






Attention Is All You Need 论文链接
这篇文章可以认为是近三年以内,深度学习里最重要的文章之一。它开创了继MLP,cl,和RNN之后的第四大类模型。
目录
摘要
现在的序列到序列的模型,基本上是使用了encoder-decoder架构,并加入注意力机制,而本篇文章提出了一个新的简单的模型架构,命名为Transformer。这个模型仅仅依赖于注意力机制,不像之前还使用RNN或者CNN.
模型
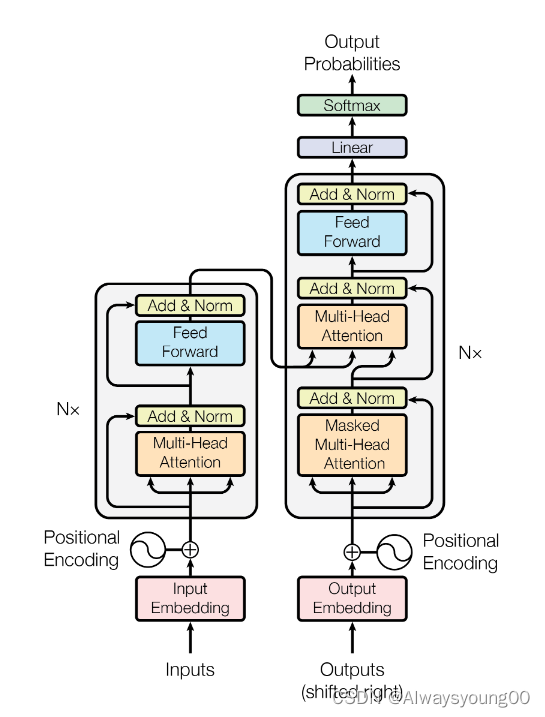
它的整个模型如下图所示。首先它是一个编码器解码器的架构。
左边是编码器,我们可以看到输入进来后,先经过一个嵌入层,再经过Positional Encoding(目的是为了加入时序信息,因为他没有RNN),之后进入了N个Transformer block。
在Transformer block里,进入Multi-Head Attention(多头注意力),Add&Norm(残差连接和normalization),然后进入一个前馈神经网络,再一个Add&Norm。
然后编码器的输出作为解码器的输入。
解码器和编码器差不多,仅多一个Mask(一种掩码机制,不让解码器知道某一个时序之后的信息)。
结论
这篇论文就如同它的题目一般,所作出的突破性贡献主要在于创新性的提出了多头注意力机制并据此提出了transformer架构。
在机器翻译的领域中,它的训练速度比传统的基于CNN,RNN模型快很多,并且效果更好。
作者认为这种纯基于注意力的模型除了在机器翻译领域中,还可以使用在图片,语音,视频上。
论文小结
- 提出方法:创新性的提出了多头注意力机制并据此提出了transformer架构。
- 解决的问题:使得序列到序列的模型更加简洁,因为仅使用了注意力机制,没有加入RNN,CNN等。
- 存在的问题:
- 计算量太大,self.attention的复杂度是n的2次方。
- 位置信息利用不明显,transformer的postionEmbedding效果不好,而且无法捕获长距离的信息。
- 启发:之后的Bert模型就是基于TransFormer,这种纯注意力机制的模型架构,我们也许可以用在不同的领域。















 830
830











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









