







文章目录
1. Sophisticated Input
如果神经网络输出是一个序列并且长度不一致时,比如输入是一个句子,把句子里面的没一个词汇都表示成一个向量(vector),呢么model的输入就是一个vector set,并且每次的输入长度都不一样。
1.1 Input
当输入是一段话时,
- 我们可以用独热码来表示每一个向量,但是由于互相正交,所以彼此之间没有办法存在语义的联系
- 另一种方法对每个词汇都给一个向量(词向量),并且互相之间有着一定的联系。

声音信号也可以作为一个vector set,我们把一小段的声音信号变成一个向量(frame),这样一段声音就成为很多连续向量的连续。

一个图结构也可以抽象化成一个向量集合,每一个节点都可以看作一个向量

每一个分子也可以看作一个graph,上面的每一个原子都可以用一个向量来表示,比如用不同的元素进行标识

1.2 Output
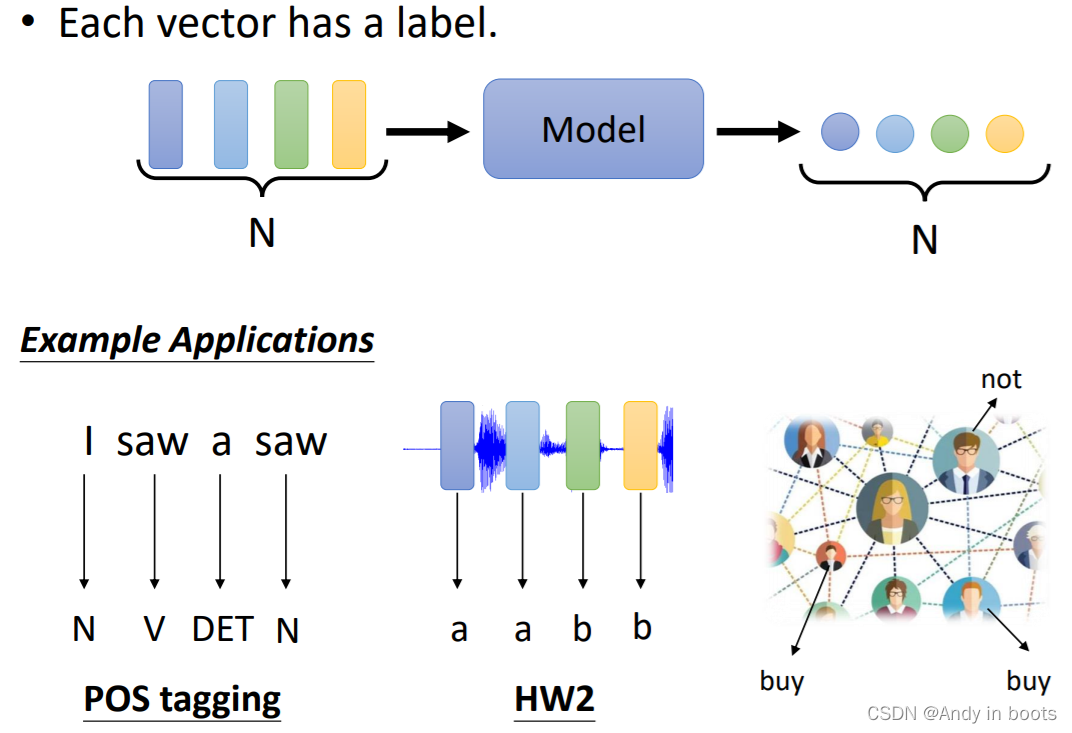
当每个输入向量都有对应的输入时:
- 如果输出是一个数值那么就是回归问题(输入输出的长度一样)
- 输出是一个class就是分类问题
例如:
POS tagging(词性标注),让机器确定每一个词汇是什么词性(名词、动词等等),输入输出长度一样
作业2的语音信号识别每一个音标是什么
社交网络里每一个节点会不会买商品,从而确定用不用推荐相关商品。
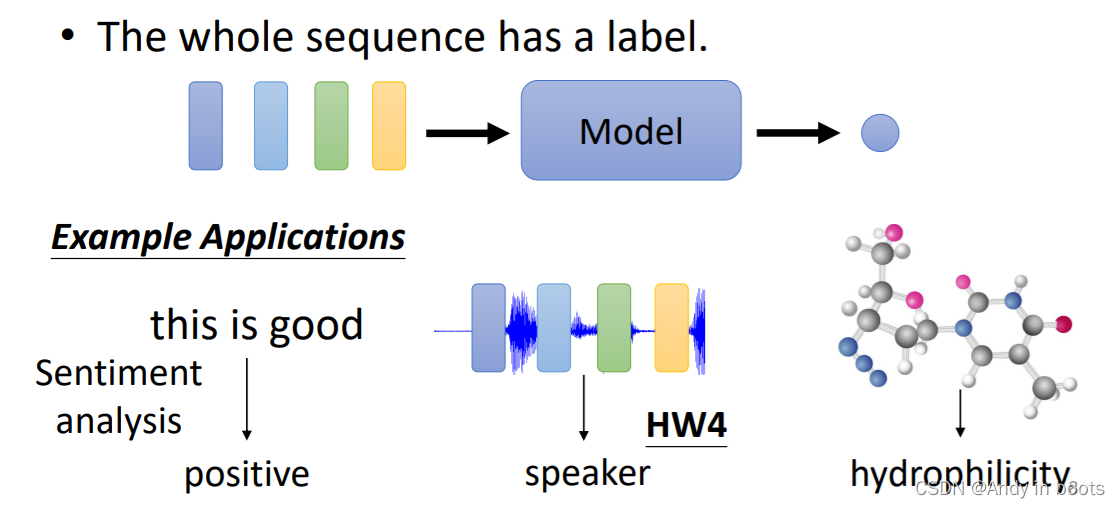
第二种情况是,我们的输入只需要输出一个label就可以
例如Sentiment analysis,判断一段话是正面还是负面评价
语者辨认,确定是谁讲的话
预测分子的毒性或者亲水性
还有一种情况下我们并不知道输出的长度是多少,由机器自己学习产生,这种就是seq2seq的任务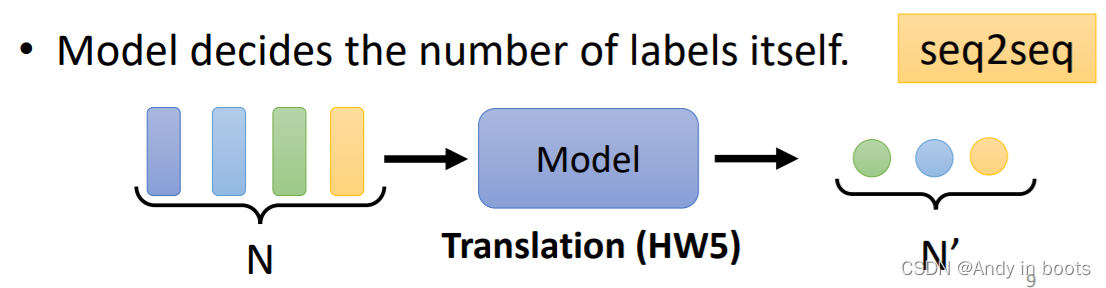
在这里我们只讨论输入和输出一样长度的情况,即Sequence Labeling
2. Self-attention
如果使用之前的Fully-connected,无法考虑到上下文关系,每一个输入都是独立的。就算我们把每一个window输入给网络,这样的方法还是有极限的,无法考虑到整个sequence(因为运算量会很大、还会过拟合)

