









The Bigtable implementation has three major components:
a library that is linked into every client, one master server, and many tablet servers.
Tablet servers can be dynamically added (or removed) from a cluster to accomodate changes in workloads.
The master is responsible for assigning tablets to tablet servers, detecting the addition and expiration of tablet servers, balancing tablet-server load, and garbage collection of files in GFS.
In addition, it handles schema changes such as table and column family creations.
Each tablet server manages a set of tablets (typically we have somewhere between ten to a thousand tablets per tablet server).
The tablet server handles read and write requests to the tablets that it has loaded, and also splits tablets that have grown too large.
As with many single-master distributed storage systems , client data does not move through the master:
clients communicate directly with tablet servers for reads and writes.
Because Bigtable clients do not rely on the master for tablet location information, most clients never communicate with the master.
As a result, the master is lightly loaded in practice.
A Bigtable cluster stores a number of tables.
Each table consists of a set of tablets, and each tablet contains all data associated with a row range.
Initially, each table consists of just one tablet. As a table grows, it is automatically split into multiple tablets, each approximately 100-200 MB in size by default.
5实施
Bigtable实施有三个主要部分:
连接到每个客户端,一个主服务器和许多tablet服务器的库。
tablet服务器可以从集群中动态添加(或删除)以适应工作负载的变化。
主管负责将tablet分配给tablet服务器,检测tablet服务器的添加和到期,平衡服务器负载以及GFS中文件的垃圾收集。
此外,它处理模式更改,如表和列族创建。
每个tablet服务器管理一组tablet(通常我们每个tablet服务器的平均数为10到1000个)。
tablet服务器处理对已加载的tablet的读取和写入请求,并且还分割了增长太大的tablet。
与许多单主分布式存储系统一样,客户端数据不会通过主控:
客户端直接与tablet服务器通信进行读写。
由于Bigtable客户端不依赖主机的tablet位置信息,因此大多数客户端从不与主机通信。
结果,主人在实践中轻装。BigTable集群存储多个表。
每个表由一组tablet组成,每个tablet包含与行范围相关联的所有数据。
最初,每张桌子只有一个tablet。随着桌面的增长,它会自动分为多个tablet,默认大约为100-200 MB。
5.1 Tablet Location
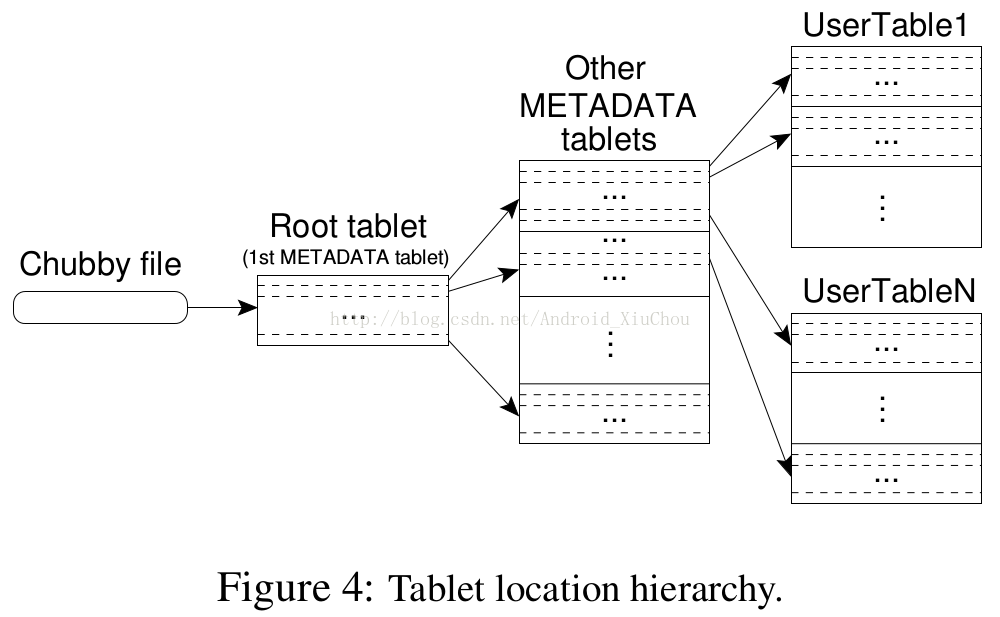
We use a three-level hierarchy analogous to that of a B + tree to store tablet location information (Figure 4).
