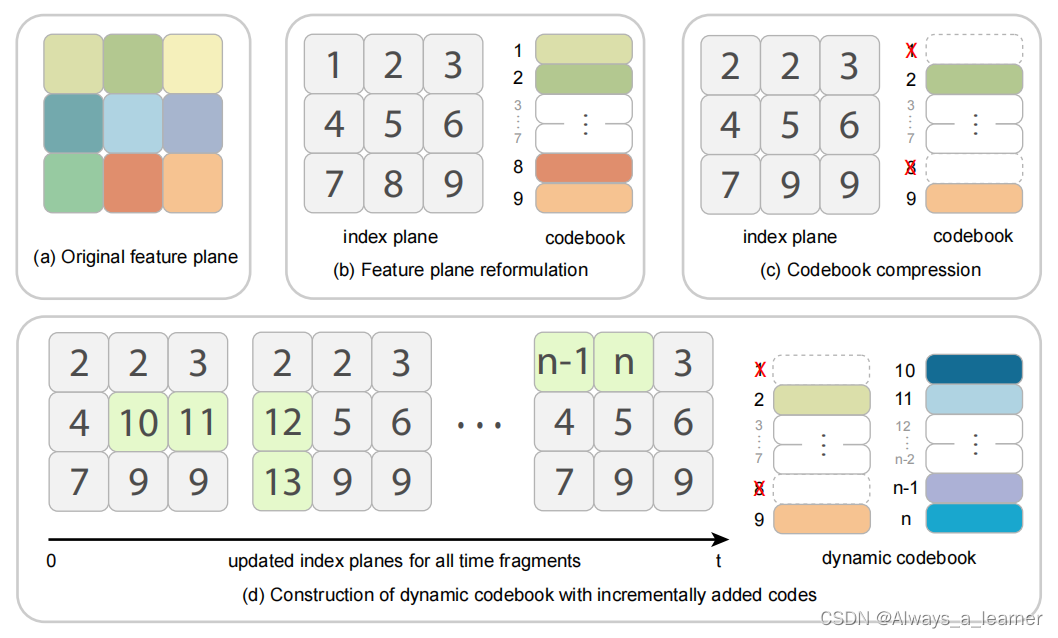
本文首先将模型转换为码本格式,如图中(b)所示,将特征平面上的所有特征压平成一个码本,将特征平面转换为索引平面。即,将索引映射存储到平面的每个网格点上的码本,而不是直接存储特征。
首先根据code在体渲染过程中对渲染权重的贡献,计算码本中每个code的重要性得分。具体来说,对于每条射线上的每个采样点pi,记录pi的体渲染权重Tiαi,同时在点pi处进行三线性插值时,记录相应的code及其权重。code的重要性得分计算如下:

其中,Nc表示映射到code c的射线上的点的集合,wci表示点pi三线性插值中code c贡献的权重。
为了减少存储空间,首先将重要性得分最低的部分code合并为一个单一的code;对于重要性得分中等的code,使用聚类方法将它们聚类为更少数量的code。如图中(c)所示。聚类按照VQ-VAE的优化方式执行;保留重要性得分最高的code
具体地,随机初始化n个codes,其中n个比要聚类的codes数量要小得多。然后,使用指数移动平均线(EMA)对代码进行迭代更新。在完成合并和集群操作后,相应地更新每个时间片段的索引平面上的索引。
Dynamic Codebook
上述基于codebook的压缩方法可以显著减少模型存储,但不可避免地会导致渲染质量的下降。这是因为聚类策略可能会降低其中一些code的准确性。尽管重要性得分可以衡量code在渲染过程中的贡献,但它并不能很好地描述对detailed区域和non-detailed区域的贡献。虽然这些detailed的区域通常只占据场景的一小部分,但他们的空间分布可能会随时间而变化,这使得很难通过直接优化一小部分codebook来提高渲染质量。
为了解决这个问题,首先将时间维度划分为多个片段。目标是自适应地识别和优化每个时间片段中最需要增强的部分,即共享空间特征平面在该时间段内提供相对较差的表示。由于这些部分所占比例较小,因此它们不会导致存储量的大量增加。
为此,利用反向传播梯度来精确定位在每个时间片段中要求最多优化的前k个code。具体来说,对于每个时间片段,在训练过程中运行正向和反向传播步骤,并多次迭代积累code的梯度。然后,选择累积梯度最高的k个code,并对这个时间片段进行优化。对每个时间片段重复这个过程,优化后的code独立于所有时间片段。
将每个时间片段的优化code附加到codebook中。此外,为这个时间片段存储一个独立的索引平面,并更新其中相应的索引,如图(d)所示。codebook的动态源于对每个时间片段进行优化而逐步构造。索引平面存储整数索引,从而占用最小的存储空间。
为了进一步压缩,使用均匀权值量化来量化codebook。然后,用entropy encoding编码所有的组件,包括量化的动态codebook、索引平面以及MLP参数。















 1713
1713

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