所以我们使用了注意力机制,考虑整个序列得到一个向量

Self-attention的输入可以多次叠加,与全连接交替使用。使用Self-attention比较有名的就是Attention is all you need 中的transformer(变形金刚:)的架构。
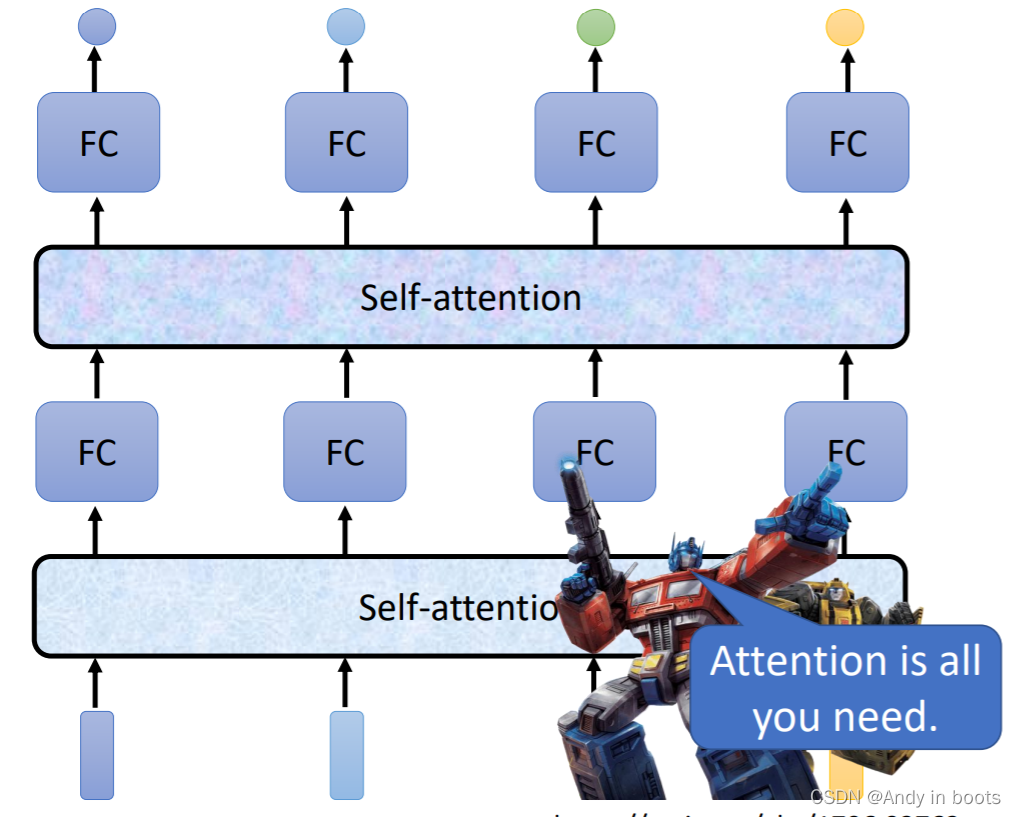
2.1 Process
接下来是Self-attention的步骤:
- 首先找出sequence中与
a
1
a^1
a1相关的向量,并得到相关性大小的权重(attention score)

