







问题描述
**平台: **ambari+hdp
**计算引擎: **hive+tez
**数据量: **7张表,单表千万级数据
**遇到问题: **提交一个计算任务将集群中memory沾满(不存在笛卡尔积,就最后指标字段只有7个左右)
解决方案
解决方案一
最开始解决问题思路是从三点出发:yarn、hive、tez的内存配置
-
yarn的“yarn.scheduler.minimum-allocation-mb”和“yarn.scheduler.maximum-allocation-mb”这两参数,在HDP上对应下图

-
hive的“hive.tez.container.size”、“hive_server2_heapsize”这里两个参数,在HDP上对应下图

-
tez的“tez.am.resource.memory.mb”、“tez.task.resource.memory.mb”这两个参数,在HDP上对应下图
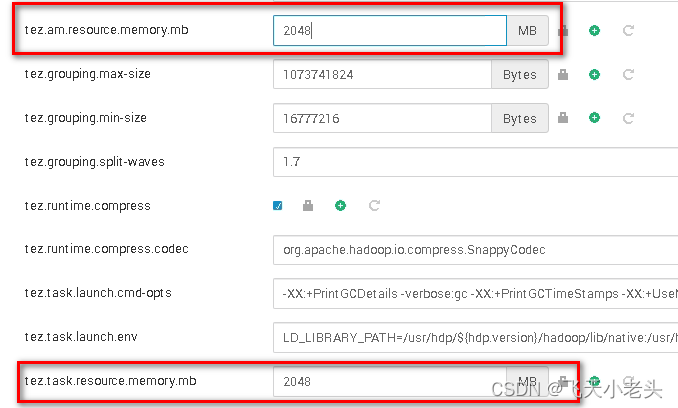
以上述的三个组件的内存配置为出发点经过一系列的调整,经查阅很多资料(这里就不对过程进行详细介绍了),经过各种尝试,在执行查询sql的时候还是会沾满yarn的内存计算资源。
解决方案二
这个时候就不从内存配置为出发点了,这个时候我在考虑是不是yanr的调度器的配置问题,经查看详细配置发现用户可申请的资源默认为1,也就是100%,如下图
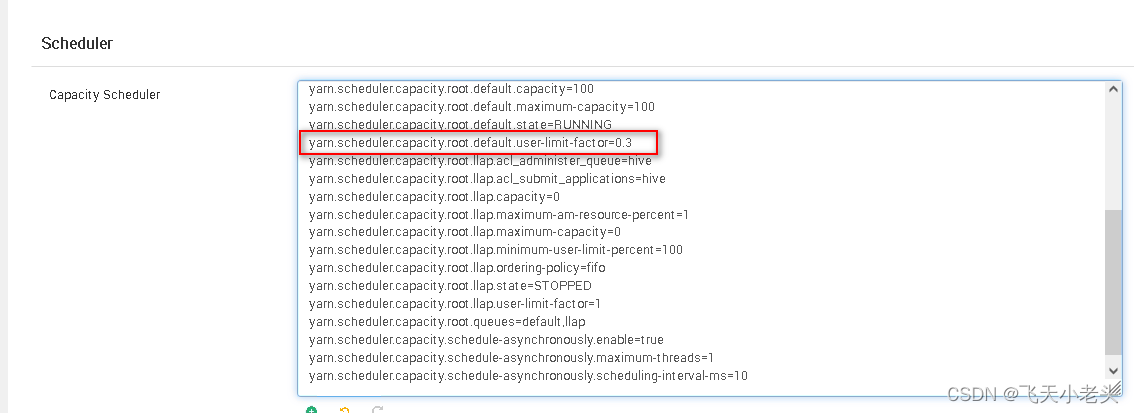
就是上图红框中的参数,原来默认值为1,这个参数要根据提交到yarn的具体任务进行配置,比如就是有大体量的计算任务那就是要将这个参数配置到1或者0.8,0.9等,如果是有大体量任务的情况下可以将用户进行队列分配,专门针对小任务配置个用户队列,中型任务配置一个用户队列,对大任务配置一个用户队列,这里我配置单个计算任务最高可申请30%的内存,因为目前所有的指标计算没有太大体量的,集群的30%内存资源是完全能够满足的。经过此配置后再次执行sql,问题得到解决。















 4163
4163











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