Figure 4: Tablet location hierarchy.
The first level is a file stored in Chubby that contains the location of the root tablet.
The root tablet contains the location of all tablets in a special METADATA table.
Each METADATA tablet contains the location of a set of user tablets.
The root tablet is just the first tablet in the METADATA table, but is treated specially—it is never split—to ensure that the tablet location hierarchy has no more than three levels.
The METADATA table stores the location of a tablet under a row key that is an encoding of the tablet’s table identifier and its end row.
Each METADATA row stores approximately 1KB of data in memory.
With a modest limit of 128 MB METADATA tablets, our three-level location scheme is sufficient to address 2 34 tablets (or 2 61 bytes in 128 MB tablets).
The client library caches tablet locations.
If the client does not know the location of a tablet, or if it discovers that cached location information is incorrect, then it recursively moves up the tablet location hierarchy.
If the client’s cache is empty, the location algorithm requires three network round-trips, including one read from Chubby.
If the client’s cache is stale, the location algorithm could take up to six round-trips, because stale cache entries are only discovered upon misses (assuming that METADATA tablets do not move very frequently).
Although tablet locations are stored in memory, so no GFS accesses are required, we further reduce this cost in the common case by having the client library prefetch tablet locations:
it reads the metadata for more than one tablet whenever it reads the METADATA table.
We also store secondary information in the METADATA table, including a log of all events pertaining to each tablet (such as when a server begins serving it).
This information is helpful for debugging and performance analysis.
5.1 Tablet 位置
我们使用类似于B +树的三级层级来存储Tablet的位置信息(图4)。
图4:Tablet位置层级。
第一级是存储在Chubby中的文件,其中包含根Tablet的位置。
根Tablet包含特殊METADATA表中所有Tablet的位置。
每个METADATA Tablet都包含一组用户 Tablet 的位置。
根 Tablet 只是METADATA表格中的第一个 Tablet ,但经过特别处理,绝不会被拆分,以确保 Tablet 位置层级结构不超过三个等级。
METADATA表存储 Tablet 在行键下的位置,该键是 Tablet 表标识符及其结束行的编码。
每个METADATA行将大约1KB的数据存储在内存中。
限制128 MB的METADATA Tablet ,我们的三级位置方案足以解决2 34个 Tablet (或128 MB Tablet 中的2 61个字节)。
客户端库缓存 Tablet 位置。
如果客户端不知道 Tablet 的位置,或者如果它发现缓存的位置信息不正确,则它递归地向上移动 Tablet 位置层次结构。
如果客户端的缓存为空,则位置算法需要三次网络往返,包括从Chubby读取的一次。
如果客户端的缓存过期,则位置算法最多可能需要六次往返,因为只有在错过时才会发现暂停缓存条目(假设METADATA平台不会非常频繁地移动)。
虽然 Tablet 位置存储在内存中,因此不需要GFS访问,我们通过让客户端库预取 Tablet 位置进一步降低常见情况下的成本:
它读取METADATA表时读取多于一个 Tablet 的元数据。
我们还在METADATA表中存储辅助信息,包括与每个 Tablet 相关的所有事件的日志(例如服务器开始服务时)。
此信息有助于调试和性能分析。
5.2 Tablet Assignment
Each tablet is assigned to one tablet server at a time.
The master keeps track of the set of live tablet servers, and the current assignment of tablets to tablet servers, including which tablets are unassigned.
When a tablet is unassigned, and a tablet server with sufficient room for the tablet is available, the master assigns the tablet by sending a tablet load request to the tablet server.
Bigtable uses Chubby to keep track of tablet servers.
When a tablet server starts, it creates, and acquires an exclusive lock on, a uniquely-named file in a specific Chubby directory.
The master monitors this directory (the servers directory) to discover tablet servers.
A tablet server stops serving its tablets if it loses its exclusive lock: e.g., due to a network partition that caused the server to lose its Chubby session.