- 常用的寻找这个相关性数值(attention score)的方法是做Dot-product操作(如下图左)和Additive(如下图右)
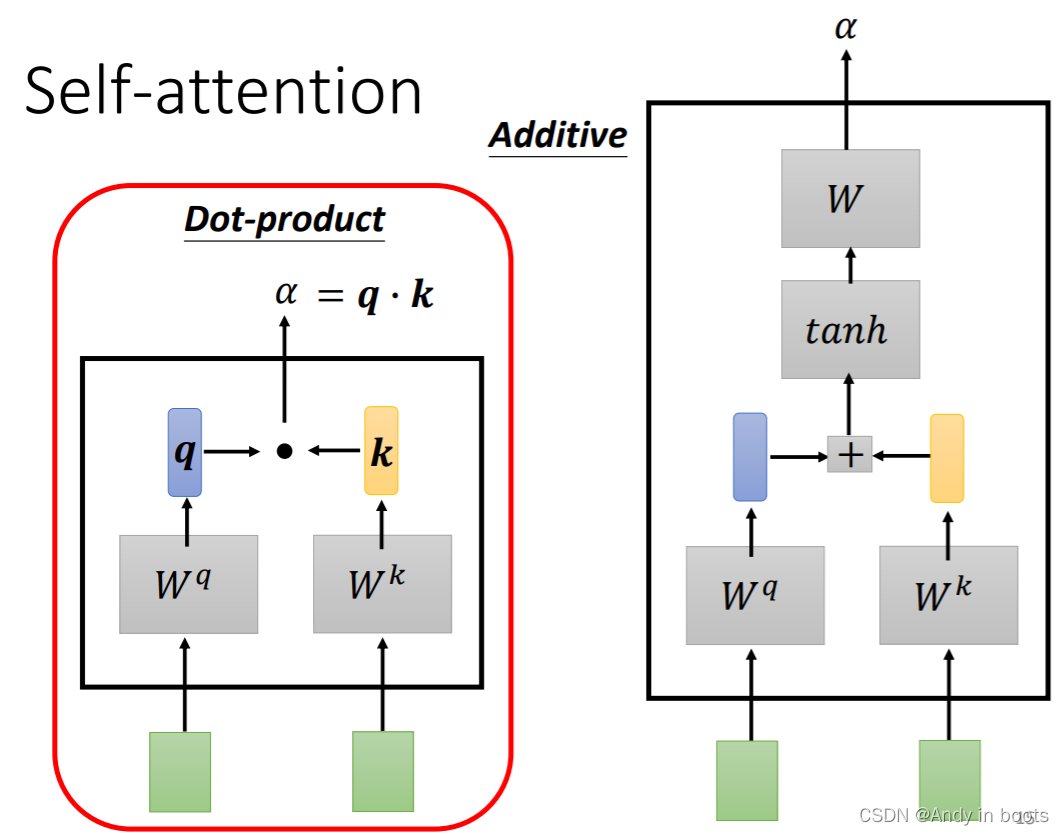
- 这时我们就让
a
1
a^1
a1分别对每一个输入进行计算attention score,其中
q
n
q^n
qn在论文中的关键字是query,
k
n
k^n
kn的关键字是key。其中
a
1
a^1
