







PS:如果读过题了可以跳过题目描述直接到题解部分
提交链接:洛谷 P7802 [COCI2015-2016#6] SAN
题目
题目描述
Anica \text{Anica} Anica 有一张神秘的无限表,表里有无限行和无限列。有趣的是,表中的每个数字出现的次数是有限的。
定义函数 r e v ( i ) \mathrm{rev}(i) rev(i),返回 i i i 在十进制下翻转后得到的新数字。例如 r e v ( 213 ) = 312 \mathrm{rev}(213)=312 rev(213)=312, r e v ( 406800 ) = 008604 = 8604 \mathrm{rev}(406800)=008604=8604 rev(406800)=008604=8604。
表中第 i i i 行第 j j j 列的数字 A ( i , j ) A(i,j) A(i,j) 由以下方式得到:
-
A ( i , 1 ) = i A(i,1)=i A(i,1)=i
-
A ( i , j ) = A ( i , j − 1 ) + r e v ( A ( i , j − 1 ) ) A(i, j) = A(i, j − 1)+\mathrm{rev}(A(i,j-1)) A(i,j)=A(i,j−1)+rev(A(i,j−1)), j > 1 j>1 j>1
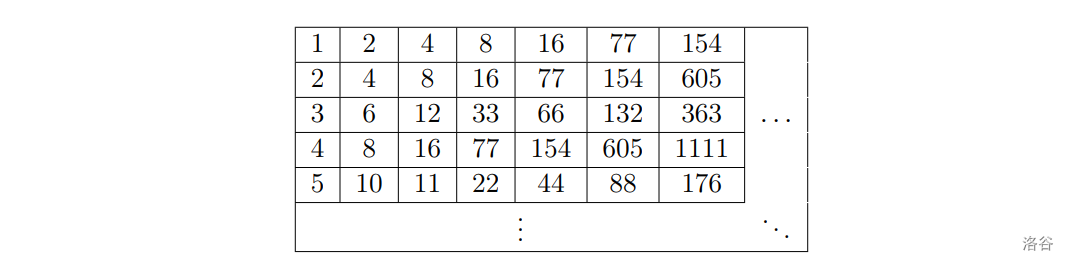
现在 Anica \text{Anica} Anica 给出 Q Q Q 个询问,每个询问给出两个整数 L L L 和 R R R,请你求出无限表中有多少个数的大小在 [ L , R ] [L,R] [L,R] 中。
输入格式
第一行包含一个整数 Q Q Q。
接下来 Q Q Q 行,每行包含两个整数 L L L 和 R R R。
输出格式
输出包含 Q Q Q 行,每行一个整数,其中第 i i i 行为第 i i i 个问题的答案。
样例 #1
样例输入 #1
2
1 10
5 8
样例输出 #1
18
8
样例 #2
样例输入 #2
3
17 144
121 121
89 98
样例输出 #2
265
25
10
样例 #3
样例输入 #3
1
1 1000000000
样例输出 #3
1863025563
提示
【数据范围】
对于 50 % 50\% 50% 的数据,保证 1 ≤ L , R ≤ 1 0 6 1\le L,R\le 10^6 1≤L,R≤106。
对于 100 % 100\% 100% 的数据,保证 1 ≤ Q ≤ 1 0 5 1\le Q\le 10^5 1≤Q≤105, 1 ≤ L , R ≤ 1 0 10 1\le L,R\le 10^{10} 1≤L,R≤1010。
【题目来源】
题目译自 COCI 2015-2016 CONTEST #6 T6 SAN。
本题分值按 COCI 原题设置,满分 160 160 160。
题解
80pts
想必骗分的套路大家都还是会的吧。
首先,看题的时候我们会发现,一个数出现的次数由两部分组成:
- 在第一列自己出现
- 在后面任意一列的出现都是由前一个数决定的
比如:
所以可以暴力处理每一个数的出现次数: + + a [ i ] ; ++a[i]; ++a[i]; a [ i + r e s ( i ) ] + = a [ i ] ; a[i+res(i)]+=a[i]; a[i+res(i)]+=a[i];然后建线段树,直接查询就好。
160pts
数位DP
我们可以发现后面每个数其实都是关于中间对称的(如果我们把十进制的每一位都看做从0到18的数的话)
预处理每个数前面出现的次数(注意要进行离散化)
然后直接搜索求差就可以了
代码实现
80pts
//洛谷 P7802 [COCI2015-2016#6] SAN
#pragma GCC optimize(3)
#include<iostream>
#include<cstdio>
#define int long long
using namespace std;
int q;
int l,r;
int ans;
int a[20000010];
int rt[80000010];//只需要保存节点上的值就好了
void in(int &x){
int nt;
x=0;
while(!isdigit(nt=getchar()));
x=nt^'0';
while(isdigit(nt=getchar())){
x=(x<<3)+(x<<1)+(nt^'0');
}
}
void build(int x,int l,int r){
if(l==r){
rt[x]=a[r];
return;
}
int mid=(l+r)>>1;
build(x<<1,l,mid);
build(x<<1|1,mid+1,r);
rt[x]=rt[x<<1]+rt[x<<1|1];
return;
}
inline int query(int x,int ll,int rr,int l,int r){
if(l==ll&&r==rr)
return rt[x];
int mid=(ll+rr)>>1;
if(r<=mid)
return query(x<<1,ll,mid,l,r);
if(l>mid)
return query(x<<1|1,mid+1,rr,l,r);
if(l<=mid&&r>mid)
return query(x<<1,ll,mid,l,mid)+query(x<<1|1,mid+1,rr,mid+1,r);