(Chubby provides an efficient mechanism that allows a tablet server to check whether it still holds its lock without incurring network traffic.)
A tablet server will attempt to reacquire an exclusive lock on its file as long as the file still exists.
If the file no longer exists, then the tablet server will never be able to serve again, so it kills itself.
Whenever a tablet server terminates (e.g., because the cluster management system is removing the tablet server’s machine from the cluster), it attempts to release its lock so that the master will reassign its tablets more quickly.
5.2 Tablet 分配
每个 tablet 一次分配给一台 tablet 服务器。
主人跟踪一组现场 tablet 服务器,以及当前将 tablet 分配给 tablet 服务器,包括哪些 tablet 未分配。
取消分配 tablet 时, tablet 服务器有足够的 tablet 空间可用,主人通过向 tablet 服务器发送 tablet 加载请求来分配 tablet 。
Bigtable使用Chubby跟踪 Tablet 服务器。
当 Tablet 服务器启动时,它创建并获取特定Chubby目录中唯一命名的文件的独占锁定。
主控器监视此目录(服务器目录)以发现 Tablet 服务器。
Tablet 服务器如果丢失其排他锁,则停止服务其 Tablet :例如,由于导致服务器丢失其Chubby会话的网络分区。
(Chubby提供了一种有效的机制,允许 Tablet 服务器检查它是否仍然保持锁定,而不会招致网络流量。)
只要文件仍然存在, Tablet 服务器将尝试重新获取其文件上的排他锁。
如果文件不再存在,那么 Tablet 服务器将永远不能再次服务,所以它会自动杀死。
每当 Tablet 服务器终止(例如,因为集群管理系统从集群中移除 Tablet 服务器的计算机)时,它会尝试释放其锁定,以便主人能够更快地重新分配其 Tablet 。
The master is responsible for detecting when a tablet server is no longer serving its tablets, and for reassigning those tablets as soon as possible.
To detect when a tablet server is no longer serving its tablets, the master periodically asks each tablet server for the status of its lock.
If a tablet server reports that it has lost its lock, or if the master was unable to reach a server during its last several attempts, the master attempts to acquire an exclusive lock on the server’s file.
If the master is able to acquire the lock, then Chubby is live and the tablet server is either dead or having trouble reaching Chubby, so the master ensures that the tablet server can never serve again by deleting its server file.
Once a server’s file has been deleted, the master can move all the tablets that were previously assigned to that server into the set of unassigned tablets.
To ensure that a Bigtable cluster is not vulnerable to networking issues between the master and Chubby, the master kills itself if its Chubby session expires.
However, as described above, master failures do not change the assignment of tablets to tablet servers.
主管负责检测 Tablet 服务器何时不再服务其 Tablet ,并尽快重新分配这些 Tablet 。
要检测 Tablet 服务器何时不再投放 Tablet ,主人会定期询问每台 Tablet 服务器的锁定状态。
如果 Tablet 服务器报告其已失去锁定,或者主服务器在最近几次尝试期间无法访问服务器,则主机会尝试获取服务器文件上的排他锁。
如果主人能够获得锁定,那么Chubby是直播, Tablet 服务器已经死机或遇到麻烦,所以主人确保 Tablet 服务器永远不能通过删除其服务器文件再次服务。
一旦服务器的文件被删除,主人可以将先前分配给该服务器的所有 Tablet 移动到未分配的 Tablet 中。
为了确保BigTable集群不容易受到主机和Chubby之间的网络问题的影响,如果主机和Chubby会话过期,则主机会自动死机。
但是,如上所述,主故障不会将 Tablet 的分配更改为 Tablet 服务器。
When a master is started by the cluster management system, it needs to discover the current tablet assignments before it can change them.
The master executes the following steps at startup.
(1) The master grabs a unique master lock in Chubby, which prevents concurrent master instantiations.
(2) The master scans the servers directory in Chubby to find the live servers.
(3) The master communicates with every live tablet server to discover what tablets are already assigned to each server.
(4) The master scans the METADATA table to learn the set of tablets.
Whenever this scan encounters a tablet that is not already assigned, the master adds the tablet to the set of unassigned tablets, which makes the tablet eligible for tablet assignment.
