







 本文介绍了如何通过源码改造在YARN中添加Task级别的GC监控指标,如gc总次数、young gc和full gc次数。通过分析现有Counter结构,了解如何在Task类中更新Counter,并提供了改造代码示例。
本文介绍了如何通过源码改造在YARN中添加Task级别的GC监控指标,如gc总次数、young gc和full gc次数。通过分析现有Counter结构,了解如何在Task类中更新Counter,并提供了改造代码示例。
前言
上篇文章讲述了如何从HDFS上拿到JobHistory的Job信息数据,当然如果能对这些数据进行二次分析的话,将会得到更加精准的分析结果.但是尽管说数据是有了,但毕竟是Hadoop系统内部记录的数据,如果我想知道更加细粒度的数据,比如说,我想知道1个Task的在从运行开始到结束的过程中的gc情况,包括gc总次数,young gc,full gc次数,尤其是full gc的次数,会直观的反映task的内存使用情况,显然这么细粒度的监控指标在JobHistory上是不会存在的.因此这点可以作为我们的一个优化目标,下面的正文部分教你如何添加新的自定义Counter.
原有的Task Counter
要添加新的Counter指标之前,先看看现有的JobHistory上的对于task级别的监控指标有哪些,如下图:
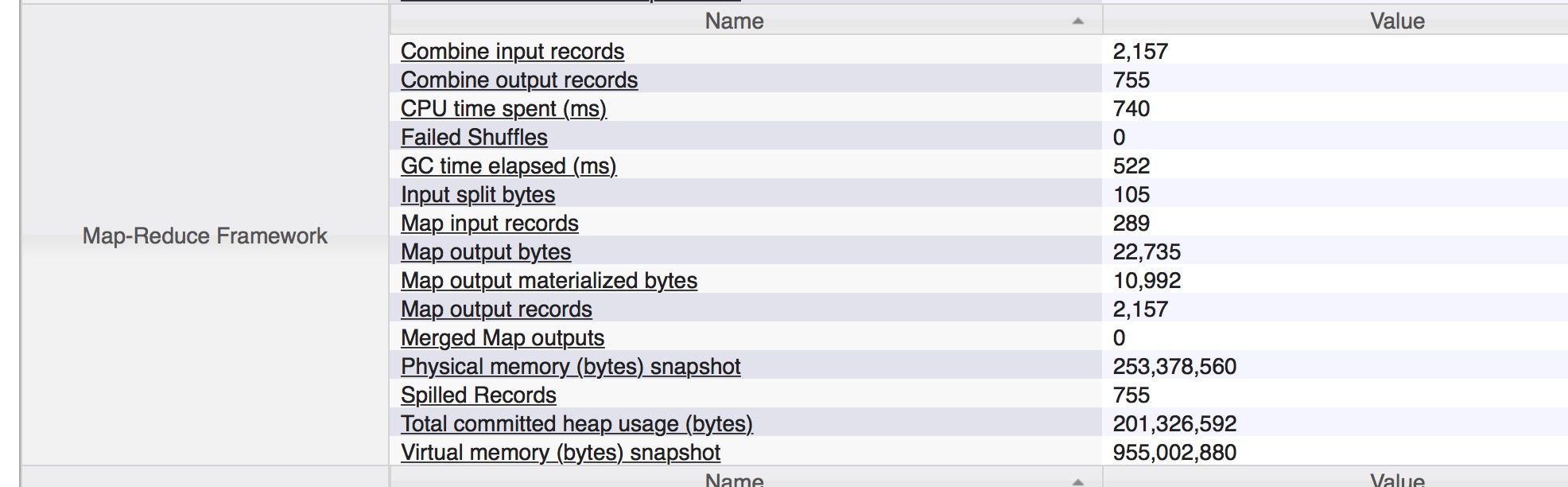
这1栏的指标是map,reduce共用1个的,因为这里所选的是一个map task,所以看到的都是map相关的指标.可以看到与gc相关的指标只有1个gc time elapsed,就是gc消耗的总时间,这个时间的计算是累加各次的gc操作所花的总时间和.我们的最终目标就是在上面能够展现除更多的gc相关的指标.
