






Background & Motivation
文章首先对小样本目标检测存在的问题进行了分析,指出 TFA(Two-stage Fine-tune Approach)影响最后检测结果的有一部分原因是 IoU awareness 和 category discriminability。前者在文中的描述如下,是指将一些 IoU 得分低的检测框也分为 positive,可以理解为误定位。
Models that are weak in the first aspect often predict poorly localized hard negatives as “confident” foregrounds of the same category.
后者指的是误分类,很多论文以及我们自己的实验结果都证实了这一问题。往往模型定位的精度很高,但存在着大量的误分类,这是本文的一个 Motivation。文中列出了分别纠正这两个类别的错误后精度的提升情况:
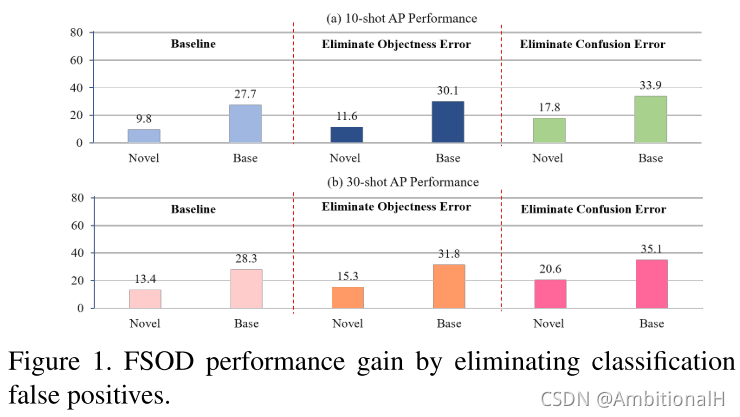
可以看出纠正误分类对模型的精度提升最大,以 dog 为例具体的做法:
The effect of the first type false positives (objectness error) can be eliminated by erasing the prediction score for its corresponding semantic category “dog”, while scores for other categories are preserved.
To eliminate the second type false positives (confusion error), scores for all other categories except “dog” are erased.
这样就证明了 TFA 可以很好的应对误定位问题,而应对不了误分类问题,也就是说 TFA 是 IoU-awareness 的。文章认为应对不了误分类的原因是 Faster Rcnn 的 cls head 和 reg head 是不适合小样本检测任务的,因为 cls head 希望学习到平移不变(translation-invariant)的特征而 reg head 希望学习到对平移敏感(translation-covariant,因为需要对其定位)的特征。这两个完全相反的学习目标一定是对模型精度存在影响,之前的文章《Revisiting RCNN: On awakening the classification power of Faster RCNN》是第一次提出这个观点。而如何应对这一问题,则是本文的另一个 Motivation。
