







一、常用的调优参数
1)调优参数列表
(1)Resourcemanager 相关
yarn.resourcemanager.scheduler.client.thread-count ResourceManager 处理调度器请求的线程数量
yarn.resourcemanager.scheduler.class 配置调度器
(2)Nodemanager 相关
yarn.nodemanager.resource.memory-mb NodeManager 使用内存数
yarn.nodemanager.resource.system-reserved-memory-mb NodeManager 为系统保留多少内存,和上一个参数二者取一即可
yarn.nodemanager.resource.cpu-vcores NodeManager 使用 CPU 核数
yarn.nodemanager.resource.count-logical-processors-as-cores 是否将虚拟核数当作 CPU 核数
yarn.nodemanager.resource.pcores-vcores-multiplier 虚拟核数和物理核数乘数,例如:4 核 8 线程,该参数就应设为 2
yarn.nodemanager.resource.detect-hardware-capabilities 是否让 yarn 自己检测硬件进行配置
yarn.nodemanager.pmem-check-enabled 是否开启物理内存检查限制 container
yarn.nodemanager.vmem-check-enabled 是否开启虚拟内存检查限制 container
yarn.nodemanager.vmem-pmem-ratio 虚拟内存物理内存比例
(3)Container 容器相关
yarn.scheduler.minimum-allocation-mb 容器最小内存
yarn.scheduler.maximum-allocation-mb 容器最大内存
yarn.scheduler.minimum-allocation-vcores 容器最小核数
yarn.scheduler.maximum-allocation-vcores 容器最大核数
2)参数具体使用案例
1、Yarn 生产环境核心参数配置案例
1)需求:从 1G 数据中,统计每个单词出现次数。服务器 3 台,每台配置 4G 内存,4 核CPU,4 线程。
2)需求分析:
1G / 128m = 8 个 MapTask;1 个 ReduceTask;1 个 mrAppMaster
平均每个节点运行 10 个 / 3 台 ≈ 3 个任务(4 3 3)
3)修改 yarn-site.xml 配置参数如下:
<!-- 选择调度器,默认容量 -->
<property>
<description>The class to use as the resource scheduler</description>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
<!-- ResourceManager 处理调度器请求的线程数量,默认 50;如果提交的任务数大于 50,可以
增加该值,但是不能超过 3 台 * 4 线程 = 12 线程(去除其他应用程序实际不能超过 8) -->
<property>
<description>Number of threads to handle schedulerinterface.</description>
<name>yarn.resourcemanager.scheduler.client.thread-count</name>
<value>8</value>
</property>
<!-- 是否让 yarn 自动检测硬件进行配置,默认是 false,如果该节点有很多其他应用程序,建议
手动配置。如果该节点没有其他应用程序,可以采用自动 -->
<property>
<description>Enable auto-detection of node capabilities such asmemory and CPU.</description>
<name>yarn.nodemanager.resource.detect-hardware-capabilities</name>
<value>false</value>
</property>
<!-- 是否将虚拟核数当作 CPU 核数,默认是 false,采用物理 CPU 核数 -->
<property>
<description>Flag to determine if logical processors(such as
hyperthreads) should be counted as cores. Only applicable on Linux
when yarn.nodemanager.resource.cpu-vcores is set to -1 and
yarn.nodemanager.resource.detect-hardware-capabilities is true.
</description>
<name>yarn.nodemanager.resource.count-logical-processors-as-cores</name>
<value>false</value>
</property>
<!-- 虚拟核数和物理核数乘数,默认是 1.0 -->
<property>
<description>Multiplier to determine how to convert phyiscal cores to
vcores. This value is used if yarn.nodemanager.resource.cpu-vcores
is set to -1(which implies auto-calculate vcores) and
yarn.nodemanager.resource.detect-hardware-capabilities is set to true.
The number of vcores will be calculated as number of CPUs * multiplier.
