






Background & Motivation
按文章中的说法,在此之前的 image-level 对比学习方法没有具体到下游任务上,比如:分类、检测和分割等,往往作为预训练模型提供给下游任务。
在“预训练-迁移”范式下,不论是有监督、无监督还是怎么样的学习方法,预训练后的模型作为迁移的起点,不只是基于特征重用这一出发点。当源域和目标域的特征差异较大时,预训练的模型更多是为目标域的任务提供一个合适的初始点(初始化),使训练更加平稳。
这种做法是次优的(sub-optimal),不如直接与下游任务对齐,用对比方法训练出一个用于检测的模型。
An obvious representation gap exists between image-level pretraining and the object-level bounding boxes of object detection.
与之前对比学习方法(MoCo)的区别是:
- 之前的做法是采用 image-level 的对比学习,而本文提出了一种 object-level 的对比学习方法;
- 之前的方法只能训练 backbone,而本文的方法可以同时训练 FPN、RPN 和 RoI Head 等模型中的其他模块,这样的话所有模块都可以被 well-initialized;
- 本文的方法可以学习到检测 object-level 所需要的平移不变性和尺度不变性,也即直接完成了“预训练-迁移”范式中的迁移,可以直接用在检测任务上;
- 同时受 SNIP 的启发,得到 proposal 后不在从统一大小的特征图上提取特征(如 Faster Rcnn 中的7*7),而是根据大小从 FPN 不同层的特征图上提取特征。
VADer [29], PixPro [10] and DenseCL [11] propose to learn pixel-level representations by matching point features of the same physical location under different views.
UP-DETR [31] proposes a pretext task named random query patch detection to pretrain DETR detector. Self-EMD [32] explores self-supervised representation learning for object detection without using Imagenet images.
Method
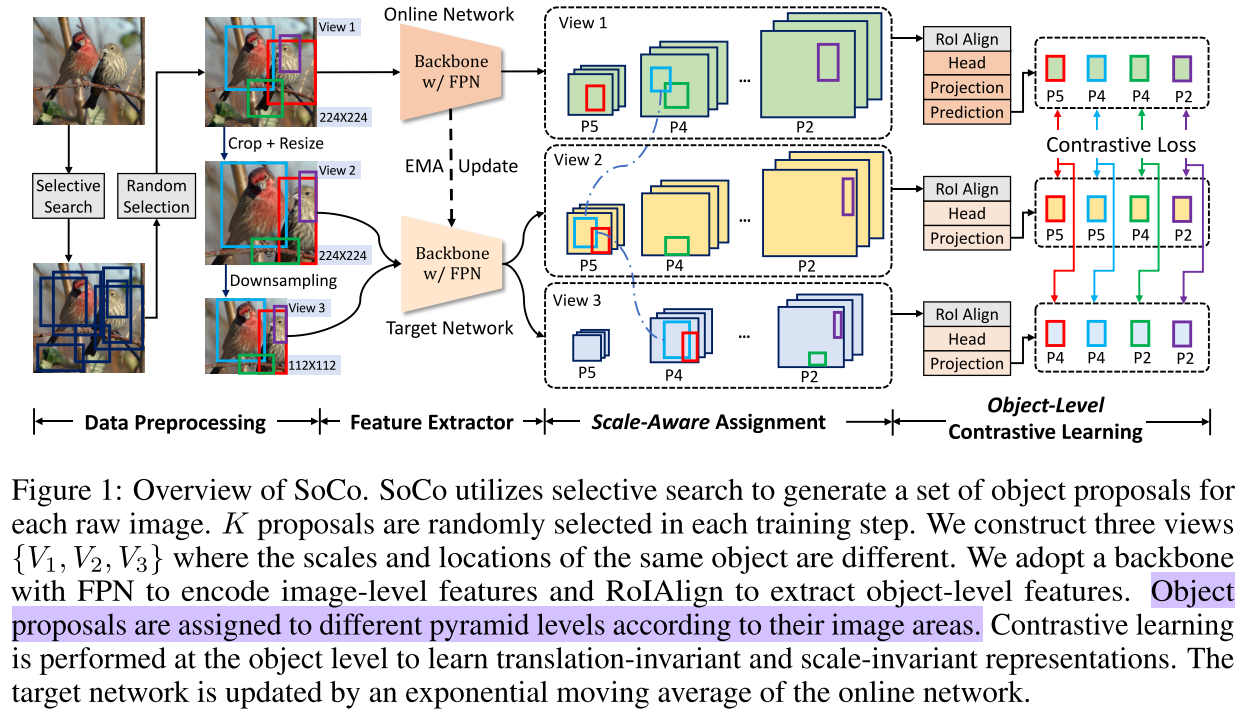
本文基于 Mask Rcnn,模型结构如下:
Training Schedule
将输入图像 reisze 成224*224后用 selective search 来产生 proposal,留下长宽比和大小不极端的 proposal 作为 V1。再使用随机裁剪作为 V2,裁剪后将 V2 resize 成与 V1 一样的大小。再将 V2 经过降采样为112*112得到V3。
之后将 V1、V2 和 V3 经过随机的数据扩增,作为同一张图像的三个 view。这些数据扩增包括 random horizontal flip、color distortion、Gaussian blur、grayscaling 和 solarization operation,从这些扩增方法中随机采样一种进行扩增。
SoCo 包含两个网络分支,分别为 online network 和 target network,结构相同但权重不同。target network 的权重是 online network 权重的指数移动加权平均(EMA),EMA 是一种给予近期数据更高权重的平均方法。
将 V1 输入到 online network,将 V2 和 V3 分别输入到 target network 中得到这个 proposal 在网络最后一层的 object-level 表征,即 Faster Rcnn 中要输入到分类器中的特征。下式中 fI 是 backbone,bi 是 RPN 中输出的 proposal,fH 是 RoI Head,输出的 hi 为 object-level 表征。
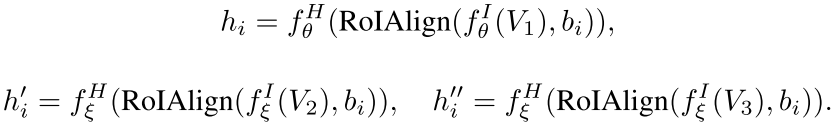
之后 online network 输出的表征经过一个两层的感知机得到 latent embedding,target network 输出的表征经过一个映射层得到 latent embedding。
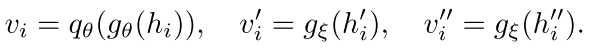
之后使用余弦相似度来计算这个 proposal 的对比损失:
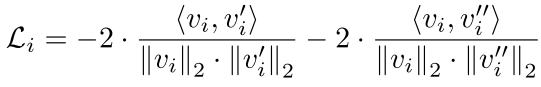
对所有的 proposal 求和得到 L:
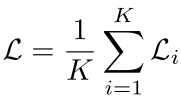
参数的更新与《Bootstrap your own latent: A new approach to self-supervised learning》相同:

再反过来,将 V1 输入到 target network,将 V2 和 V3 分别输入到 online network 按照上述流程得到 L_hat。最终的损失函数为:
![]()
Scale-Aware Assignment
Mask Rcnn 中包含 FPN 模块,FPN 将不同大小的 anchor 分配到不同的 FPN 层上。受 FPN 的启发,proposal 经过 RoI 映射回原图后不再从那一个统一的特征图上取到特征,而是根据 proposal 的大小从 FPN 对应层的特征图上取到特征。这样模型就学习到了同一物体在不同尺度下的特征,做法与 SNIP 一致。
As a result, SoCo learns object-level scale-invariant visual representations, which is important for object detection.
Introducing Properties of Detection to Pretraining
文章认为检测任务中模型最重要学习的两个特性是平移不变性和尺度不变性,同一类物体的表征应该尺度大小和位置无关。
V1 和 V2 的对比学习使模型学到了平移不变性,V1 和 V3 的对比学习使模型学到了尺度不变性。
Experiments
pretraining
batch size 为 2048。。。
Transfer Learning
batch size 为 16。
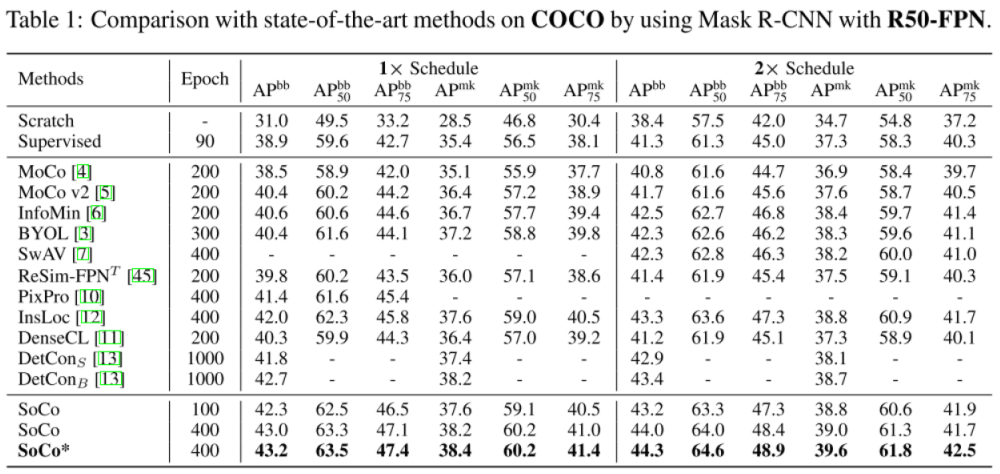
SoCo* 是指对 V1 的图像做了一个随机裁剪,之后 resize 成 192*192 作为 V4,训练流程与 V2 和 V3 相同。
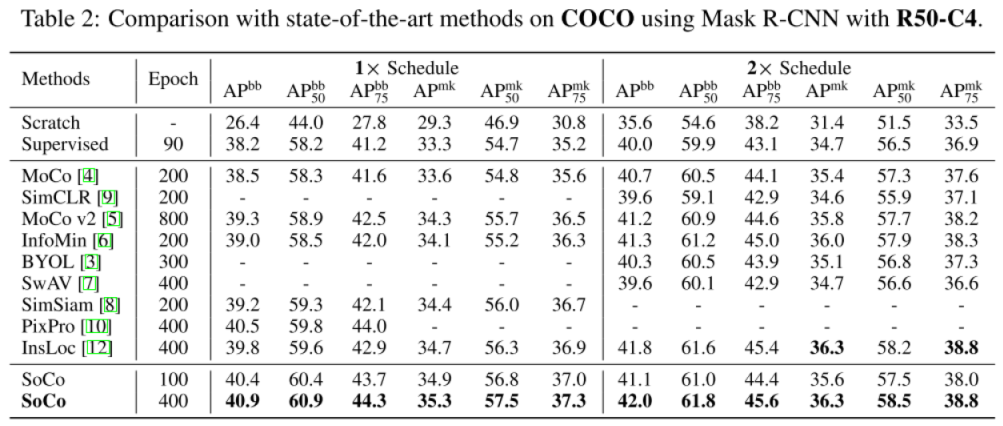
Ablation
各个模块的消融实验:

其中 Box Jitter 是指将 proposal 的坐标加上一定程度的抖动,proposal 的坐标为(x,y,w,h):
![]()
可以看到 x 和 y 的抖动与 w 和 h 有关,w 和 h 的抖动与 x 和 y 有关。提了0.1似乎作用不大,这一抖动不是标注不准了吗。
21.12.29
这里的 Box Jitter 似乎与上面链接中的边界框概率分布有关,即标注有可能存在一定的模糊性,传统监督学习的方法缺少了对这个模糊性的估计,“如果我们能够得到一个box的定位不确定程度,则我们可以加以利用以提升模型的精度”。
各个超参数的消融实验:

V3 的大小为112*122是为了降低计算消耗。不同框架上的效果:

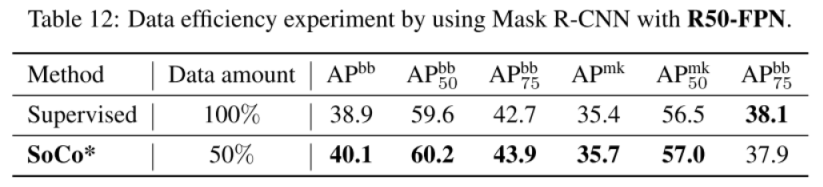
相对小样本的实验:
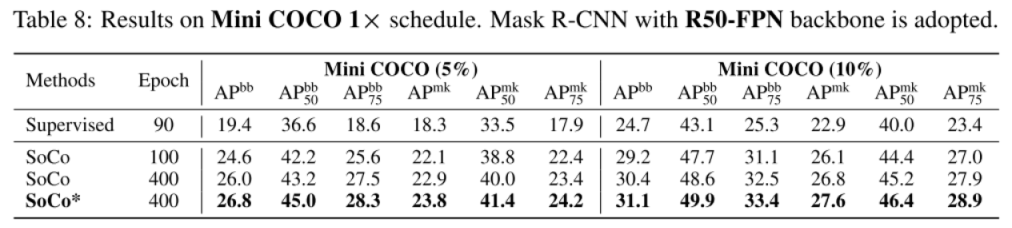
下表证明了 SoCo 更充分的使用了数据,同时也证明监督学习的方法特征提取不充分。
Conclusion
之前一直想把 MoCo 的方法加入到模型的训练中,但是由于其只训练了 backbone 所以不太适合作为微调的初始点,因为与模型太多的模块不同步。
这篇文章的方法则直接训练了一整个网络,但是由于自监督学习需要大量的计算资源,所以不太适合自己训练,但是可以直接使用其预训练好的模型,与监督学习预训练模型相比可能是个更好的起点。但是计算资源不足,无法在底片数据上进行预训练,不然效果一定更好。
这样一整个训练流程就打通了,使用大量无标签的底片数据使用 SoCo 的方法进行预训练(也可采用在 COCO 数据集上预训练好的模型),之后用监督训练的方法对模型进行微调。
22.02.08
这个训练流程似乎有问题,MoCo 论文里已经证明了无监督学习和有监督学习学到的特征是有很大差异的。
在 Linear Classification(固定特征提取网络,后接两层的分类器)这个任务设定上,无监督学习通过 grid search 搜索到的最优学习率为30,而有监督学习是绝对用不到这么大的学习率的。
但尽管如此,MoCo 论文里也证明了无监督学习和有监督学习在相同设定、训练充分的情况下,前者的精度更高。
附加
- EMA(exponential moving average)
【炼丹技巧】指数移动平均(EMA)的原理及PyTorch实现 - 知乎
- l1 与 l2 损失


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