Moreover,文章注意到了一个之前大家一直忽略的一个问题,distractor。也就是一些 Novel 类的实例出现在了 Base 类的数据中,但没有标注。这些实例被视为了背景,而在用 Novel 类数据微调的时候我们又告诉模型这是前景,这样就会影响模型的泛化能力。

文章基于 Faster Rcnn 提出了两个分支:IOU-aware classification branch 和 discriminability enhancement branch,来应对上述前两个问题。前者为每一个 proposal 产生精确的得分,就在 Faster Rcnn 上实现。后者则作为一个尺度不变的分类器,与 Faster Rcnn 完全解构不共享权重并为其提供额外的 cls refinement,文中称作 Few-Shot Correction Network(FSCN)。
找到 Base 中的这些 distractor 后设计了一个 Semi-Supervised Distractor Utilization Loss 来将这些 distractor 充分利用起来,用来缓解数据量不足的问题而无需再标注。同时为了应对 distractor,文章为 TFA 和 FSCN 都精心设计了 retreatment,称作 Confidence-Guided Dataset Pruning(CGDP)。通过自监督学习的方法在最大程度上排除那些 distractor,使数据集更适合小样本检测任务。
Approach
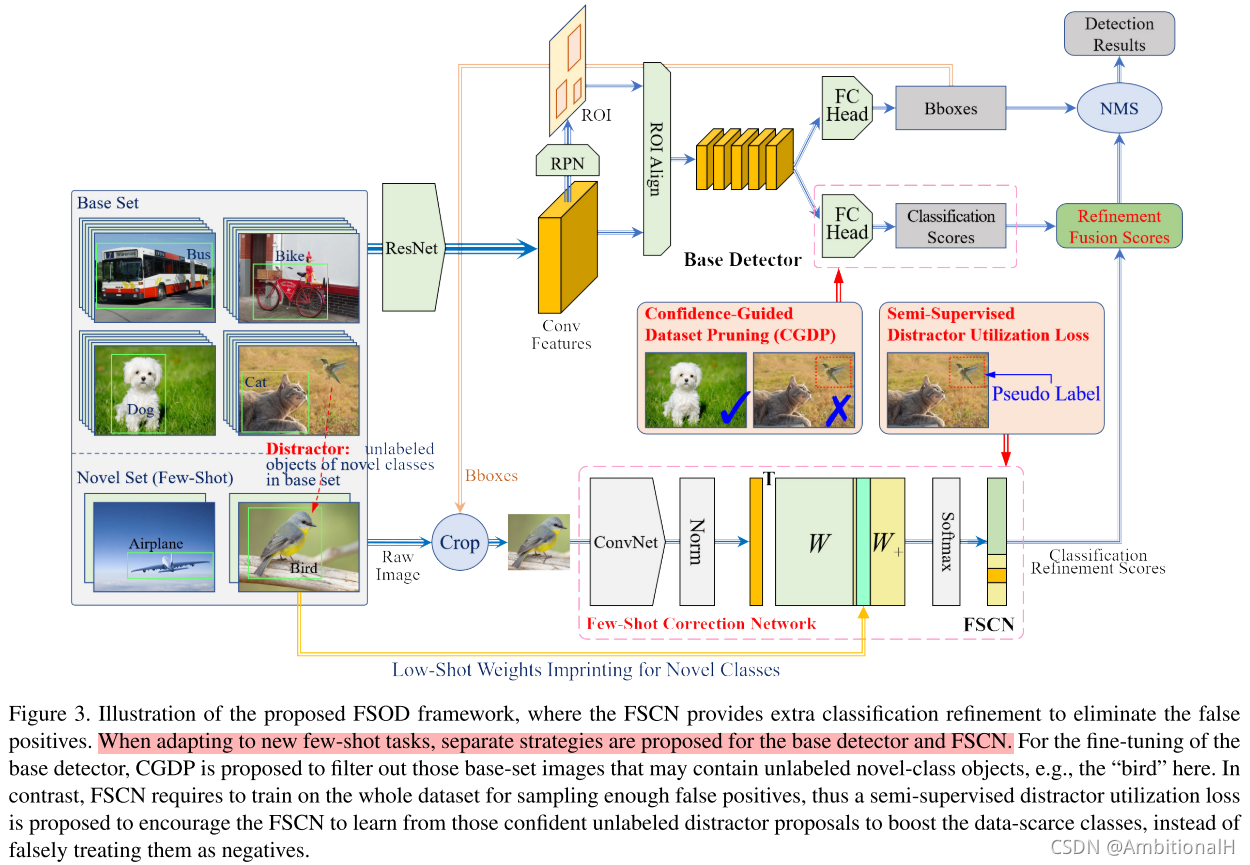
总的网络结构图如上,用与难例挖掘类似的方法将 false positive(这里的 fp 在两个训练阶段应该是不同的,pre-training 阶段指的就是那些 hard example,而在 FSOD 阶段则指的是 Novel 类的 example)从 Faster Rcnn 的 reg head 中抽样出来送入到 FSCN 中来实现对 cls 的 refinement。将 Faster Rcnn 称为 Fd,FSCN 称为 Fr,Fr 以 Fd 的 reg head 的输出作为输入:
![]()
输出 Nbs+1(pre-trainning 阶段)/Nt+1 维(FSOD 阶段)的分类置信度向量,其中 Nt=Nbs+Nnv(Nbs 是 Base 类类别数,Nnv 是 Novel 类类别数),p 是预测框,I 是输入图像,Cr 得到裁剪过后的图像。 因此总的结构可用公式表示为:
![]()
按原文的说法模型的训练分为两个阶段:pre-training 阶段和 FSOD 阶段。
During the initial pre-training phase, an object detector F(·|θb) is trained on Dbs for detecting objects in Cbs with parameters θb.