</description>
<name>yarn.nodemanager.resource.pcores-vcores-multiplier</name>
<value>1.0</value>
</property>
<!-- NodeManager 使用内存数,默认 8G,修改为 4G 内存 -->
<property>
<description>Amount of physical memory, in MB, that can be allocated
for containers. If set to -1 and
yarn.nodemanager.resource.detect-hardware-capabilities is true, it is
automatically calculated(in case of Windows and Linux).
In other cases, the default is 8192MB.
</description>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<!-- nodemanager 的 CPU 核数,不按照硬件环境自动设定时默认是 8 个,修改为 4 个 -->
<property>
<description>Number of vcores that can be allocated
for containers. This is used by the RM scheduler when allocating
resources for containers. This is not used to limit the number of
CPUs used by YARN containers. If it is set to -1 and
yarn.nodemanager.resource.detect-hardware-capabilities is true, it is
automatically determined from the hardware in case of Windows and Linux.
In other cases, number of vcores is 8 by default.</description>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>4</value>
</property>
<!-- 容器最小内存,默认 1G -->
<property>
<description>The minimum allocation for every container request at the
RM in MBs. Memory requests lower than this will be set to the value of
this property. Additionally, a node manager that is configured to have
less memory than this value will be shut down by the resource manager.
</description>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1024</value>
</property>
<!-- 容器最大内存,默认 8G,修改为 2G -->
<property>
<description>The maximum allocation for every container request at the
RM in MBs. Memory requests higher than this will throw an
InvalidResourceRequestException.
</description>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
</property>
<!-- 容器最小 CPU 核数,默认 1 个 -->
<property>
<description>The minimum allocation for every container request at the
RM in terms of virtual CPU cores. Requests lower than this will be set to
the value of this property. Additionally, a node manager that is configured
to have fewer virtual cores than this value will be shut down by the
resource manager.
</description>
<name>yarn.scheduler.minimum-allocation-vcores</name>
<value>1</value>
</property>
<!-- 容器最大 CPU 核数,默认 4 个,修改为 2 个 -->
<property>
<description>The maximum allocation for every container request at the
RM in terms of virtual CPU cores. Requests higher than this will throw an
InvalidResourceRequestException.</description>
<name>yarn.scheduler.maximum-allocation-vcores</name>
<value>2</value>
</property>
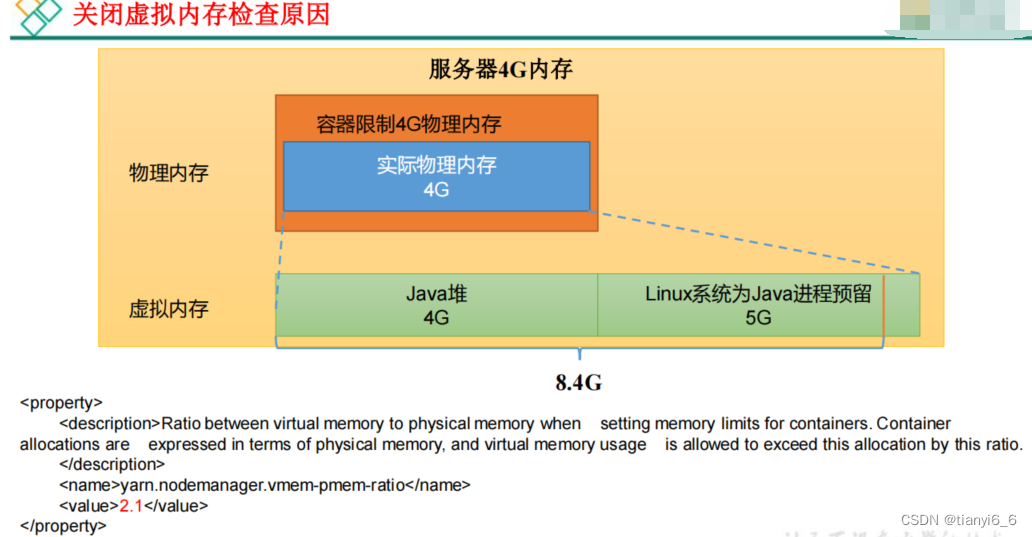
<!-- 虚拟内存检查,默认打开,修改为关闭 -->
<property>
<description>Whether virtual memory limits will be enforced for
containers.</description>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 虚拟内存和物理内存设置比例,默认 2.1 -->
<property>
<description>Ratio between virtual memory to physical memory when
setting memory limits for containers. Container allocations are
expressed in terms of physical memory, and virtual memory usage is
allowed to exceed this allocation by this ratio.
