






 本文提出了一种新的Few-shot目标检测方法,通过support-query相互引导机制和多级提案评分模块,解决了现有方法中support与query缺乏交互的问题,并引入混合损失函数解决假阳性及前景背景不平衡问题。
本文提出了一种新的Few-shot目标检测方法,通过support-query相互引导机制和多级提案评分模块,解决了现有方法中support与query缺乏交互的问题,并引入混合损失函数解决假阳性及前景背景不平衡问题。
Background & Motivation
文中将 Few-shot 学习分为两类:metric-based 和 optimization-based,后者是元学习的方法。将 Few-shot 目标检测分为:finetuning-based 和 finetuning-free。
然而以上这些方法都存在几个问题:
- support 中的信息没有指导 query 中 bounding box 的产生,support 和 query 之间缺少交互,没有充分利用 support 内的信息。
- k-shot 任务中各个 support image 的权重相同并且使用了最简单的平均来聚合这些 image 的特征,这是很不合理的。
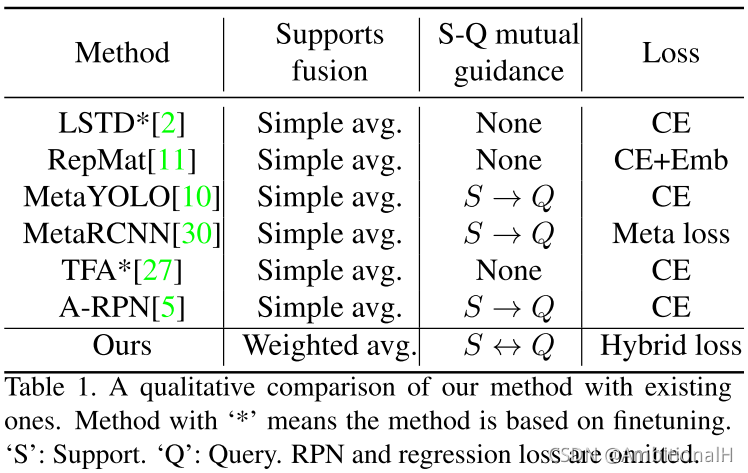
Method
为了解决上述问题,文章提出了 support-query mutual guidance 机制和 multi-level proposal scoring 模块。前者包括 support-guided proposal generation 模块和 query-guided support weighting 模块(后者在 1-shot 的情景下用不到,用在 few-shot 情景下),指导模型产生更加 support-relevant 的 proposal。后者结合 Hybrid loss 来计算 proposal 之间的距离度量并给出得分,对那些低质量的 proposal 进行过滤,输出的得分高的 proposal 即为最后检测结果。