a1也会跟自己计算attention score。之后我们会做一个Soft-max(其他的Activation Function也可以)。
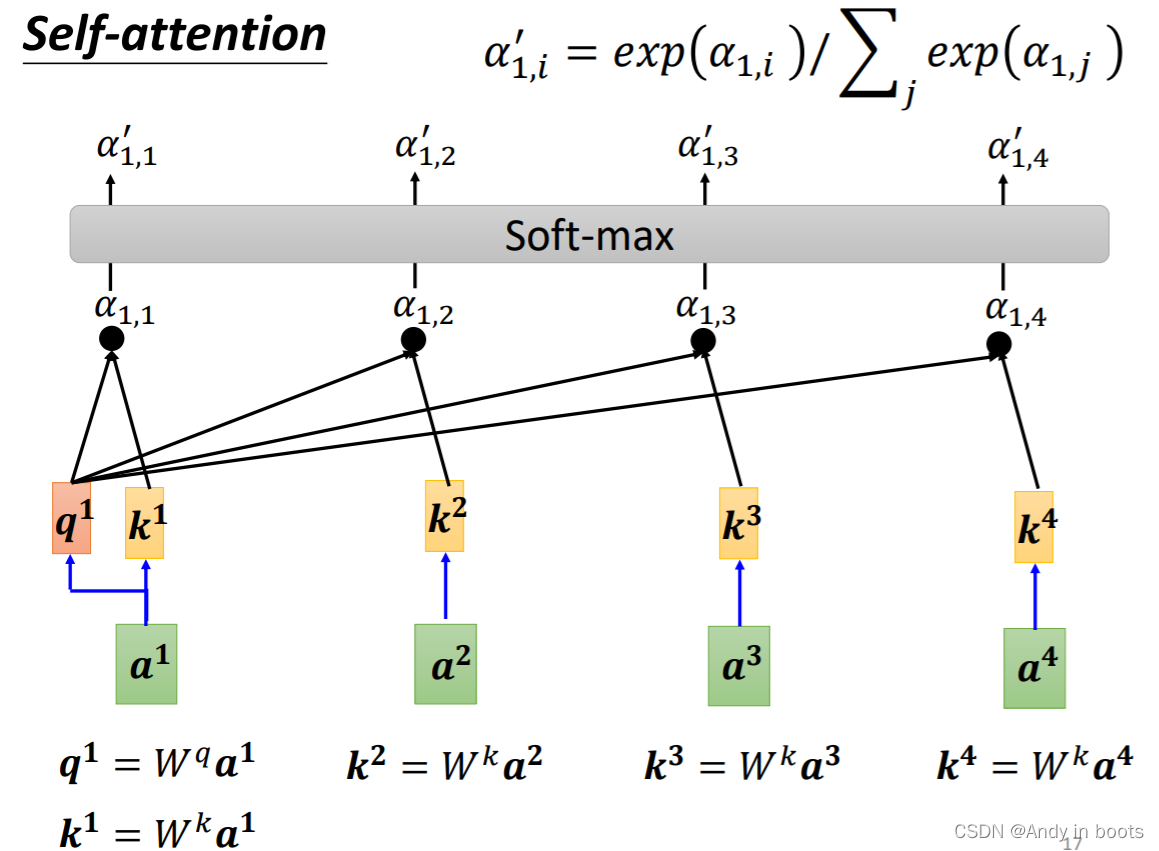
- 这里我们已经知道了每个向量和
a
1
a^1
a1的关联性,所以我们把每一个向量计算得到
v
n
v^n
vn并与attention score相乘后相加得到
b
1
b^1
b1
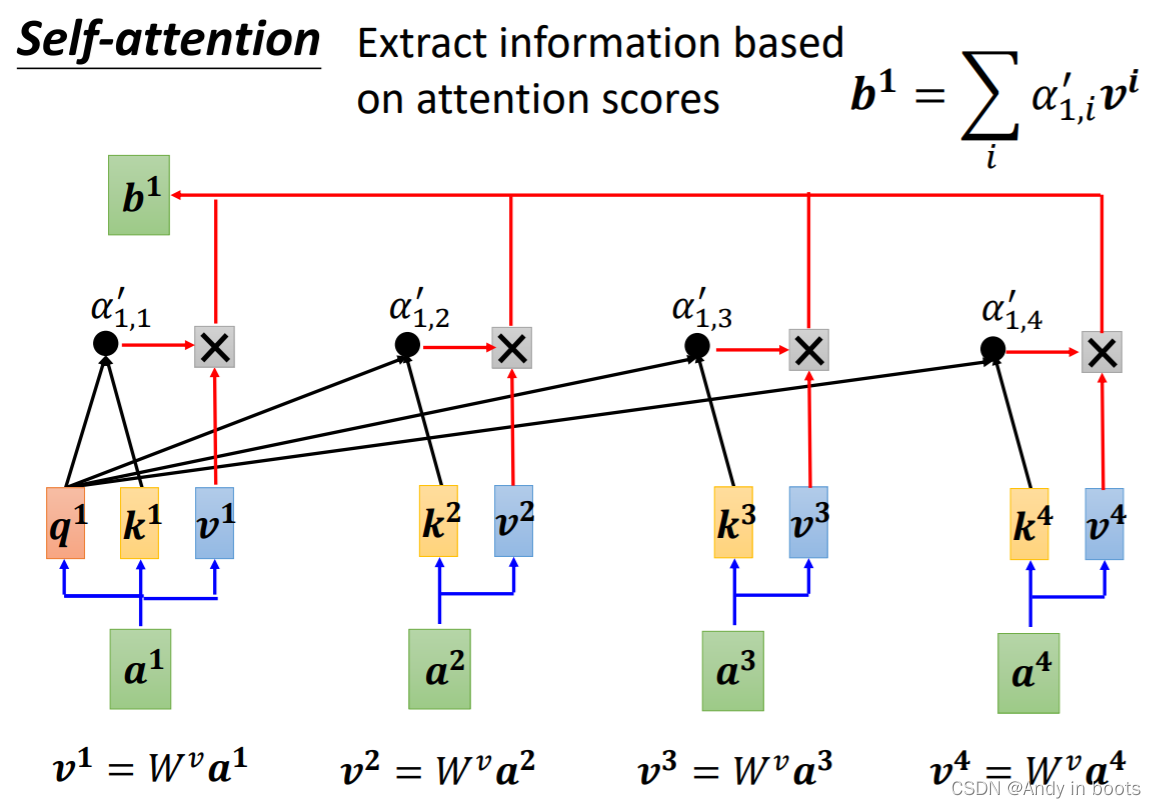