</description>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
4)分发配置
注意:如果集群的硬件资源不一致,要每个 NodeManager 单独配置
5)重启集群
[atguigu@hadoop102 hadoop-3.1.3]$ sbin/stop-yarn.sh
[atguigu@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh
6)执行 WordCount 程序
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop jar
share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount
/input /output
7)观察 Yarn 任务执行页面
http://hadoop103:8088/cluster/apps
2、容量调度器使用
容量调度器多队列提交案例
1)在生产环境怎么创建队列?
(1)调度器默认就 1 个 default 队列,不能满足生产要求。
(2)按照框架:hive /spark/ flink 每个框架的任务放入指定的队(企业用的不是特别多)
(3)按照业务模块:登录注册、购物车、下单、业务部门 1、业务部门 2
2)创建多队列的好处?
(1)因为担心员工不小心,写递归死循环代码,把所有资源全部耗尽。 (2)实现任务的降级使用,特殊时期保证重要的任务队列资源充足。
业务部门 1(重要)=》业务部门 2(比较重要)=》下单(一般)=》购物车(一般)=》登录注册(次要)
需求
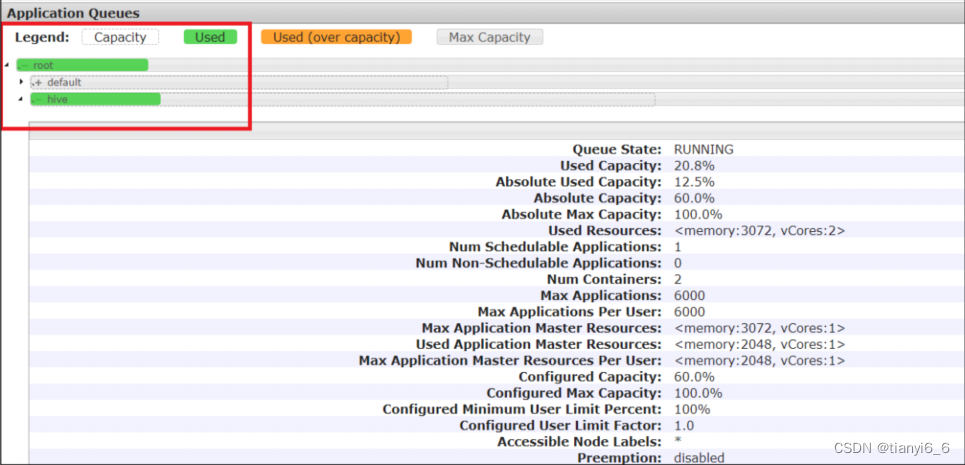
需求 1:default 队列占总内存的 40%,最大资源容量占总资源 60%,hive 队列占总内存的 60%,最大资源容量占总资源 80%。
需求 2:配置队列优先级
配置多队列的容量调度器
1)在 capacity-scheduler.xml 中配置如下:
(1)修改如下配置
<!-- 指定多队列,增加 hive 队列 -->
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>default,hive</value>
<description>
The queues at the this level (root is the root queue).