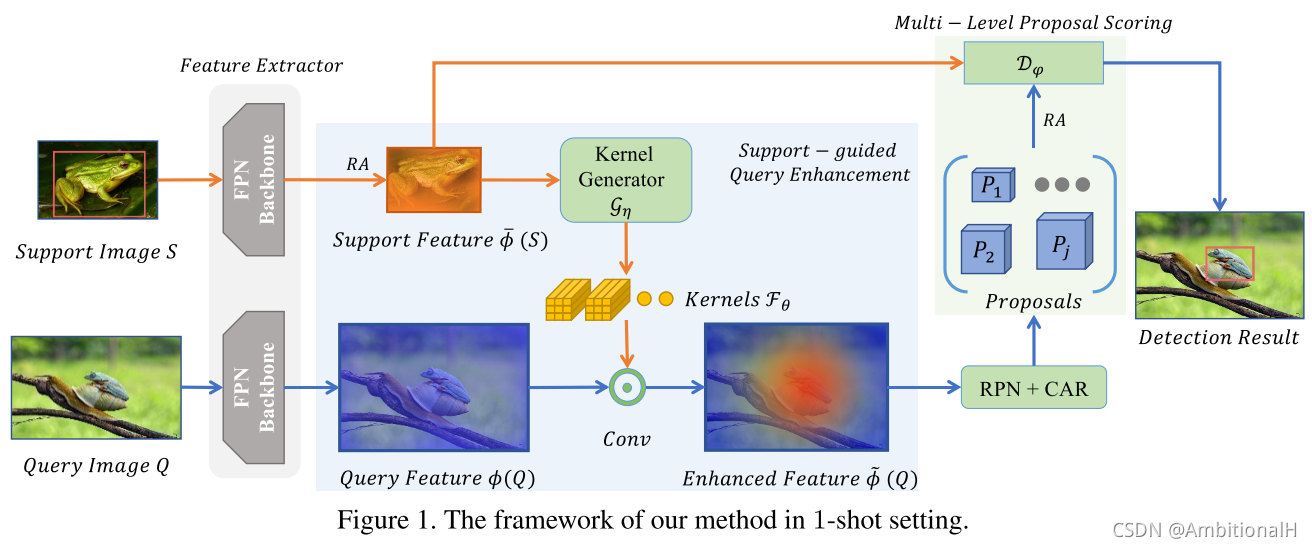
Support-guided Proposal Generation(SPG)
模型 1-shot 的结构如上所示(这时只有一个 support object),该模块利用 support object 的信息通过 dynamic convolution 的方法增强 query。利用 support object 的 FPN 各层输出的 RoI 特征图(这些 RoI 特征图通过 Annotation 和 RoIAlign 在 FPN 各层输出的特征图上计算得到,这个计算操作称为 RA 操作)来产生具体的 support-specific 卷积核,RoI 为 a*a*C1,公式如下:
![]()
其中 i 代表是 FPN 的第 i 层,输出为 b*b*C1*C2,b 为卷积核大小,C1 是 RoI 的通道数,C2 是卷积核个数,kernel size 为 a-b+1。用产生的卷积核对 query 的特征图进行卷积操作:
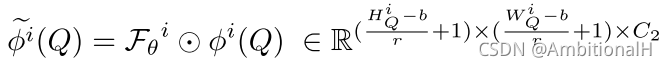
其中 r 为 stride,输出为增强后的 query 特征图,FPN 各层都需要进行上述操作。SPG 的结构如下图所示:
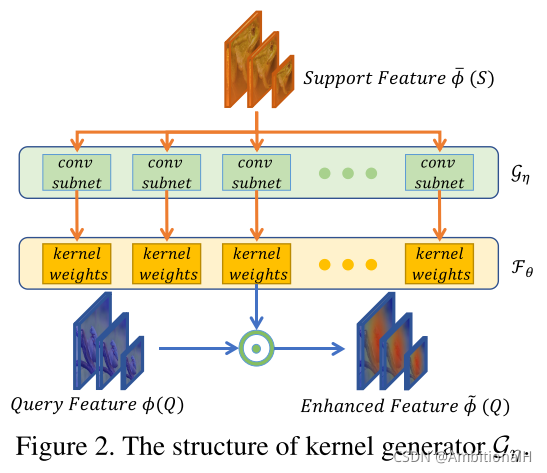
图中每一个 conv subnet 都代表一个卷积核,一共有 C2 个。
The parameters η of Gη are shared across all levels.