The FSOD task is performed on a k-shot novel set Dnv = {(Invi , ynv i )} with novel categories Cnv, where Cbs ∩ Cnv = ∅ and |Cnv| = Nnv. The objective of FSOD is to adapt the pre-trained detector parameters from θb to θ∗ through both sets Dbs∪Dnv, so that F(·|θ∗) can effectively detect the objects from all classes in Cbs ∪ Cnv.
这里 Cbs 是 Base 类的类别,Cnv 是 Novel 类的类别,在后面会用到的 Cb 是背景类。
Few-Shot Correction Network(FSCN)
- pre-training 阶段
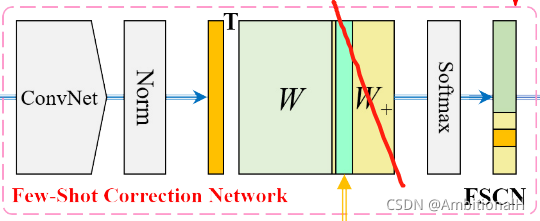
对于裁剪过后的图像,FSCN 提取其特征并将其经过一个线性的分类器:
![]()
其中 θ 是特征提取网络的参数,文章中的特征提取网络采用的方法是 Compact Generalized Non-Local(CGNL)。该模块实际就是一个全连接层,输出上图中的 W 和其前面带 T 的长方框(这时候没有用到 W+,这个参数在后面 Novel 上 fine-tune 时用到)。
该模块的示意图如下:
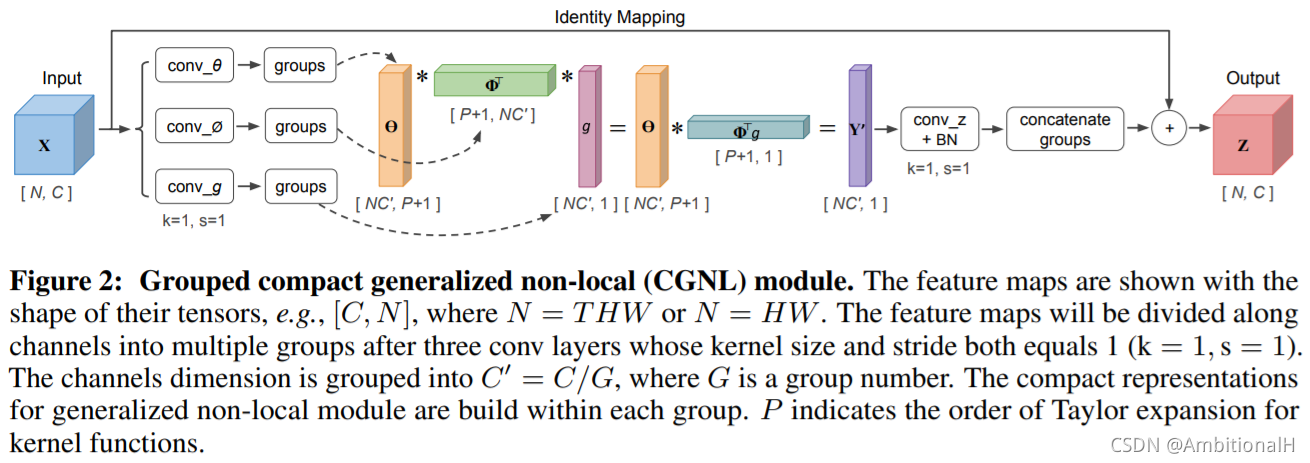
感觉像是一种注意力机制,文章中解释是为了获取全局感受野。我的理解是用 CGNL 的方法获取 FSCN 图中的 W,即 Zp。再将 Zp 输入到偏置为0的全连接层:
![]()
w 是 Nbs+1 维的线性变换参数。得到的 sr 是 Faster Rcnn 中 reg head 输出的 proposal 与所有类别的相似度得分,这里可以使用余弦相似度的形式来计算:
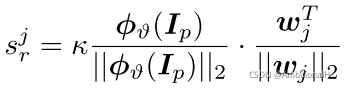
其中
![]()
wj 的维度和 Zp(特征的嵌入空间)的维度相同, · 代表 Frobenius inner product(即矩阵点乘后各项之和),分母是 L2 正则化,k 是可学习的尺度参数。之后经过 softmax 层得到 cls 的 refinement。再用 refinement 将 Faster Rcnn 的 cls head 的结果进行调整,这样就完成了 hard example 的“挖掘”。