One complication is that the scan of the METADATA table cannot happen until the METADATA tablets have been assigned.
Therefore, before starting this scan (step 4), the master adds the root tablet to the set of unassigned tablets if an assignment for the root tablet was not discovered during step 3.
当主机由集群管理系统启动时,它需要发现当前的 Tablet 分配,然后才能更改它们。
主机在启动时执行以下步骤。
(1)主机在Chubby中抓取一个唯一的主锁,可防止并发主实例。
(2)主服务器扫描Chubby中的服务器目录以查找实时服务器。
(3)主人与每个实时 Tablet 服务器进行通信,以发现已分配给每个服务器的 Tablet 。
(4)主人扫描METADATA表以了解 Tablet 。
无论何时此扫描遇到尚未分配的 Tablet ,主人都会将 Tablet 添加到未分配的 Tablet ,这样 Tablet 可以进行 Tablet 分配。
一个复杂的情况是,在分配METADATA Tablet 之前,不能发生METADATA表的扫描。
因此,在开始此扫描之前(步骤4),如果在步骤3中没有发现根 Tablet 的分配,则主机会将根 Tablet 添加到未分配的 Tablet 。
This addition ensures that the root tablet will be assigned.
Because the root tablet contains the names of all METADATA tablets, the master knows about all of them after it has scanned the root tablet.
The set of existing tablets only changes when a table is created or deleted, two existing tablets are merged to form one larger tablet, or an existing tablet is split into two smaller tablets.
The master is able to keep track of these changes because it initiates all but the last.
Tablet splits are treated specially since they are initiated by a tablet server.
The tablet server commits the split by recording information for the new tablet in the METADATA table.
When the split has committed, it notifies the master.
In case the split notification is lost (either because the tablet server or the master died), the master detects the new tablet when it asks a tablet server to load the tablet that has now split.
The tablet server will notify the master of the split, because the tablet entry it finds in the METADATA table will specify only a portion of the tablet that the master asked it to load.
此添加确保根 Tablet 将被分配。
因为根 Tablet 包含所有METADATA Tablet 的名称,所以主人在扫描根 Tablet 后就会知道所有的 Tablet 。
现有 Tablet 只能在创建或删除表格时更改,两个现有的 Tablet 合并形成一个较大的 Tablet ,或者现有的 Tablet 分为两个较小的 Tablet 。
主人能够跟踪这些变化,因为它启动了所有的,但最后一个。
Tablet 拆分由于由 Tablet 服务器发起,因此被特别处理。
Tablet 服务器通过在METADATA表中记录新 Tablet 的信息来提交拆分。
当分裂已经提交时,它通知主人。
如果拆分通知丢失(由于 Tablet 服务器或主机死机),则主机会在要求 Tablet 服务器加载现在已拆分的 Tablet 时检测新的 Tablet 。
Tablet 服务器将通知主机的拆分,因为它在METADATA表中找到的 Tablet 条目只会指定主机要求加载的 Tablet 的一部分。
5.3 Tablet Serving
The persistent state of a tablet is stored in GFS, as illustrated in Figure 5.
Updates are committed to a commit log that stores redo records. Of these updates, the recently committed ones are stored in memory in a sorted buffer called a memtable; the older updates are stored in a sequence of SSTables.
To recover a tablet, a tablet server reads its metadata from the METADATA table.
This metadata contains the list of SSTables that comprise a tablet and a set of a redo points, which are pointers into any commit logs that may contain data for the tablet.
The server reads the indices of the SSTables into memory and reconstructs the memtable by applying all of the updates that have committed since the redo points.
When a write operation arrives at a tablet server, the server checks that it is well-formed, and that the sender is authorized to perform the mutation.
Authorization is performed by reading the list of permitted writers from a Chubby file (which is almost always a hit in the Chubby client cache).
A valid mutation is written to the commit log.
Group commit is used to improve the throughput of lots of small mutations .
After the write has been committed, its contents are inserted into the memtable.
When a read operation arrives at a tablet server, it is similarly checked for well-formedness and proper authorization.
A valid read operation is executed on a merged view of the sequence of SSTables and the memtable.
Since the SSTables and the memtable are lexicograph-ically sorted data structures, the merged view can be formed efficiently.