- 同理操作每一个输入,这样我们就得到了一排attention层的输出,这里每一个
b
n
b^n
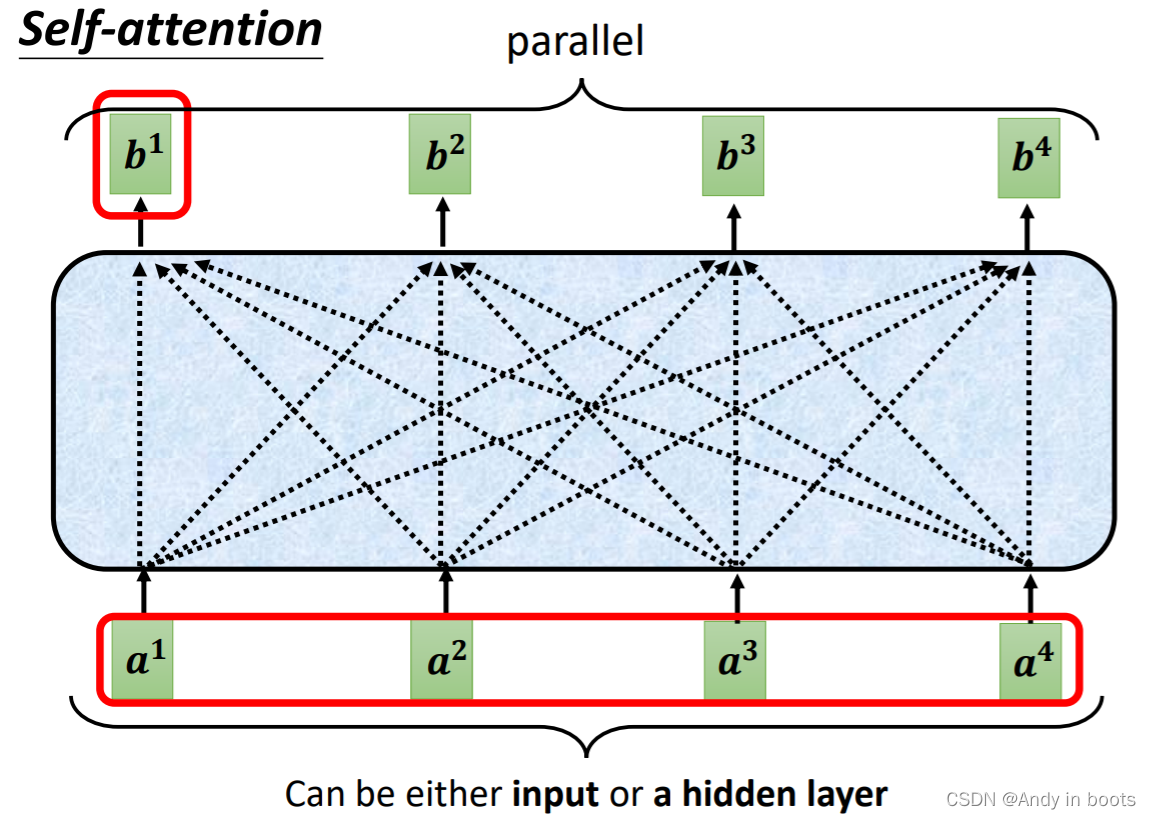
bn并不需要依次产生,它们是同时被计算出来的。
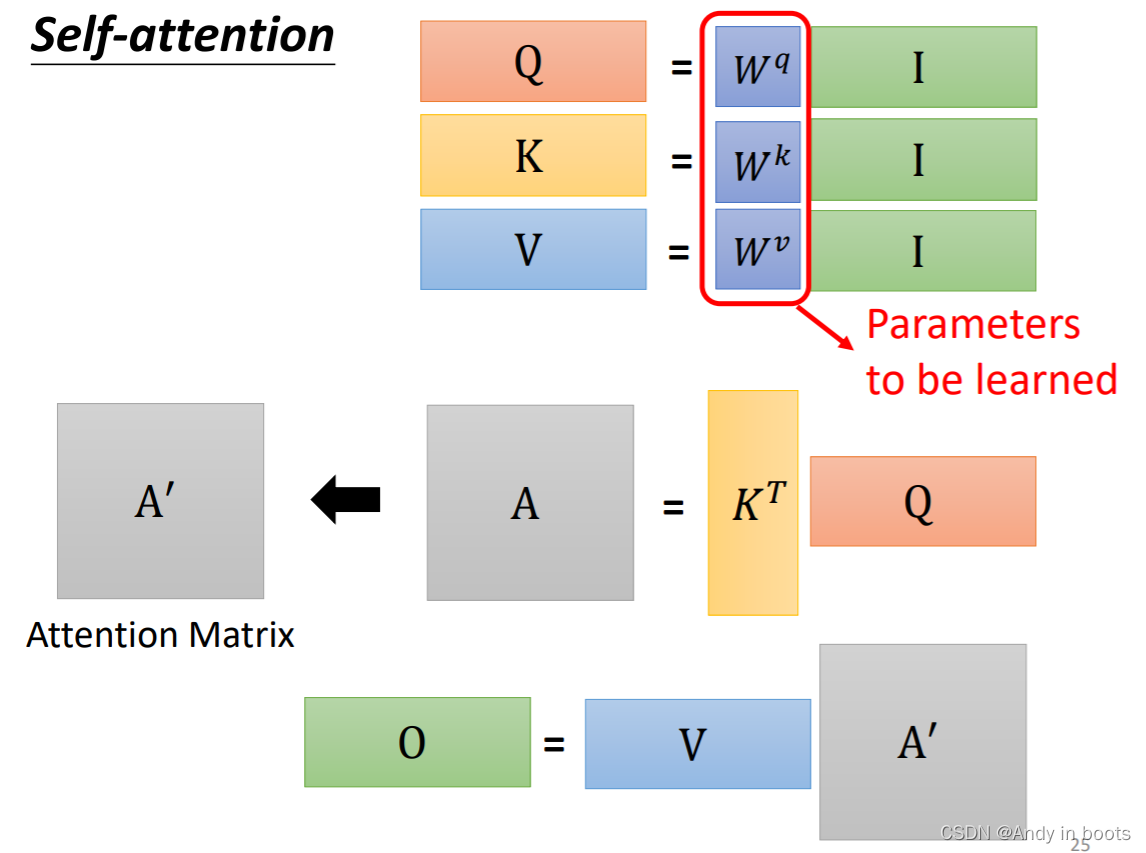
2.2 Matrix transpose
从矩阵乘法的视角来看,每一个输出都要乘相应的矩阵得到相应值,所以我们可以把他们拼起来当作
I
I
I计算。