- FSOD 阶段
这一阶段将 reg head 中输出的 Novel 类物体的 proposal 输入到 FSCN 中,这个阶段的图示如下所示:
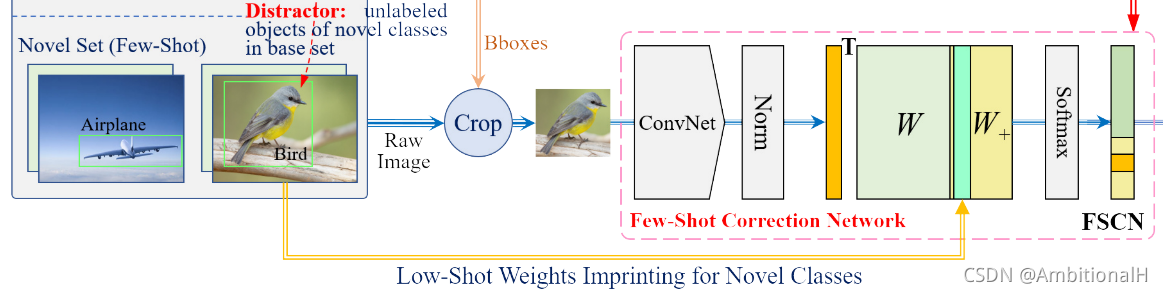
这一阶段同时需要将 φw 的线性变换参数 w 由 Nbs+1 维增加为 Nt+1 维(即上图中 FSCN 模块中扩展的 W+),这就涉及到一个初始化的问题。对于每一种 Novel 中的类别 j,文章中的做法为:

Lpj 是类别 j 的物体的 proposal,Nj 是类别 j 的proposal 的数量。实际上就是将属于类别 j 的物体特征进行正则化后相加,最后还需要一次正则化:
![]()
背景的线性变换参数是随机抽样背景区域通过上述计算得到的,文章中的做法称为 Weight Imprinting for Novel Classes。
Semi-Supervised Distractor Utilization Loss
Base 类中的 distractor 与 Novel 类的物体有许多特征上相似的地方,因此这些 distractor 也是十分有价值的。然而通常的交叉熵损失函数在小样本检测任务中,有用的(Novel 类)梯度很容易就被这些 distractor 的梯度所“淹没”。Distractor Utilization Loss 就是为了解决这一问题对交叉熵损失进行了改进,最初的想法起源于一个观察:Base 类中的背景 proposal 有可能就是那些没有标注的 Novel 类中的物体(如 COCO 数据集中的 person,这里的 person 作为 Novel 类,在 Base 类训练的时候往往被认作负例从而影响了梯度),而我们希望给背景 proposal 中的 distractor(即有可能是前景的 Novel 类中的物体)分配 positive 的梯度。
We notice that for each background proposal sampled from the base set, there is a probability for it to be an unlabeled foreground of novel class.