将增强后的 query 特征图输入到 RPN 中,RPN 输出的 proposal 输入到一个叫做 class-agnostic regressor(CAR)的模块中。这个模块用一个全连接网络实现,作用是对这些 proposal 的 bbox 再进行一次微调。
这里使用 support feature 提取卷积核再施加到 query feature 上,与 Transformer 中自注意力机制的作用相同,之前的文章里也看到过这种做法。
Query-guided Support Weighting(QSW)
对于 few-shot 的情况,即包含多个 support object 时模型结构里的 Support Feature 需要结合多个 object 的特征。QSW 用到了注意力机制,还是以 FPN 的第 i 层为例,用 RA 操作得到各个 support object 和 query 第 i 层的 RoI 特征图。之后经过相似度度量得到相似度得分:
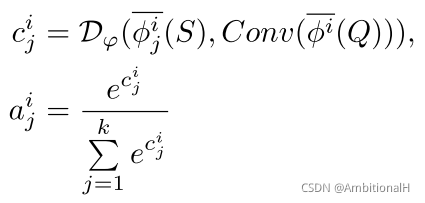
这里的度量函数与 MPS 中的度量函数共享权重,执行一次卷积操作是为了提取语义信息以及 compress the feature into a uniform space with the proposals。再将得分输入到 softmax 归一化得到各个 support object 的 RoI 特征图的权重,权重与 RoI 特征图结合并相加得到最后的 Support Feature。
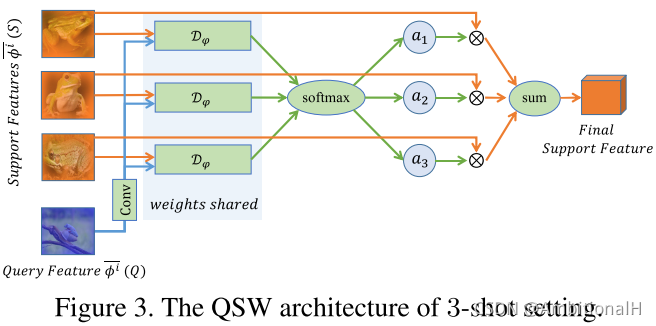
之后的操作与 SPG 相同,进行 dynamic convolution 等操作输出增强后的 query 特征图,再输入 RPN 和 CAR 产生要送入 MPS 的 proposal。
SPG 是 support-guided query enhancement 而 QSW 是 query-guided support weighting,这里实现了 Motivation 中提到的 support 和 query 之间的交互。
这里相当于是对多个 support feature,用度量函数来度量 support feature 与 query feature 的相似度,为相似度更大的 support feature 赋予更大的权重。将这些调整了权重的 support feature 相加,得到最终的 support feature。
Multi-level Proposal Scoring(MPS)
这个模块对 SPG 输出的 proposal 进行排名,排名的方法为:对第 j 个 proposal,用 RoIAlign 将其映射回 FPN 的各个层,得到在 FPN 各层的 RoI 特征图。将这些 proposal 反求出的 RoI 特征图与各个 support 对应的 FPN 层的 RoI 特征图进行相似度度量,公式如下:
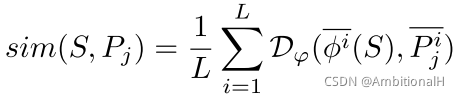
其中 L 是 FPN 的层数,这个度量函数采用神经网络实现,其结构如下(不带 top 的 Sigmoid 层):
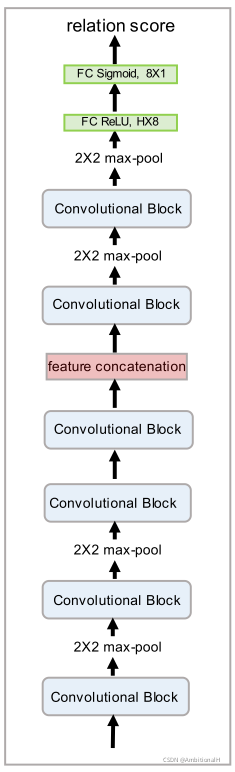
We output the final proposals according to a prespecified score threshold and non maximum suppression.
得分最高的 proposal 即为模型的检测输出。
Hybrid Loss
目标检测中常常遇见两个问题:False Positive 和前景背景比例的失调。
FP is because the learnt metric space tends to focus on separating foreground and background, ignoring different classes of foreground objects.
Most proposals Pj are from background, leading to an extreme imbalance between foreground and background classes during training the distance metric Dϕ(·, ·).