所以我们可以把之后的计算也用矩阵计算进行表示

同理可得到输出
b
b
b

所以整个过程都可以表示成一连串的矩阵计算,其中只有
W
q
W^q
Wq,
W
k
W^k
Wk,
W
v
W^v
Wv是未知量需要学习得到。
2.3 Multi-head Self-attention
在相关这种定义中,也许不只有一种相关性,所以有时我们需要多个
q
q
q来表示多种的相关性。
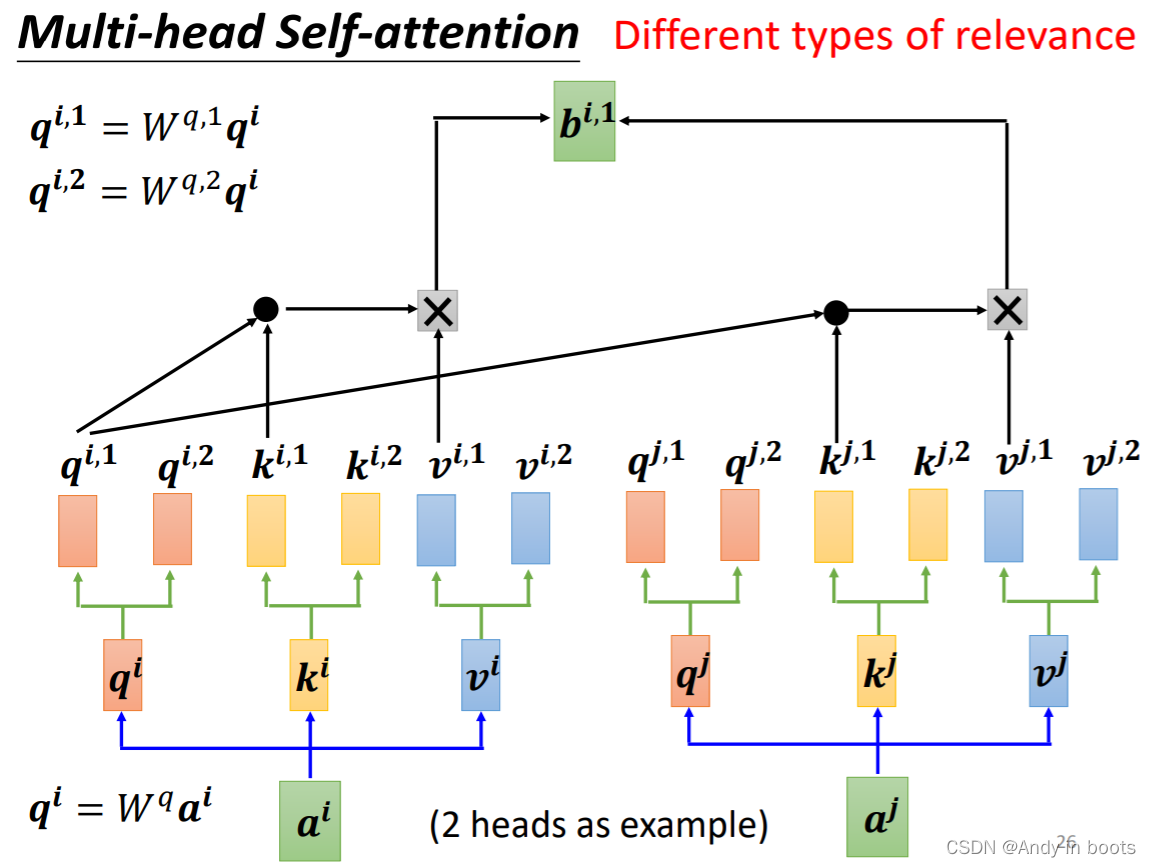
之后可能会将结果拼起来通过矩阵乘法得到结果,送到下一层。