因此什么样的 proposal(Ibp)应该被分配 positive 的梯度?
- 这需要先用 FSCN 为背景 Ibp 生成一个伪标签:
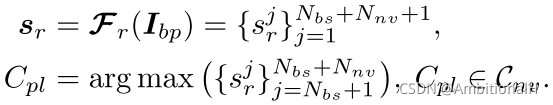
就是将相似度得分进行归一化,看这个 lbp 最可能属于哪个类别就将其伪标签设置为这个类。如果所有的 lbp 都被分配了 positive 的梯度而没有了 negative 梯度的话显然是不正确的。文章的做法是设置一个 Augmented background(加强背景)类 Cb+:
![]()
其中 Cb 是背景类,Cp 就是上面生成伪标签的类别。
以 COCO 一贯的划分:60类为 Base 类,20类为 Novel 类。以 lbp 中 Novel 类的 person 作为 distractor 为例,这时 person 作为 Cp 和背景类 Cb 组成加强背景类 Cb+。这样划分之后 Base 类有60类,Novel 类有 19 类因为分出了1类 “person” 到加强背景类。
- 但是往往只有一小部分的 Ibp 是真正的 Novel 类的物体,这时就需要将这一小部分挑出来。
In practice, when applying the above Ldul loss, if the merging strategy is applied to all backgrounds sampled from base set, each will contribute an encouraging gradient to novel class, and the accumulated gradient is too strong and lead to a biased prediction towards novel classes.
挑选的方法是 unlabelled object mining(UOM),不考虑物体的 occlusion 现象的话,这些 distractor 应该与已知物体(gt)的 IoU 尽可能的小。用 Msp 来度量这个 IoU 值:
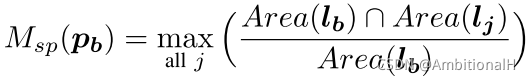
the proposed intersection ratio represents a normalized measure that focuses on the area of empty volume contained in each region proposal.
Distractor Utilization Loss 定义为
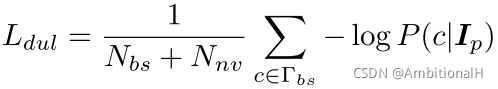
其中
![]()
![]()
