






前言

AgentClinic: a multimodal agent benchmark to evaluate AI in simulated clinical environments
摘要
在临床场景中评估大型语言模型(LLM)对于评估其潜在的临床效用至关重要。现有的基准测试主要依赖于静态问答,这不能准确描述临床决策的复杂性和顺序性。在这里,我们介绍AgentClinic,一个用于评估模拟临床环境中LLM的多模态代理基准测试,其中包括患者互动、在不完整信息下进行的多模态数据收集,以及各种工具的使用,从而在九个医学专业和七种语言中进行深入评估。我们发现,在AgentClinic的顺序决策格式中解决MedQA问题要困难得多,导致诊断准确率可能降至原始准确率的十分之一以下。总体而言,我们观察到,来自克洛德-3.5的代理在大多数设置中优于其他LLM骨干。尽管如此,我们看到LLM在使用工具(如经验学习、自适应检索和反思循环)的能力上存在显著差异。引人注目的是,Llama-3在使用笔记本电脑工具时表现出高达92%的相对改进,该工具允许编写和编辑跨病例持久的笔记。为了进一步审查我们的临床模拟,我们利用真实的电子健康记录,进行临床读者研究,用偏见扰动代理,并探索这一互动环境首次能够实现的新型以患者为中心的指标。
https://agentclinic.github.io/
https://github.com/samuelschmidgall/agentclinic
引言
人工智能(AI)的主要目标之一是构建能够解决各种问题的交互式系统。医疗AI领域继承了这一目标,希望开发出能够解决可改善患者结果的AI系统。最近,许多通用大型语言模型(LLMs)已经展示出解决难题的能力,其中一些难题甚至对人类来说都具有挑战性(Thirunavukarasu等人,2023年)。在这些模型中,LLMs在短时间内迅速提高了美国医学执照考试(USMLE)的平均分数,从2021年9月的38.1%(Gu等人,2021年)提高到2023年11月的90.2%(Nori等人,2023年)(人类及格分数为60%,人类专家分数为87%(Liévin等人,2023年))。虽然这些LLMs并非设计用来替代医疗从业者,但它们对于改善全球超过40%面临有限医疗服务获取机会的人口(Organization等人,2016年)以及日益紧张的全球医疗体系(McIntyre和Chow,2020年)的医疗可及性和规模可能是有益的。