2.4 Positional Encoding
但是Self-attention的输入并没有表示出位置信息,每个位置的输入是一样地位的。
所以我们要用Positional Encoding的技术添加位置信息
我们在每个位置都给一个vector表示,把它加到输入中。
下图右就是最早的transform中用的vector。
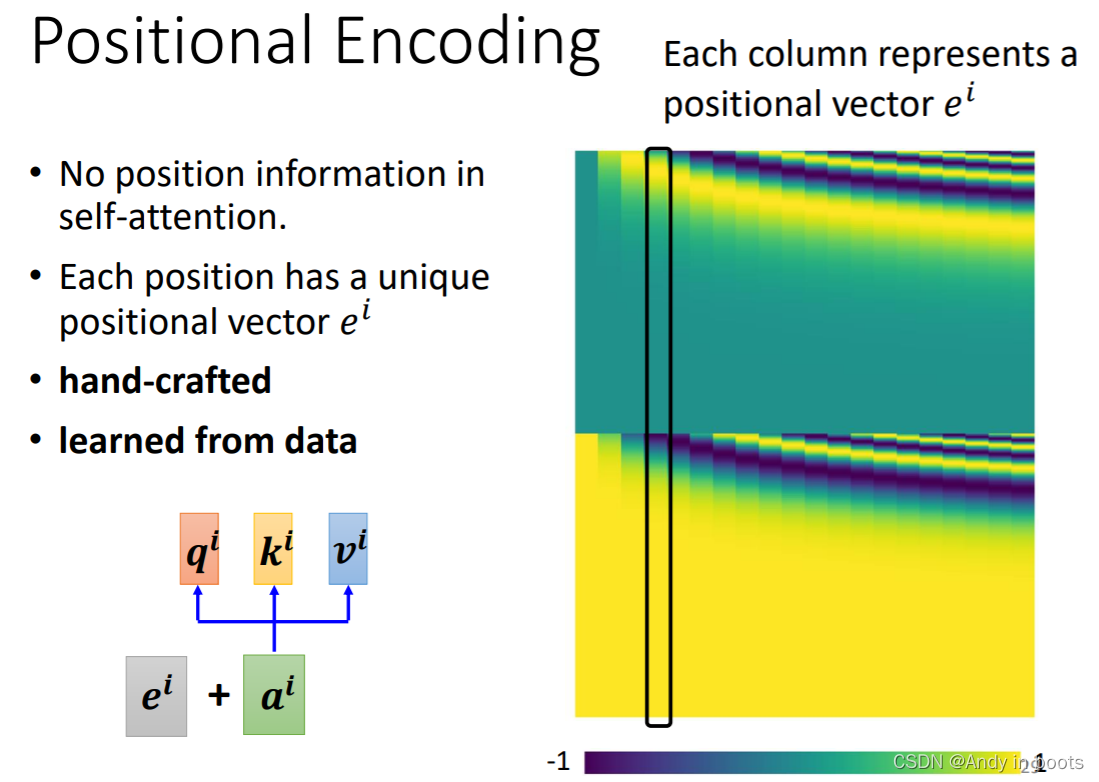
Positional Encoding这还是一个尚待研究的问题。
3. Others
3.1 Using
注意力机制在NLP方向一直被广泛使用
但是在语音方面也可以使用,我们只看语音信号时,由于信息量太大,所以只看一小部分的咨询
在影像方向也会使用Self-attention,我们可以把每一个像素位置看成一个三维的向量,这样就可以看作成一个Vector set,使用Self-attention进行处理。
比如以下两篇论文。

3.2 Self-attention v.s. CNN
Self-attention和CNN相比:
- CNN可以看作成一种简化版的Self-attention,确定一个小的感受野,受限制。
- Self-attention考虑所有输入进行学习,好像是自己学习得到感受野(根据相关性决定感受野的形状、位置、相关),感受野可以不相连

在这篇论文中说明了CNN是Self-attention的特例,只要设定了合适的参数,它可以做到跟CNN一样的事情
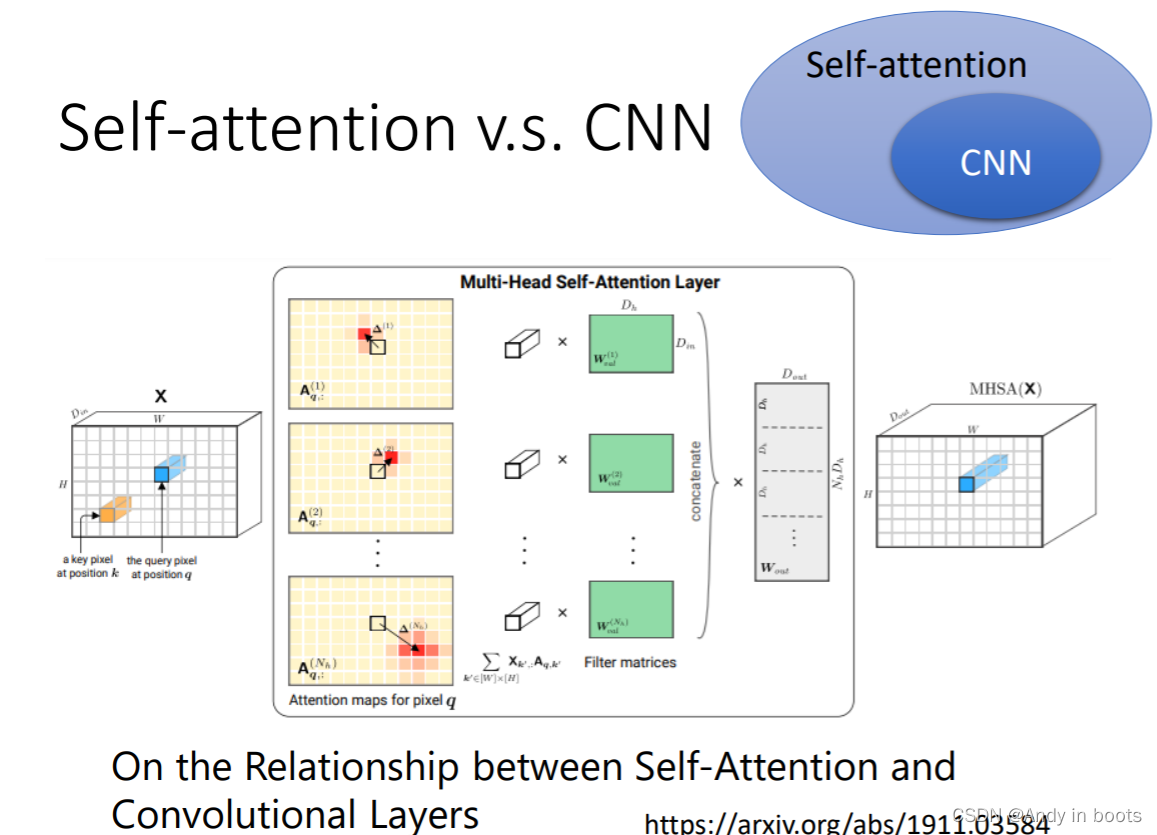
根据不同的数据量也可以说明Self-attention较为灵活(弹性大),需要更大的数据量进行训练。