Incoming read and write operations can continue while tablets are split and merged.
5.3 Tablet 服务
Tablet 的持续状态存储在GFS中,如图5所示。
更新致力于存储重做记录的提交日志。在这些更新中,最近提交的更新存储在名为memtable的排序缓冲区中的内存中;较旧的更新存储在一系列SSTables中。
要恢复 Tablet , Tablet 服务器从METADATA表中读取其元数据。
此元数据包含构成 Tablet 的SSTables和一组重做点的列表,这些重点指针指向可能包含 Tablet 数据的任何提交日志。
服务器将SSTables的索引读取到内存中,并通过应用重做点以来已经提交的所有更新重建memtable。
当写入操作到达 Tablet 服务器时,服务器检查它是否正确,并且发送者被授权执行突变。
通过从Chubby文件(几乎总是在Chubby客户端缓存中命中)读取允许的写入器列表来执行授权。
将一个有效的变量写入提交日志。
小组承诺用于提高大量小突变的吞吐量。
写入完成后,将其内容插入到memtable中。
当读取操作到达 Tablet 服务器时,类似地检查其形状和正确的授权。
在SSTables和memtable的顺序的合并视图上执行有效的读取操作。
由于SSTables和memtable是按字典排序的数据结构,因此可以有效地形成合并视图。
Tablet 被拆分并合并时,可以继续进行读写操作。

5.4 Compactions
As write operations execute, the size of the memtable increases.
When the memtable size reaches a threshold, the memtable is frozen, a new memtable is created, and the frozen memtable is converted to an SSTable and written to GFS.
This minor compaction process has two goals:
it shrinks the memory usage of the tablet server, and it reduces the amount of data that has to be read from the commit log during recovery if this server dies.
Incoming read and write operations can continue while compactions occur.
Every minor compaction creates a new SSTable.
5.4压实
当写入操作执行时,memtable的大小增加。
当memtable大小达到阈值时,memtable被冻结,创建一个新的memtable,并将冻结的memtable转换为SSTable并写入GFS。
这个轻微的压实过程有两个目标:
它会缩小 Tablet 服务器的内存使用情况,并减少在恢复期间必须从提交日志中读取的数据量(如果此服务器死机)。
进行读写操作可以在压缩发生时继续。
每个小的压缩都会创建一个新的SSTable。
If this behavior continued unchecked, read operations might need to merge updates from an arbitrary number of SSTables.
Instead, we bound the number of such files by periodically executing a merging compaction in the background.
A merging compaction reads the contents of a few SSTables and the memtable, and writes out a new SSTable.
The input SSTables and memtable can be discarded as soon as the compaction has finished.
A merging compaction that rewrites all SSTables into exactly one SSTable is called a major compaction.
SSTables produced by non-major compactions can contain special deletion entries that suppress deleted data in older SSTables that are still live.
A major compaction,on the other hand, produces an SSTable that contains no deletion information or deleted data.
Bigtable cycles through all of its tablets and regularly applies major compactions to them.
These major compactions allow Bigtable to reclaim resources used by deleted data, and also allow it to ensure that deleted data disappears from the system in a timely fashion, which is important for services that store sensitive data.
如果此行为继续未经检查,读取操作可能需要合并来自任意数量的SSTables的更新。
相反,我们通过在后台定期执行合并压缩来限制这些文件的数量。
合并压缩读取几个SSTables和memtable的内容,并写出一个新的SSTable。
一旦压实完成,输入SSTables和memtable就可以被丢弃。
将所有SSTables重写为一个SSTable的合并压缩称为主压缩。
由非主要压缩生成的SSTables可以包含特殊的删除条目,可以抑制仍旧存在的旧SST中的已删除数据。
另一方面,主要压缩生成不包含删除信息或删除数据的SSTable。
Bigtable循环遍及其所有 Tablet ,并定期对其进行主要的压缩。
这些主要的压缩使BigTable可以回收被删除的数据所使用的资源,并且还允许它确保已删除的数据及时从系统中消失,这对于存储敏感数据的服务很重要。















 491
491

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