然而,这些系统在实际临床环境中的应用仍然存在限制。近期,大型语言模型(LLMs)已展示出编码临床知识的能力(Singhal等人,2023年;Vaidya等人,2023年)、检索相关医学文本的能力(熊等人,2024年)以及执行准确的单轮医学问答的能力(陈等人,2023年;Lévin等人,2022年;Nori等人,2023年;Wu等人,2023年)。然而,临床工作是一种涉及顺序决策的多任务活动,要求医生在有限的信息和资源下处理不确定性,同时富有同情心地照顾患者并从他们那里获取相关信息。当前,这种能力并未反映在静态的多项选择题评估中(这在最近的文献中占主导地位),其中所有必要信息都以病例简介的形式呈现,LLMs的任务是回答问题,或者仅为给定问题选择最合理的答案选项。
在这项工作中,我们引入了AgentClinic,一个开源的多模态代理基准,用于模拟临床环境。我们在以往的工作基础上进行了改进,通过使用语言代理以及病人和医生代理来模拟临床环境的许多部分。通过与测量代理的互动,医生代理可以通过对话执行模拟的医疗检查(例如体温、血压、心电图)并订购医学影像读片(例如磁共振成像、X光)。我们还支持代理表现出24种已知存在于临床环境中的不同偏见的能力。我们还展示了来自9个医学专科的环境、7种不同的语言,以及一项关于整合各种代理工具和推理技术的研究。此外,我们的评估指标超越了诊断准确性,强调了患者代理,采用了诸如患者依从性和咨询评级等度量标准。
我们的主要贡献总结如下:
- 我们通过引入AgentClinic,挑战了如何评估用于医学诊断的大型语言和视觉模型。这些诊断挑战不是静态的问答任务,而是交互式的、对话驱动的、顺序决策环境,需要收集数据、安排适当的医学检查,并理解具有独特家族史、生活习惯、年龄类别和疾病的患者的医学图像。
- 一个可以整合可能影响患者和医生代理对话和决策的复杂偏见的系统。我们展示了受认知和隐性偏见影响的代理在诊断准确性和患者感知方面的结果。我们发现,医生和患者的偏见会降低诊断准确性,影响患者遵循治疗的意愿(依从性),减少患者对其医生的信任,并降低后续咨询的意愿。
- 我们引入了基于真实临床案例构建的患者代理,这些案例来源于电子健康记录数据,包括一个基于现实疾病测试结果的模拟医学检查(例如体温、血压、心电图)的代理系统。我们还介绍了来自九个医学专科和七个多语言环境的患者案例,以更好地支持专业应用和多样化的语言背景。我们还展示了临床医生对生成对话的现实感和同理心评分。
- 我们允许医生代理使用各种工具,如浏览网页、教科书、进行反思周期、在笔记本中记录和编辑笔记,该笔记本在不同患者场景中可以持续使用。我们展示了当前的LLM在使用这些工具时存在巨大的差异,有些模型显示出大幅度的准确率提升,而其他模型的准确率则有所下降。
核心速览
研究背景
-
