






集合框架中的数据结构(未完待施工)
一、List
List是线性表,数据存储方式是线性的,List中主要分为ArrayList(顺序表)和LinkedList(单链表)
线性表(linear list)是n个具有相同特性的数据元素的有限序列。 线性表是一种在实际中广泛使用的数据结构,常见的线性表:顺序表、链表、栈、队列、字符串…
线性表在逻辑上是线性结构,也就说是连续的一条直线。但是在物理结构上并不一定是连续的,线性表在物理上存储时,通常以数组和链式结构的形式存储。
1.ArrayList(顺序表)
顺序表采用数组存储。在数组上完成数据的增删查改。数组的长度是可变的,动态开辟数组空间,由于它的底层是数组,所以查找元素时可以根据下标地址查找,这样速度会很快,但相对的,由于数组增删元素需要移位,所以速度会比较慢。

接口实现
public class SeqList {
// 打印顺序表
public void display() { }
// 在 pos 位置新增元素
public void add(int pos, int data) { }
// 判定是否包含某个元素
public boolean contains(int toFind) { return true; }
// 查找某个元素对应的位置
public int search(int toFind) { return -1; }
// 获取 pos 位置的元素
public int getPos(int pos) { return -1; }
// 给 pos 位置的元素设为 value
public void setPos(int pos, int value) { }
//删除第一次出现的关键字key
public void remove(int toRemove) { }
// 获取顺序表长度
public int size() { return 0; }
// 清空顺序表
public void clear() { }
}
2.LinkedList(链表)
链表是一种物理存储结构上非连续存储结构,数据元素的逻辑顺序是通过链表中的引用链接次序实现的(Node节点+指针)。
链表的增删元素只需要操作元素的指针即可,所以链表增删速度快,同时由于链表的遍历只能通过连接结点的上一个指针和下一个指针,所以它的查找速度会比较慢

接口实现
// 1、无头单向非循环链表实现
public class SingleLinkedList {
//头插法
public void addFirst(int data);
//尾插法
public void addLast(int data);
//任意位置插入,第一个数据节点为0号下标
public boolean addIndex(int index,int data);
//查找是否包含关键字key是否在单链表当中
public boolean contains(int key);
//删除第一次出现关键字为key的节点
public void remove(int key);
//删除所有值为key的节点
public void removeAllKey(int key);
//得到单链表的长度
public int size();
public void display();
public void clear();
}
// 2、无头双向链表实现
public class DoubleLinkedList {
//头插法
public void addFirst(int data);
//尾插法
public void addLast(int data);
//任意位置插入,第一个数据节点为0号下标
public boolean addIndex(int index,int data);
//查找是否包含关键字key是否在单链表当中
public boolean contains(int key);
//删除第一次出现关键字为key的节点
public void remove(int key);
//删除所有值为key的节点
public void removeAllKey(int key);
//得到单链表的长度
public int size();
public void display();
public void clear();
}
二、Set
一般把搜索的数据称为关键字(Key),和关键字对应的称为值(Value),所以模型会有两种:
- 纯 key 模型,即我们 Set 要解决的事情,只需要判断关键字在不在集合中即可,没有关联的 value;
- Key-Value 模型,即我们 Map 要解决的事情,需要根据指定 Key 找到关联的 Value。
这里我们先研究纯Key模型:
Set集合自带去重功能
1.HashSet
示例:
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
public class TestDemo {
public static void main(String[] args) {
Set<String> set = new HashSet<>() ;
set.add("Hello");
// 重复元素
set.add("Hello");
set.add("World");
set.add("Hello");
set.add("Java");
System.out.println(set);
Iterator<String> it = set.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
}
}
运行结果:
[Java, Hello, World]
Java
Hello
World
HashSet集合是依赖自身的数据结构去重的,它的底层结构是哈希表,哈希表的本质是数组和链表的结合(JDK1.8中增加了红黑树结构,当链表长度大于8转为红黑树)
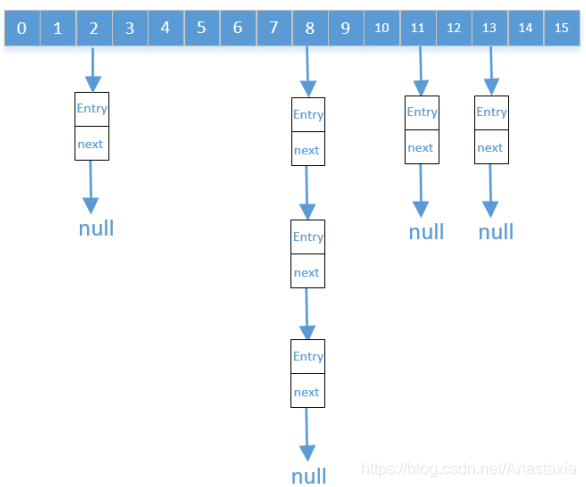
- 数组中的每个元素相当于是一个hashCode值,每个元素的hashCode值不同
- 数组中的每个元素下的链表的hashCode值相同
当把一个对象添加到HashSet中时,得到对象的哈希值(hashCode),用这个值跟集合中的所有元素进行比较
如果hashCode值不同,就认为这两个对象是不同的,就可以把这个元素添加到集合中去
如果hashCode值和集合中的某个元素相同,这时不能直接判断该对象就和那个元素一致,而是要接着判断该对象的地址值和调用该对象的 equals() 方法
二者中有一个返回值为true,就认为该对象和集合中的对象是重复的,因此不添加
二者返回值均为false,就认为该对象和集合中的对象不相同,因此可以添加
代码表示应该是这样的:
( e1.hashCode == e2.hashCode ) && ( e1 == e2 || e1.equals(e2) )
自定义去重时要重写hashCode方法和equals方法
2.TreeSet
底层原理
底层是基于TreeMap来实现的,所以底层结构也是红黑树,TreeSet和HashSet不同的是不需要重写hashCode()和equals()方法,因为它去重是依靠CompareTo比较器来去重,因为结构是红黑树,所以每次插入都会遍历比较来寻找节点插入位置,如果发现某个节点的值是一样的那就会直接覆盖。
如果compareTo返回0,说明是重复的,返回的是自己的某个属性和另一个对象的某个属性的差值,如果是负数,则往前面排,如果是正数,往后面排
示例:
package Collection.Set.TreeSet;
import java.util.Iterator;
import java.util.TreeSet;
/**
* TreeSet的使用
* 存储结构:红黑树
*/
public class Demo1 {
public static void main(String[] args) {
//创建集合
TreeSet<String> treeSet = new TreeSet<>();
//1.添加元素
treeSet.add("xyz");
treeSet.add("abc");
treeSet.add("hello");
System.out.println("元素个数" + treeSet.size());
System.out.println(treeSet.toString());
//2.删除元素
//treeSet.remove("xyz");
//System.out.println(treeSet.toString());
//3.遍历
//3.1增强for
System.out.println("------------");
for (String string : treeSet){
System.out.println(string);
}
//使用迭代器
System.out.println("------------");
Iterator<String> it = treeSet.iterator();
while (it.hasNext()){
System.out.println(it.next());
}
//判断
System.out.println(treeSet.contains("xyz"));
}
}















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