}
int rev(int x){
int a=0;
while(x){
a=a*10+x%10;
x/=10;
if(x==0){
break;
}
}
return a;
}
signed main(){
register int i,j;
in(q);
for(i=1;i<=10000000;++i){//暴力遍历更新
++a[i];
a[i+rev(i)]+=a[i];
}
build(1,1,10000000);//建树
while(q--){
in(l),in(r);
if(r<=10000000){
printf("%lld\n",query(1,1,10000000,l,r));//查询
}
else{
printf("1863025563\n");//试图骗分 但是失败
}
}
return 0;
}
160pts
//洛谷 P7802 [COCI2015-2016#6] SAN
#pragma GCC optimize(3)
#include<iostream>
#include<cstdio>
#include<algorithm>
#define int long long//注意这样定义的时候主函数要用signed
//所以更建议用define LL long long
using namespace std;
const int m=1e10;
int q;
int l,r;
int tot,//去重后的元素总数
a[4000010],//离散化
f[4000010],//离散化后的数在第二列出现的次数(前缀和)
c[4000010],//离散化前的数在第二列出现的次数
b[4000010];//离散化前的数
int p[15];//10^n
int hh[2][20]={{1,2,3,4,5,6,7,8,9,10,9,8,7,6,5,4,3,2,1},
//非首位可以被凑成的次数
{0,1,2,3,4,5,6,7,8,9,9,8,7,6,5,4,3,2,1}};
//首位可以被凑成的次数 注意首位不能为0
void in(int &x){
int nt;
x=0;
while(!isdigit(nt=getchar()));
x=nt^'0';
while(isdigit(nt=getchar())){
x=(x<<3)+(x<<1)+(nt^'0');
}
}
int find(int x){//二分查找
int l=0,r=tot,mid;
while(l<r){
mid=(l+r+1)>>1;
if(a[mid]<=x){
l=mid;
}
else{
r=mid-1;
}
}
return l;//返回离散化后的编号
}
int calc(int x){//求和
if(x==0){
return 0;
}
return f[find(x)]+x;//离散化后的次数(前缀和)+第一列出现的次数(x)
}
int rev(int x){//求翻转后的数
int a=0;
while(x){
a=a*10+x%10;
x/=10;
if(x==0){
break;
}
}
return a;
}
void dfs(int ed,int dep,int s,int t){
//ed 数的长度 dep 当前搜索到的数的长度 s 现在累计到的数 t 出现的次数
if(s>m){
return;
}
if(dep==(ed+1>>1)){
c[++tot]=t;
b[tot]=a[tot]=s;
return;
}
if((dep<<1|1)==ed){
for(int i=(dep==0);i<=18;++i){
if(!(i&1)){
dfs(ed,dep+1,s+p[dep]*i,t);
}
}
}
else{
for(int i=(dep==0);i<=18;++i){
dfs(ed,dep+1,s+(p[dep]+p[ed-dep-1])*i,t*hh[dep==0][i]);
}
}
}
void pre(){
register int i,j;
p[0]=1;
for(i=1;i<=10;++i){
p[i]=p[i-1]*10ll;
}
for(i=1;i<=10;++i){
dfs(i,0,0,1);
}
sort(a+1,a+1+tot);//去重之前一定要排序!!!
j=tot;
tot=unique(a+1,a+1+tot)-a-1;//去重 头文件为algorithm 返回去重后末尾元素的下一个位置(用于离散化)
for(i=1;i<=j;++i){
f[find(b[i])]+=c[i];//合并在第二列的总次数
}
for(i=1;i<=tot;++i){
int tmp=a[i]+rev(a[i]);
if(tmp>m||tmp<0){
continue;
}
f[find(tmp)]+=f[i];
}
for(i=1;i<=tot;++i){
f[i]+=f[i-1];//前缀和
}
}
signed main(){
register int i,j;
pre();
in(q);
while(q--){
in(l),in(r);
printf("%lld\n",calc(r)-calc(l-1));
}
return 0;
}
















 281
281











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