</description>
</property>
<!-- 降低 default 队列资源额定容量为 40%,默认 100% -->
<property>
<name>yarn.scheduler.capacity.root.default.capacity</name>
<value>40</value>
</property>
<!-- 降低 default 队列资源最大容量为 60%,默认 100% -->
<property>
<name>yarn.scheduler.capacity.root.default.maximum-capacity</name>
<value>60</value>
</property>
(2)为新加队列添加必要属性:
<!-- 指定 hive 队列的资源额定容量 -->
<property>
<name>yarn.scheduler.capacity.root.hive.capacity</name>
<value>60</value>
</property>
<!-- 用户最多可以使用队列多少资源,1 表示 -->
<property>
<name>yarn.scheduler.capacity.root.hive.user-limit-factor</name>
<value>1</value>
</property>
<!-- 指定 hive 队列的资源最大容量 -->
<property>
<name>yarn.scheduler.capacity.root.hive.maximum-capacity</name>
<value>80</value>
</property>
<!-- 启动 hive 队列 -->
<property>
<name>yarn.scheduler.capacity.root.hive.state</name>
<value>RUNNING</value>
</property>
<!-- 哪些用户有权向队列提交作业 -->
<property>
<name>yarn.scheduler.capacity.root.hive.acl_submit_applications</name>
<value>*</value>
</property>
<!-- 哪些用户有权操作队列,管理员权限(查看/杀死) -->
<property>
<name>yarn.scheduler.capacity.root.hive.acl_administer_queue</name>
<value>*</value>
</property>
<!-- 哪些用户有权配置提交任务优先级 -->
<property>
<name>yarn.scheduler.capacity.root.hive.acl_application_max_priority</nam
e>
<value>*</value>
</property>
<!-- 任务的超时时间设置:yarn application -appId appId -updateLifetime Timeout
参考资料: https://blog.cloudera.com/enforcing-application-lifetime-slasyarn/ -->
<!-- 如果 application 指定了超时时间,则提交到该队列的 application 能够指定的最大超时
时间不能超过该值。
-->
<property>
<name>yarn.scheduler.capacity.root.hive.maximum-applicationlifetime</name>
<value>-1</value>
</property>
<!-- 如果 application 没指定超时时间,则用 default-application-lifetime 作为默认
值 -->
<property>
<name>yarn.scheduler.capacity.root.hive.default-applicationlifetime</name>
<value>-1</value>
</property>
2)分发配置文件
3)重启 Yarn 或者执行 yarn rmadmin -refreshQueues 刷新队列,就可以看到两条队列:
[atguigu@hadoop102 hadoop-3.1.3]$ yarn rmadmin -refreshQueues
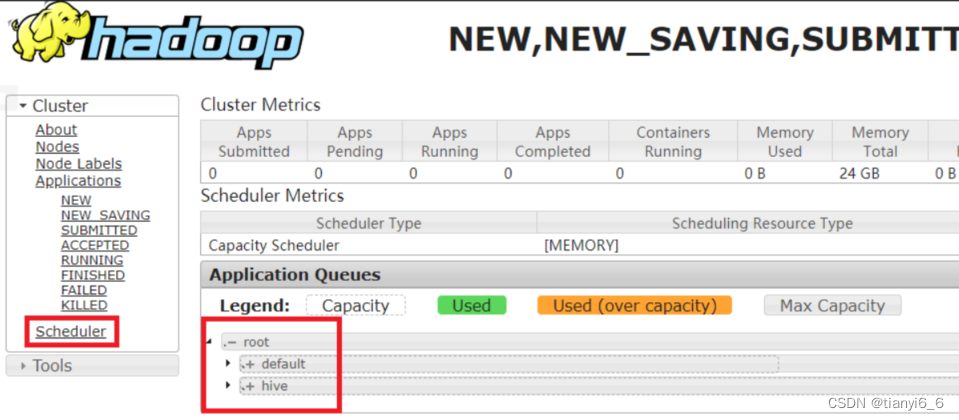
向 Hive 队列提交任务
1)hadoop jar 的方式
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount -D mapreduce.job.queuename=hive /input /output
注: -D 表示运行时改变参数值
2)打 jar 包的方式
默认的任务提交都是提交到 default 队列的。如果希望向其他队列提交任务,需要在Driver 中声明:
public class WcDrvier {