研究问题 :这篇文章要解决的问题是如何在模拟的临床环境中评估大型语言模型(LLMs)的潜力,特别是其在医疗诊断中的应用。现有的基准测试主要依赖于静态问答,无法准确反映临床决策的复杂性和顺序性。
-
研究难点 :该问题的研究难点包括:临床决策的复杂性、顺序性、信息不完全下的多模态数据收集、以及各种工具的使用。
-
相关工作 :该问题的研究相关工作有:现有的医学知识编码、医学文本检索和单轮医学问答任务。然而,这些工作未能充分反映临床决策的顺序性和复杂性。
研究方法
这篇论文提出了AgentClinic,一个多模态代理基准,用于在模拟的临床环境中评估LLMs。具体来说,
-
多模态代理:AgentClinic使用四个语言代理:患者代理、医生代理、测量代理和调解员代理。每个代理都有特定的指令和信息,这些信息仅对该代理可见。医生代理的性能是被评估的对象,其他三个代理用于提供评估。
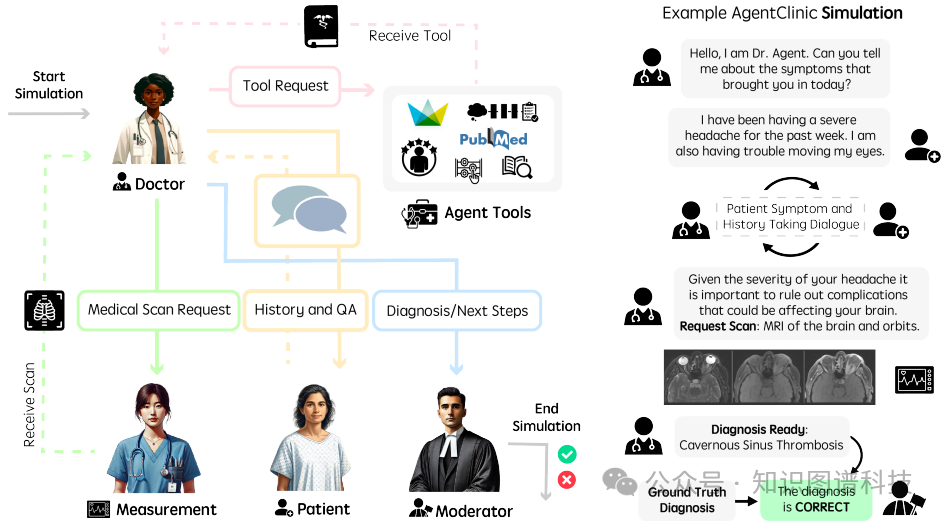
-
代理偏见:为了模拟临床环境中的复杂偏见,论文引入了认知偏见和隐性偏见。这些偏见通过在代理的系统提示中添加上下文来引入,例如性取向偏见和种族偏见。
-
代理构建:代理基于从美国医学执照考试(USMLE)、去识别的电子健康记录(MIMIC-IV)和新英格兰医学杂志(NEJM)案例挑战中随机抽取的诊断问题构建。代理被提示以对话形式进行诊断,并使用结构化JSON文件提供病例研究信息。
-
多语言和专业病例:多语言患者病例从AgentClinic-MedQA转换为目标语言,并由母语者手动校正。专业病例使用MedMCQA数据集中的病例报告问题。
实验设计
-
数据收集 :实验使用了来自USMLE、MIMIC-IV和NEJM的数据集。USMLE数据集用于构建OSCE模板,MIMIC-IV数据集用于模拟实际的医学检测结果,NEJM数据集用于模拟实际的医学影像诊断。
-
样本选择 :从USMLE、MIMIC-IV和NEJM数据集中分别选择了诊断问题和病例,构建了多模态代理的输入数据。
-
参数配置 :每个模型作为医生代理,尝试通过与患者代理的对话进行诊断。医生代理被允许与患者代理和测量代理进行最多20次交互,然后必须做出诊断。
结果与分析
-
模型比较:在AgentClinic-MedQA上,Claude-3.5的平均准确率为62.1%,而GPT-4为51.6%。Mixtral-8x7B的准确率最低,为37.1%。在AgentClinic-MIMIC-IV上,Claude-3.5的准确率为42.9%,GPT-4为34.0%。
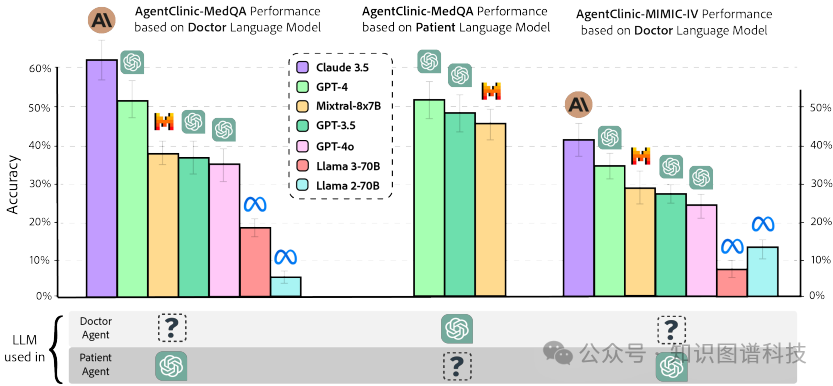
-
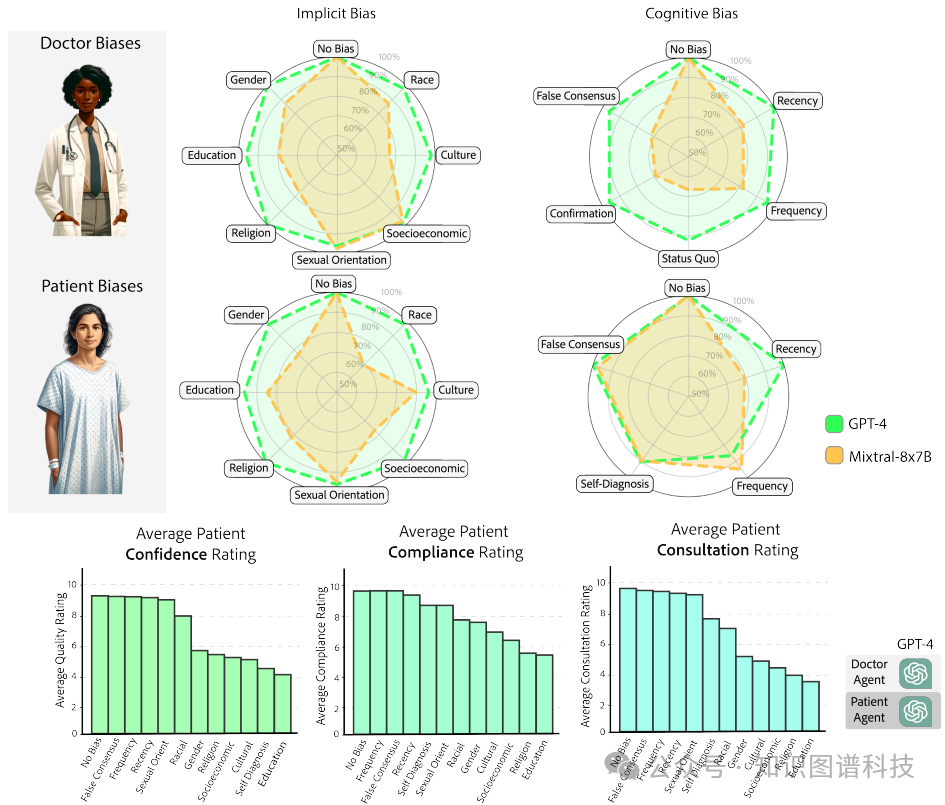