The proposed distractor utilization loss Ldul assigns encouraging gradients to the potential corresponding novel classes to boost the few-shot performance when facing distractors. In the meanwhile, the original gradients to background class persist as well in regardless of distractor or not.
Ldul 只在 Base 类训练时使用,Novel 类训练时使用标准的交叉熵损失函数即可,Ldul 只施加在 Msp 值大的 lbp 上。
Confidence-Guided Dataset Pruning(CGDP)
这个模块可以看作是对 Base 类数据的“清洗”,使其包含尽可能少的 distractor。包含两个阶段:indicator learning stage 和 dataset pruning stage。
- indicator learning stage
这个 indicator 是为了评估 Base 类图像中包含 distractor 的可能性。对于在 Base 类上训练过的 Faster Rcnn(即 Fb),indicator 是指用 Dind 和余弦相似度损失对 Fb 进行微调后得到的 cls 分支。
Dind 包含整个 Novel 类的数据集 Dnv 和 Base 类数据集的一小部分(剩余的部分称为 Dpru,在第二阶段中用到),给定一张输入图像,其 proposal 的分类置信度为:
![]()
其中 Findc 即为上面说的 indicator,而包含 distractor 的可能性则由以下 query 函数计算得到:
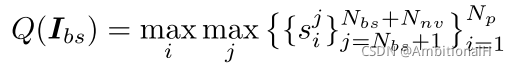
- dataset pruning stage
这个阶段用第一阶段的 query 函数来对 Dpru 进行“清洗”,得到包含尽可能少的 distractor 的子数据集 Dcln。为 Base 类中的每个类别构建 data pool:
![]()
每个 data pool 中抽出每个类别 query 函数得分最低(即包含 distractor 的可能性最低)的图像放入 Dcln 中。
CGDP 总的流程可以看作:
![]()
Training strategy
- Faster Rcnn
先用 Base 类数据训练10个 epoch 得到 Fd,之后使用 CGDP 的方法获得“清洗”过后的子数据集 Dft,这里的 Dft 包含 Base 中的类和 Novel 中的类。之后用 imprinting 策略对 cls head 中的参数进行扩展,扩展后用 Dft 对其进行微调得到最终的检测模型 Fd*,微调时冻结 Backbone 和 RPN。