public static void main(String[] args) throws IOException,
ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
conf.set("mapreduce.job.queuename","hive");
//1. 获取一个 Job 实例
Job job = Job.getInstance(conf);
。。。 。。。
//6. 提交 Job
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}
这样,这个任务在集群提交时,就会提交到 hive 队列:
任务优先级
容量调度器,支持任务优先级的配置,在资源紧张时,优先级高的任务将优先获取资源。默认情况,Yarn 将所有任务的优先级限制为 0,若想使用任务的优先级功能,须开放该限制。
1)修改 yarn-site.xml 文件,增加以下参数
<property>
<name>yarn.cluster.max-application-priority</name>
<value>5</value>
</property>
2)分发配置,并重启 Yarn
[atguigu@hadoop102 hadoop]$ xsync yarn-site.xml
[atguigu@hadoop103 hadoop-3.1.3]$ sbin/stop-yarn.sh
[atguigu@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh
3)模拟资源紧张环境,可连续提交以下任务,直到新提交的任务申请不到资源为止。
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar pi 5 2000000
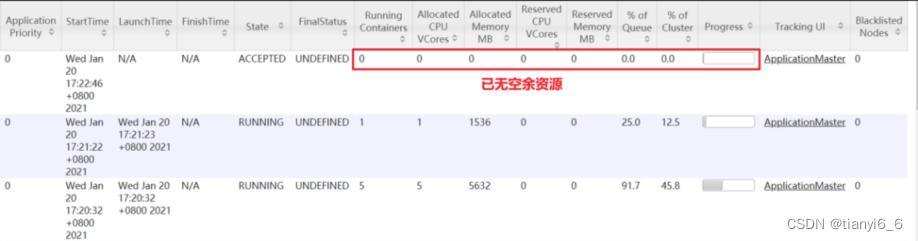
4)再次重新提交优先级高的任务
[atguigu@hadoop102 hadoop-3.1.3\]$ hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar pi -D mapreduce.job.priority=5 5 2000000
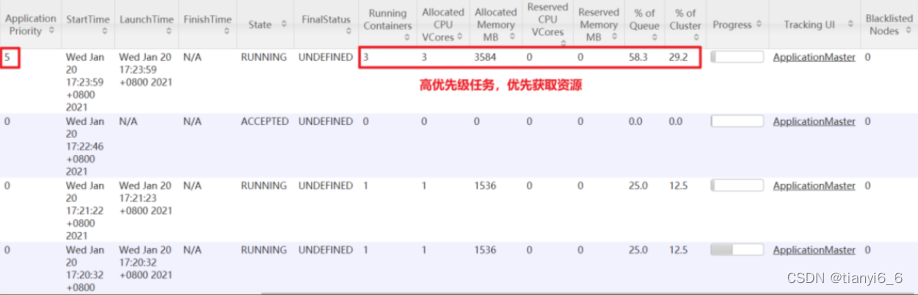
5)也可以通过以下命令修改正在执行的任务的优先级。
yarn application -appID -updatePriority 优先级
[atguigu@hadoop102 hadoop-3.1.3]$ yarn application -appID
application_1611133087930_0009 -updatePriority 5
3、公平调度器使用
需求
创建两个队列,分别是 test 和 atguigu(以用户所属组命名)。期望实现以下效果:若用户提交任务时指定队列,则任务提交到指定队列运行;若未指定队列,test 用户提交的任务到 root.group.test 队列运行,atguigu 提交的任务到 root.group.atguigu 队列运行(注:group 为用户所属组)。
公平调度器的配置涉及到两个文件,一个是 yarn-site.xml,另一个是公平调度器队列分配文件 fair-scheduler.xml(文件名可自定义)。
(1)配置文件参考资料:
https://hadoop.apache.org/docs/r3.1.3/hadoop-yarn/hadoop–yarnsite/FairScheduler.html
(2)任务队列放置规则参考资料:
https://blog.cloudera.com/untangling-apache-hadoop-yarn-part-4-fair-scheduler-queue-basics/
配置多队列的公平调度器
1)修改 yarn-site.xml 文件,加入以下参数
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairS
cheduler</value>
<description>配置使用公平调度器</description>
</property>
<property>
<name>yarn.scheduler.fair.allocation.file</name>
<value>/opt/module/hadoop-3.1.3/etc/hadoop/fair-scheduler.xml</value>
<description>指明公平调度器队列分配配置文件</description>
</property>
<property>
<name>yarn.scheduler.fair.preemption</name>
<value>false</value>
<description>禁止队列间资源抢占</description>
</property>
2)配置 fair-scheduler.xml
<?xml version="1.0"?>