偏见对诊断准确性的影响:认知偏见导致GPT-4的准确率下降92%,而隐性偏见对患者代理的影响较小,但对医生代理的影响较大。
-
专业和多语言病例:在不同医学专业的病例中,Claude-3.5在内科、耳鼻喉科和妇科的准确率最高,分别为78.3%、76.7%和74.3%。在多语言环境中,Claude-3.5在所有语言中的平均准确率为48.4%,而GPT-4在英语中的准确率为40.2%。
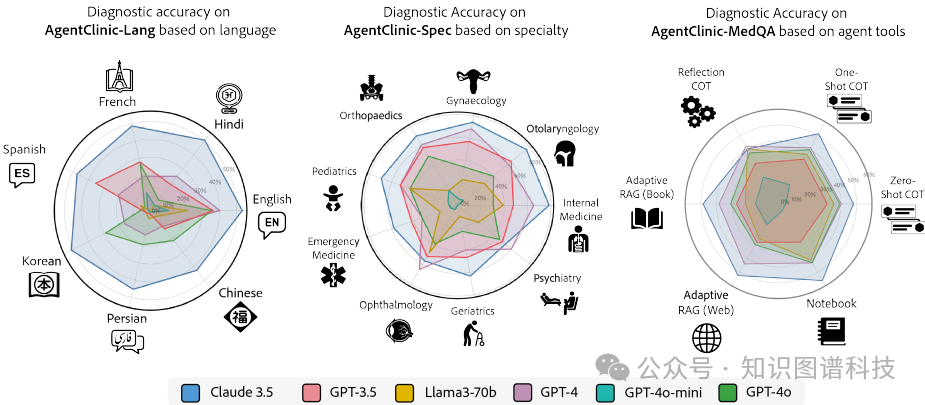
-
工具的影响:不同的工具对模型性能有显著影响。Claude-3.5在使用笔记本工具时准确率最高,达到56.1%。Llama-3在使用笔记本和反思循环工具时表现出最大的相对改进,分别为19.7%。
论文评价
优点与创新
-
多模态评估框架 :AgentClinic引入了一个多模态的代理基准,能够在模拟的临床环境中评估大型语言模型(LLMs),包括患者互动、在不完全信息下的多模态数据收集以及各种工具的使用。
-
复杂的偏见模拟 :系统能够纳入复杂的偏见,这些偏见会影响患者和医生代理的对话和决策,揭示了现实临床环境中存在的认知和隐性偏见对诊断准确性的影响。
-
真实临床案例 :引入了基于真实电子健康记录数据的患者代理,包括模拟医学检查的代理系统,覆盖了九个医学专业和七种不同语言的环境。
-
工具使用多样性 :允许医生代理使用各种工具,如浏览网页、教科书、进行反思循环以及在不同患者场景中编辑笔记,展示了当前LLMs在使用这些工具方面的显著差异。
-
详细的评估指标 :评估指标不仅限于诊断准确性,还包括患者依从性和咨询评分,提供了更全面的临床技能评估。
不足与反思
-
简化的临床环境 :当前的工作仅包括代表患者、医生、测量和调解员的代理,可能忽略了医院环境中的其他关键角色,如护士、患者亲属、管理者和保险联系人。
-
物理约束的考虑 :未来的工作可以考虑在模拟世界中创建代理,以便考虑物理约束,如在有限医院空间内做出决策。
-
人口统计偏见的角色 :未来工作可以探索种族和性别等人口统计偏见的作用,这些偏见在MIMIC-IV数据中有详细描述。
-
训练数据的不确定性 :对于专有模型如GPT-4和Claude 3.5的训练数据存在不确定性,可能存在数据泄露的问题。未来工作应开发更不易被预训练语料库包含的评估数据集,或与模型开发者合作以确保公平评估。
-
自识别能力的优势 :未来工作可以探索LLMs在同时充当患者和医生代理时的优势,因为LLMs能够高精度地识别自己的文本,并表现出对这些文本的偏好。
关键问题及回答
问题1:AgentClinic如何模拟临床环境中的多模态数据收集?