- FSCN
得到 Fd 时用 Base 类数据对 FSCN 进行预训练,得到 Fr。用 imprinting 策略对 Fr 进行中的参数进行扩展,将扩展后的 Fr 用 Fd* 在 Dnv 和 Dbs 上进行微调,得到最终的 Fr*。Dbs 中的 distractor 先经过 UOM 过滤出是 Novel 类别可能性高的背景 proposal,对这些 proposal 使用 utilization loss,UOM 的阈值为 0.4。其余的 proposal 使用的都是传统的交叉熵损失函数。
Experiment
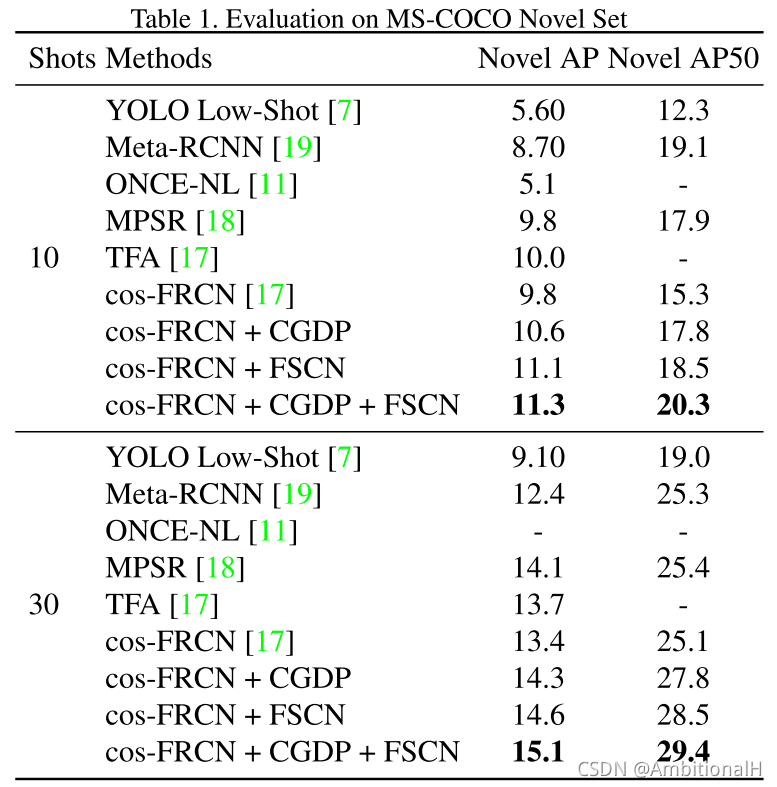
在 COCO 数据集上的结果:
在 Pascal VOC 上的结果:
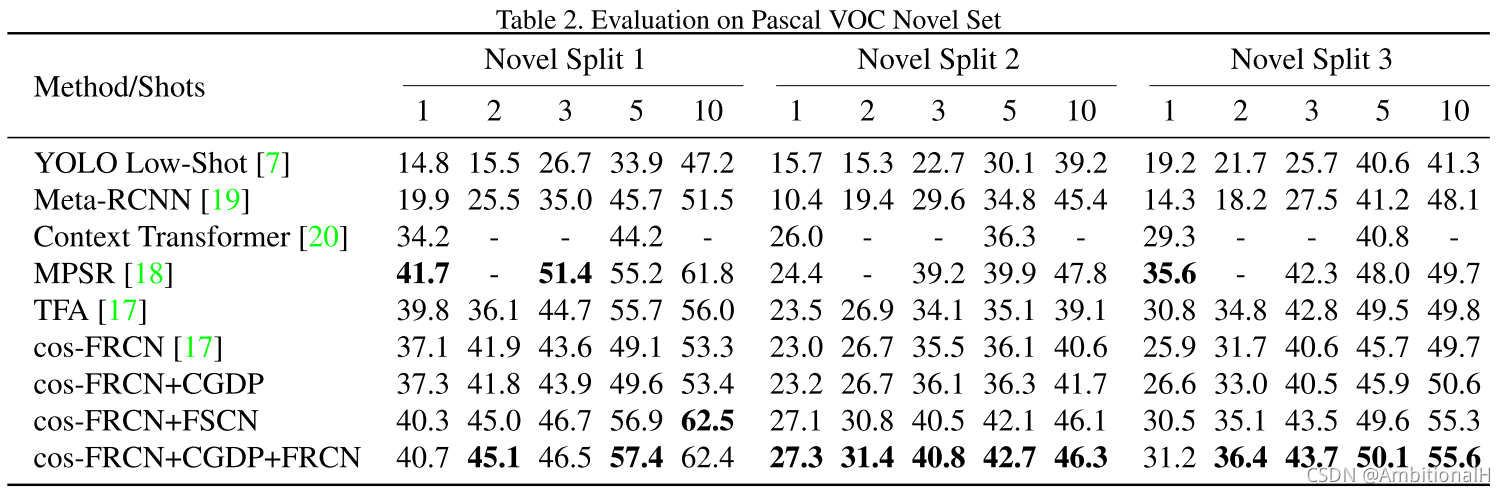
It also worth to note that there is no significant performance gain when introducing CGDP into the training of cos-FRCN, which is quite different from the results on MS-COCO.We conjecture this is because Pascal VOC contains much less unlabeled objects than MS-COCO, which makes the problem of distractors less obvious.
各模块的消融实验:
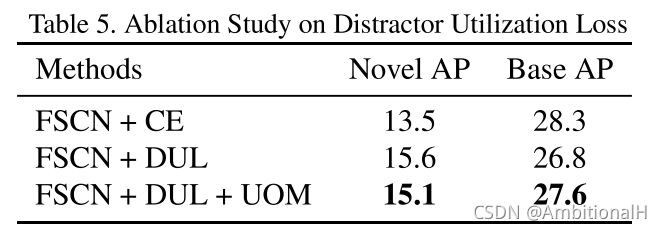
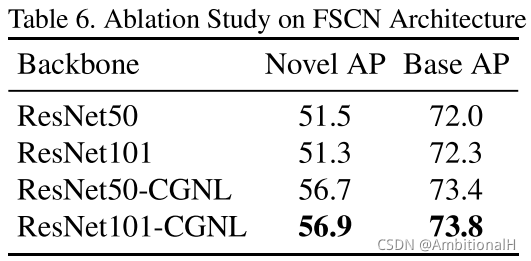
Conclusion
提出将 cls head 和 reg head 解耦的思想,是之前没有见过的思路,文章说的也很有道理,两个分支的学习目标是完全相反的。
FSCN 和 CGDP 两个模块的思想可以借鉴,既然模型的错误大多数是误分类,那就对 cls head 施加一个 refinement,这样的做法对传统目标检测也有用。
同时文中提到将微调 cls head 和特征学习解耦,使其在 Base 类上的精度提高,目前还没有从哪解的耦,但是 Base 类的数据确实有提高。Novel 类的精度提高不那么有说服力,Faster Rcnn 在 Base 类和 Novel 类上都进行了微调,精度提高也是理所当然。
附加
- Frobenius inner product


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