提出名为 hybrid loss 的损失函数,结合了 contrastive loss、adaptive margin loss 和 focal loss。记 Pc、Pnc 和 Pback 分别为 Positive 前景、Negative 前景和背景,S 为 support。
Contrastive Loss

用来应对 FP,其公式表达如下:
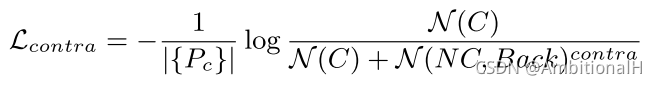
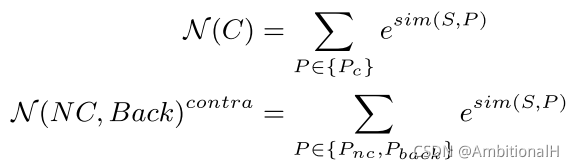
其中 sim 为相似性度量,基本形式为多分类的 Cross-Entropy 和 Softmax。
N(C) 的值越大或者 N(NC, Back) 越小,Lcontra 就越低,指导模型去学习 Pc 中与 support 更相似的特征。
Adaptive Margin Loss
contrastive loss 存在着不足:不同的类别在低维空间内 embedding 不会被很有效的分开。最直观的想法就是在类间增加 margin:
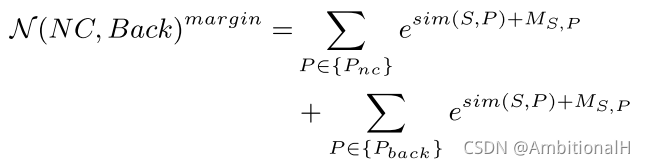
其中第一项里的 Ms,p 是 adaptive margin,根据相似性来计算:
![]()
vS and vP are semantic vectors of support and proposals classes extracted by a word embedding model.
In our experiments, we get semantic vectors from Glove and implement Dτ by cosine similarity.
μ 和 ν 是可学习的参数。
而第二项中的 Dτ 是一个超参数,μ 和 ν 也是可学习的参数。
Focal Loss
用来应对前景背景比例的失调的问题,一个简单的方法是采用随机采样 Pback 或者采用 OHEM。从 focal loss 得到启发,更加关注 hard negative:
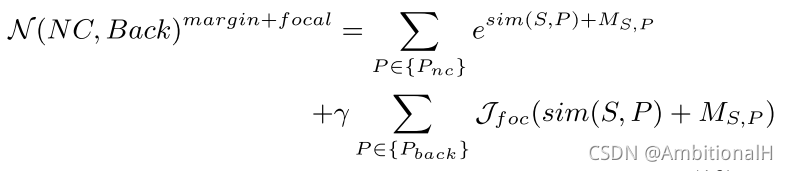
γ 是超参数,控制 negative sample 的数量。其中:
![]()
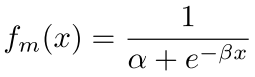
Jfoc(x) 用来使模型关注 hard negative,当 α、β 都为0时退化为指数函数:
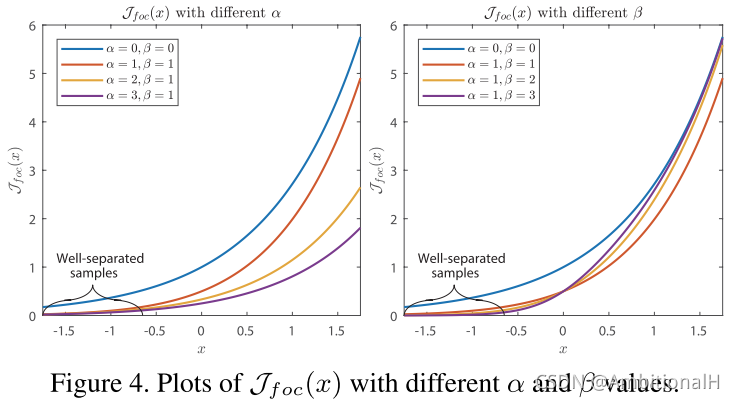
这时相似度低、已经被很好的分开的 sample 对 loss 的贡献更多,这就导致背景的损失主导了梯度下降。
In this case, even well-separable proposals contribute much to the loss, and the contribution from {Pback} can overwhelm that from {Pc} and {Pnc}.