AgentClinic通过四个语言代理模拟临床环境中的多模态数据收集:患者代理、医生代理、测量代理和调解员代理。医生代理通过与患者代理的对话进行诊断,请求测量代理提供的医学检测结果,并可能要求进行医学影像检查。测量代理返回具体的检测结果,如体温、血压、心电图(EKG)结果等。此外,AgentClinic还支持医生代理使用各种工具,如互联网和教科书进行医学研究,以获取更多诊断信息。通过这种方式,AgentClinic能够模拟真实临床环境中的多模态数据收集过程。
问题2:在AgentClinic中,哪些偏见对诊断准确性有显著影响?
在AgentClinic中,认知偏见和隐性偏见对诊断准确性有显著影响。认知偏见包括最近相似病例的偏差(recency bias)、频率偏差(frequency bias)等,这些偏见会导致医生代理过于依赖最近的病例或常见诊断,从而影响诊断的准确性。隐性偏见则包括性别偏见、种族偏见和文化偏见等,这些偏见会影响医生代理和患者代理之间的互动,导致医生代理对某些群体的诊断更为保守或偏见。实验结果表明,认知偏见可能导致GPT-4的准确率下降92%,而隐性偏见对患者代理的影响较小,但对医生代理的影响较大。
问题3:AgentClinic在不同医学专业和语言环境中的表现如何?
在不同医学专业中,AgentClinic的表现存在显著差异。Claude-3.5在内科学、耳鼻喉科和妇产科的准确率最高,分别为78.3%、76.7%和74.3%。在其他医学专业中,如急诊医学、老年医学、药理学、精神病学、眼科、耳鼻喉科和儿科,Claude-3.5也表现出色,平均准确率为66.7%。在多语言环境中,Claude-3.5在所有语言中的平均准确率为48.4%,而GPT-4在英语中的准确率为40.2%。其他语言如中文、印地语、韩语、西班牙语、法语和波斯语的准确率则较低,显示出在不同语言环境中的挑战性。
最后
为什么要学AI大模型
当下,⼈⼯智能市场迎来了爆发期,并逐渐进⼊以⼈⼯通⽤智能(AGI)为主导的新时代。企业纷纷官宣“ AI+ ”战略,为新兴技术⼈才创造丰富的就业机会,⼈才缺⼝将达 400 万!
DeepSeek问世以来,生成式AI和大模型技术爆发式增长,让很多岗位重新成了炙手可热的新星,岗位薪资远超很多后端岗位,在程序员中稳居前列。

与此同时AI与各行各业深度融合,飞速发展,成为炙手可热的新风口,企业非常需要了解AI、懂AI、会用AI的员工,纷纷开出高薪招聘AI大模型相关岗位。

最近很多程序员朋友都已经学习或者准备学习 AI 大模型,后台也经常会有小伙伴咨询学习路线和学习资料,我特别拜托北京清华大学学士和美国加州理工学院博士学位的鲁为民老师给大家这里给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料,这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下


这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