3.2 Self-attention v.s. RNN
RNN(Recurrent Neural Network)现在大部分都被Self-attention所取代了,RNN也是要处理输入是一个序列的情况,基本结构如下,有一个计算顺序,每一个输入只考虑到了前面的输入情况,但是无法考虑到后面vector的信息(但是RNN也可以是双向的)
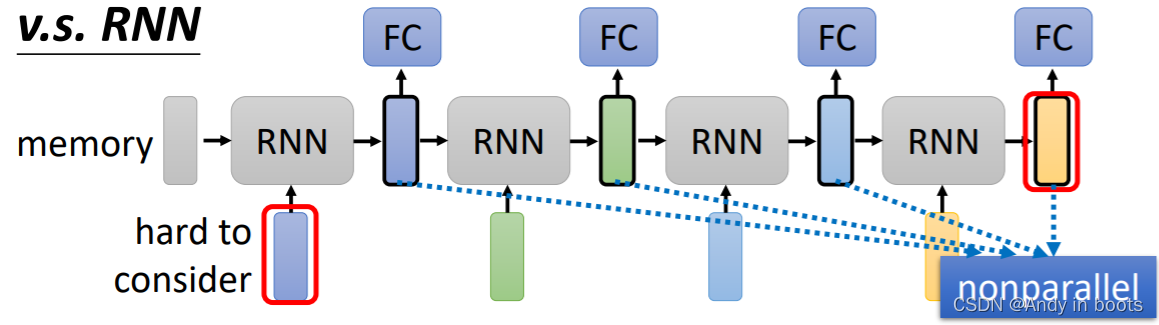
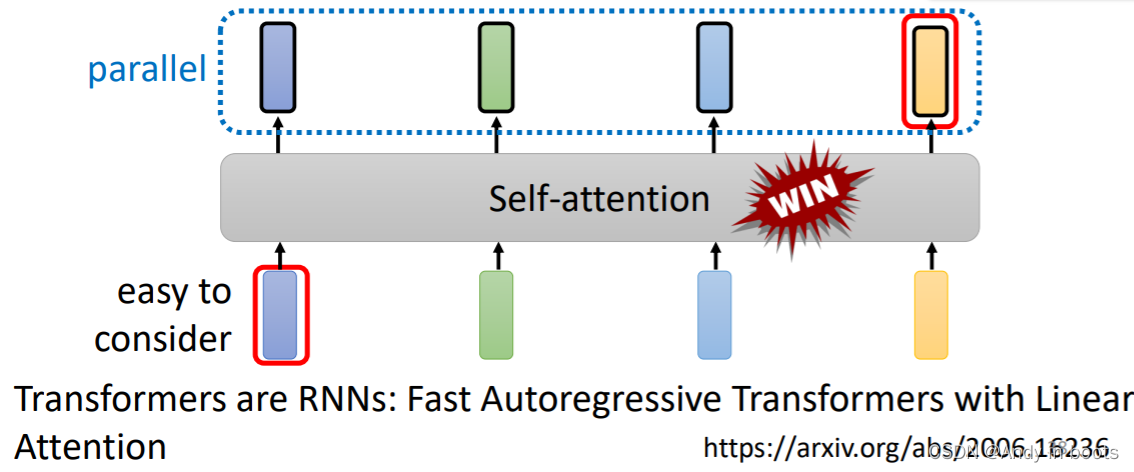
但是Self-attention每一个输入都考虑到了所有input,与RNN相比:
- 如果最后一个vector要考虑第一个vector,RNN需要一直存在memory中,而self-attention不需要,有一种天涯若比邻的感觉
- RNN无法平行化处理输入,运算速度与效率上Self-attention更有优势

3.2 Self-attention for Graph
在图中我们不仅有点的信息,我们还有边的信息,所以我们可以用edge来表示互相的关联性,不需要用机器找出来,我们就可以只计算有相连edge的node之间的score
这种思路就是一种GNN(Graph Neural Network)

4. More
有很多相关的变形,快的训练速度等等方法
















 957
957











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