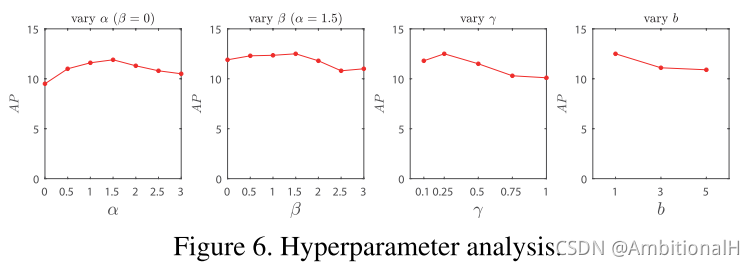
上图中可以看出,增大 α 或 β 都可以来应对这个问题。
We can see that a large α slows down the growth of Jfoc(x), so as to prevent the negative proposals from dominating the gradient. And a large β substantially restrains the values for well-separable proposals, allowing the model to pay more attention to proposals that are difficult to distinguish.
Total Loss Function
总的损失函数为:
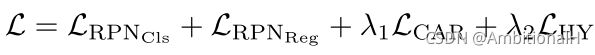
前两项为 RPN 的损失函数,LCAR 是 class-agnostic regressor,采用 smooth L1 损失。LHY 是结合了三种损失函数的 hybrid loss,从 Contrastive Loss 开始:

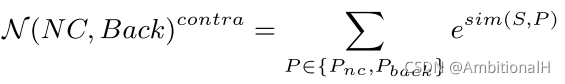
将 Adaptive Margin Loss 结合到 Lcontra 中:

将 Focal Loss 加入到其中来抑制背景,得到最终的损失函数 LHY:
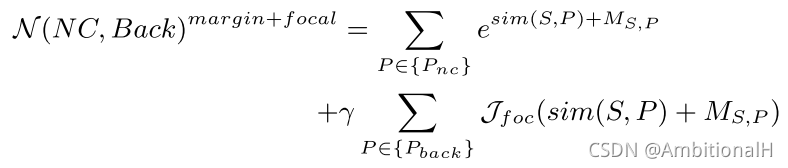
Experiment
COCO 数据集上结果:

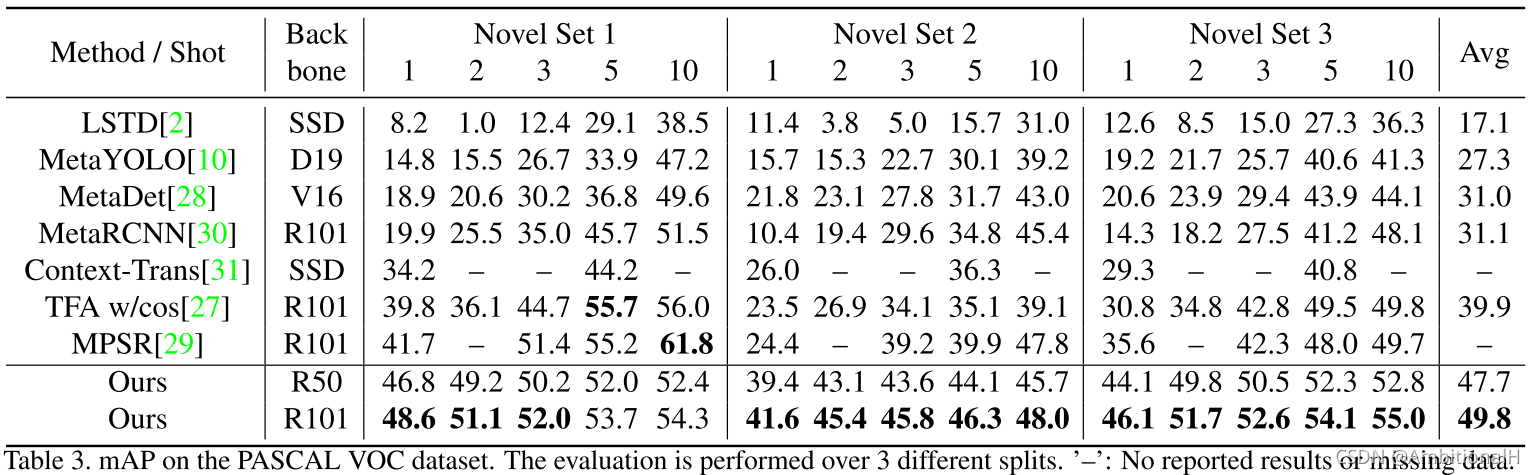
PASCAL VOC 数据集上:
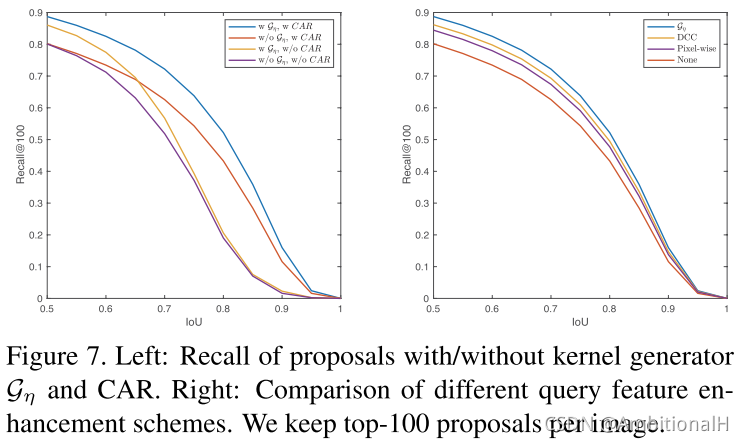
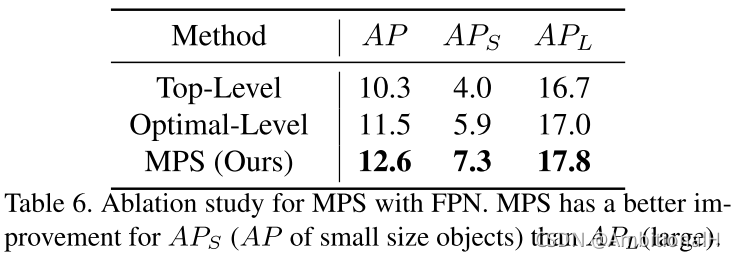
对各个模块/部分进行了消融实验:


对损失函数也进行了消融实验:

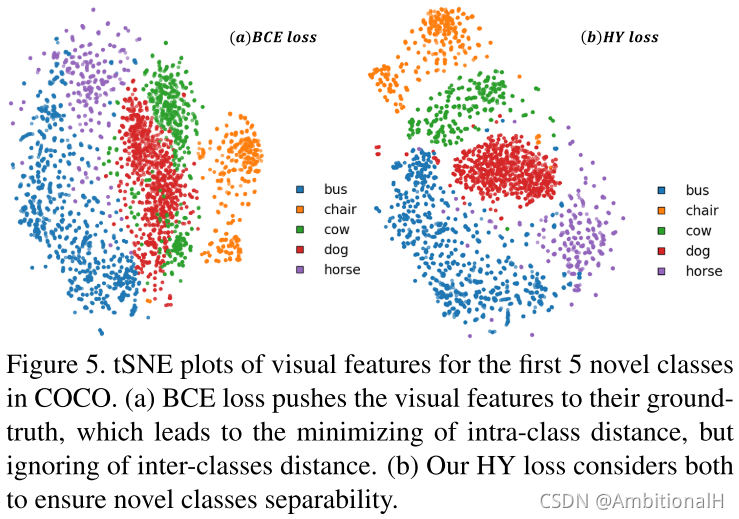
通过 tSNE 也证明了 HY loss 的效果:
Conclusion
实验中可以看出对该模型对小目标的提升很大,特别是 MPS 模块。
query 与 support 交互的思想似乎是第一次看到。
QSW 对 support object 很少的情况提升很大。
文章中对损失函数的分析值得再研究一下,FP 是目标检测中常见的问题,HY loss 可以用来缓解应对。

















 645
645

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









