







 本文介绍了CART算法,与ID3和C4.5的不同在于它构建二叉树并使用Gini指数作为划分标准。内容涵盖CART算法原理、Gini增益计算、剪枝方法(如代价复杂度剪枝),并分享了在编程实现过程中遇到的问题与改进思路。
本文介绍了CART算法,与ID3和C4.5的不同在于它构建二叉树并使用Gini指数作为划分标准。内容涵盖CART算法原理、Gini增益计算、剪枝方法(如代价复杂度剪枝),并分享了在编程实现过程中遇到的问题与改进思路。
CART分类回归树算法
与上次文章中提到的ID3算法和C4.5算法类似,CART算法也是一种决策树分类算法。CART分类回归树算法的本质也是对数据进行分类的,最终数据的表现形式也是以树形的模式展现的,与ID3,C4.5算法不同的是,他的分类标准所采用的算法不同了。下面列出了其中的一些不同之处:
1、CART最后形成的树是一个二叉树,每个节点会分成2个节点,左孩子节点和右孩子节点,而在ID3和C4.5中是按照分类属性的值类型进行划分,于是这就要求CART算法在所选定的属性中又要划分出最佳的属性划分值,节点如果选定了划分属性名称还要确定里面按照那个值做一个二元的划分。
2、CART算法对于属性的值采用的是基于Gini系数值的方式做比较,gini某个属性的某次值的划分的gini指数的值为:

比如体温为恒温时包含哺乳类5个、鸟类2个,则:
体温为非恒温时包含爬行类3个、鱼类3个、两栖类2个,则
所以如果按照“体温为恒温和非恒温”进行划分的话,我们得到GINI的增益(类比信息增益):
最好的划分就是使得GINI_Gain最小的划分。
通过比较每个属性的最小的gini指数值,作为最后的结果。3、CART算法在把数据进行分类之后,会对树进行一个剪枝,常用的用前剪枝和后剪枝法,而常见的后剪枝发包括代价复杂度剪枝,悲观误差剪枝等等,我写的此次算法采用的是代价复杂度剪枝法。代价复杂度剪枝的算法公式为:
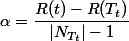
里面变量的意思为:
是子树中包含的叶子节点个数;
是节点t的误差代价,如果该节点被剪枝;
r(t)是节点t的误差率;
p(t)是节点t上的数据占所有数据的比例。
是子树Tt的误差代价,如果该节点不被剪枝。它等于子树Tt上所有叶子节点的误差代价之和。下面说说我对于这个公式的理解:其实这个公式的本质是对于剪枝前和剪枝后的样本偏差率做一个差值比较,一个好的分类当然是分类后的样本偏差率相较于没分类(就是剪枝掉的时候)的偏差率小,所以这时的值就会大,如果分类前后基本变化不大,则意味着分类不起什么效果,α值的分子位置就小,所以误差代价就小,可以被剪枝。但是一般分类后的偏差率会小于分类前的,因为偏差数在高层节点的时候肯定比子节点的多,子节点偏差数最多与父亲节点一样。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3734
3734

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