<allocations>
<!-- 单个队列中 Application Master 占用资源的最大比例,取值 0-1 ,企业一般配置 0.1
-->
<queueMaxAMShareDefault>0.5</queueMaxAMShareDefault>
<!-- 单个队列最大资源的默认值 test atguigu default -->
<queueMaxResourcesDefault>4096mb,4vcores</queueMaxResourcesDefault>
<!-- 增加一个队列 test -->
<queue name="test">
<!-- 队列最小资源 -->
<minResources>2048mb,2vcores</minResources>
<!-- 队列最大资源 -->
<maxResources>4096mb,4vcores</maxResources>
<!-- 队列中最多同时运行的应用数,默认 50,根据线程数配置 -->
<maxRunningApps>4</maxRunningApps>
<!-- 队列中 Application Master 占用资源的最大比例 -->
<maxAMShare>0.5</maxAMShare>
<!-- 该队列资源权重,默认值为 1.0 -->
<weight>1.0</weight>
<!-- 队列内部的资源分配策略 -->
<schedulingPolicy>fair</schedulingPolicy>
</queue>
<!-- 增加一个队列 atguigu -->
<queue name="atguigu" type="parent">
<!-- 队列最小资源 -->
<minResources>2048mb,2vcores</minResources>
<!-- 队列最大资源 -->
<maxResources>4096mb,4vcores</maxResources>
<!-- 队列中最多同时运行的应用数,默认 50,根据线程数配置 -->
<maxRunningApps>4</maxRunningApps>
<!-- 队列中 Application Master 占用资源的最大比例 -->
<maxAMShare>0.5</maxAMShare>
<!-- 该队列资源权重,默认值为 1.0 -->
<weight>1.0</weight>
<!-- 队列内部的资源分配策略 -->
<schedulingPolicy>fair</schedulingPolicy>
</queue>
<!-- 任务队列分配策略,可配置多层规则,从第一个规则开始匹配,直到匹配成功 -->
<queuePlacementPolicy>
<!-- 提交任务时指定队列,如未指定提交队列,则继续匹配下一个规则; false 表示:如果指
定队列不存在,不允许自动创建-->
<rule name="specified" create="false"/>
<!-- 提交到 root.group.username 队列,若 root.group 不存在,不允许自动创建;若
root.group.user 不存在,允许自动创建 -->
<rule name="nestedUserQueue" create="true">
<rule name="primaryGroup" create="false"/>
</rule>
<!-- 最后一个规则必须为 reject 或者 default。Reject 表示拒绝创建提交失败,
default 表示把任务提交到 default 队列 -->
<rule name="reject" />
</queuePlacementPolicy>
</allocations>
3)分发配置并重启 Yarn
[atguigu@hadoop102 hadoop]$ xsync yarn-site.xml
[atguigu@hadoop102 hadoop]$ xsync fair-scheduler.xml
[atguigu@hadoop103 hadoop-3.1.3]$ sbin/stop-yarn.sh
[atguigu@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh
测试提交任务
1)提交任务时指定队列,按照配置规则,任务会到指定的 root.test 队列
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar pi -Dmapreduce.job.queuename=root.test 1 1
2)提交任务时不指定队列,按照配置规则,任务会到 root.atguigu.atguigu 队列
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar pi 1 1

















 1353
1353











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