Counter结构
要想添加新的自定标Counter,需要了解一下在Yarn中Counter是如何构建的,也要了解一下他的结构原理,Counter的结构其实也没有那么简单,我这里就给大家介绍个大概,首先counter有Counter组的概念,比如在下面的页面中有3个组.
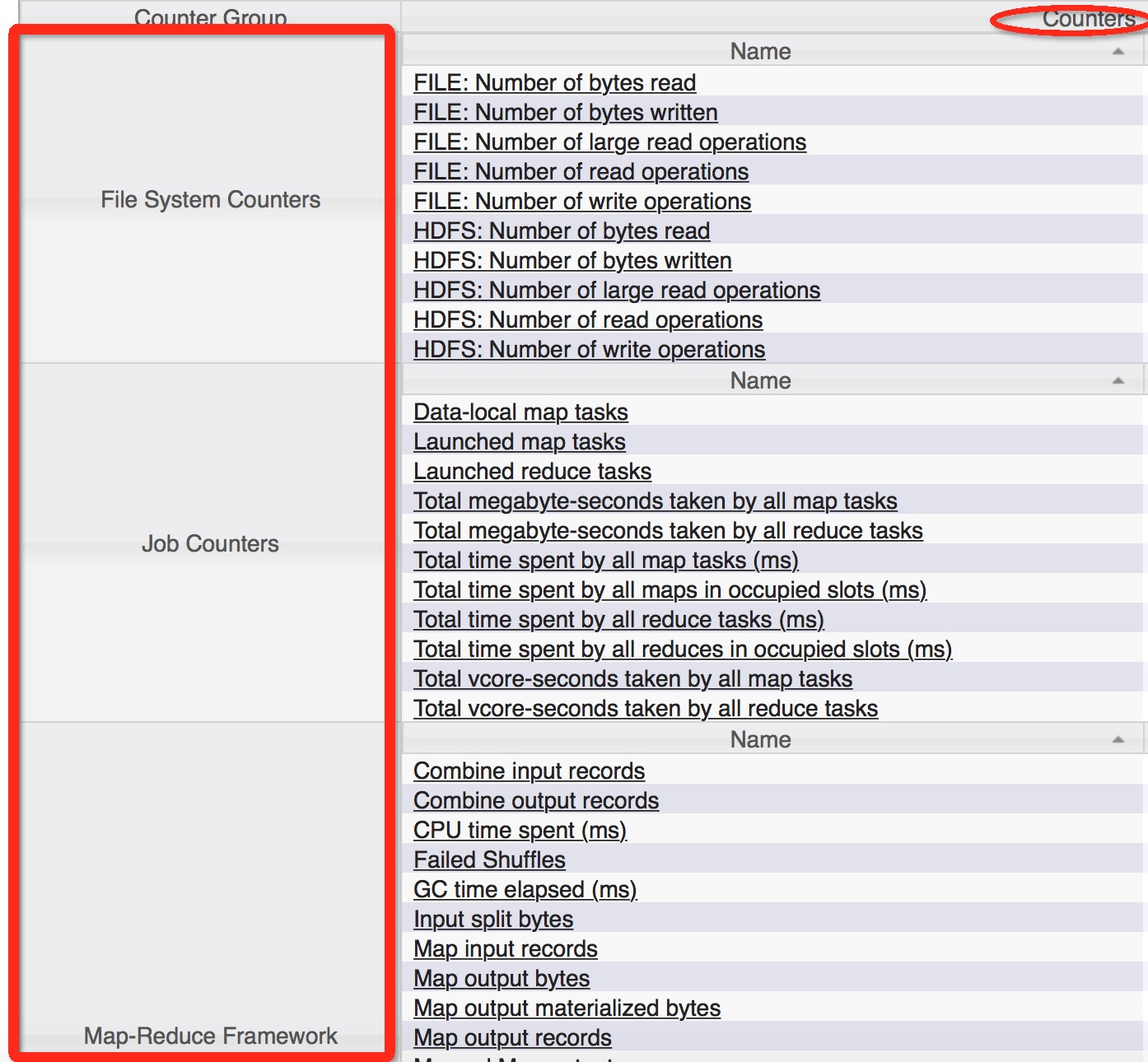
在这个页面中,展现了3个CounterGroup组的数据,在每个组内包草了许多个Counter的统计数据,用结构图展现的方式就是下面这样:
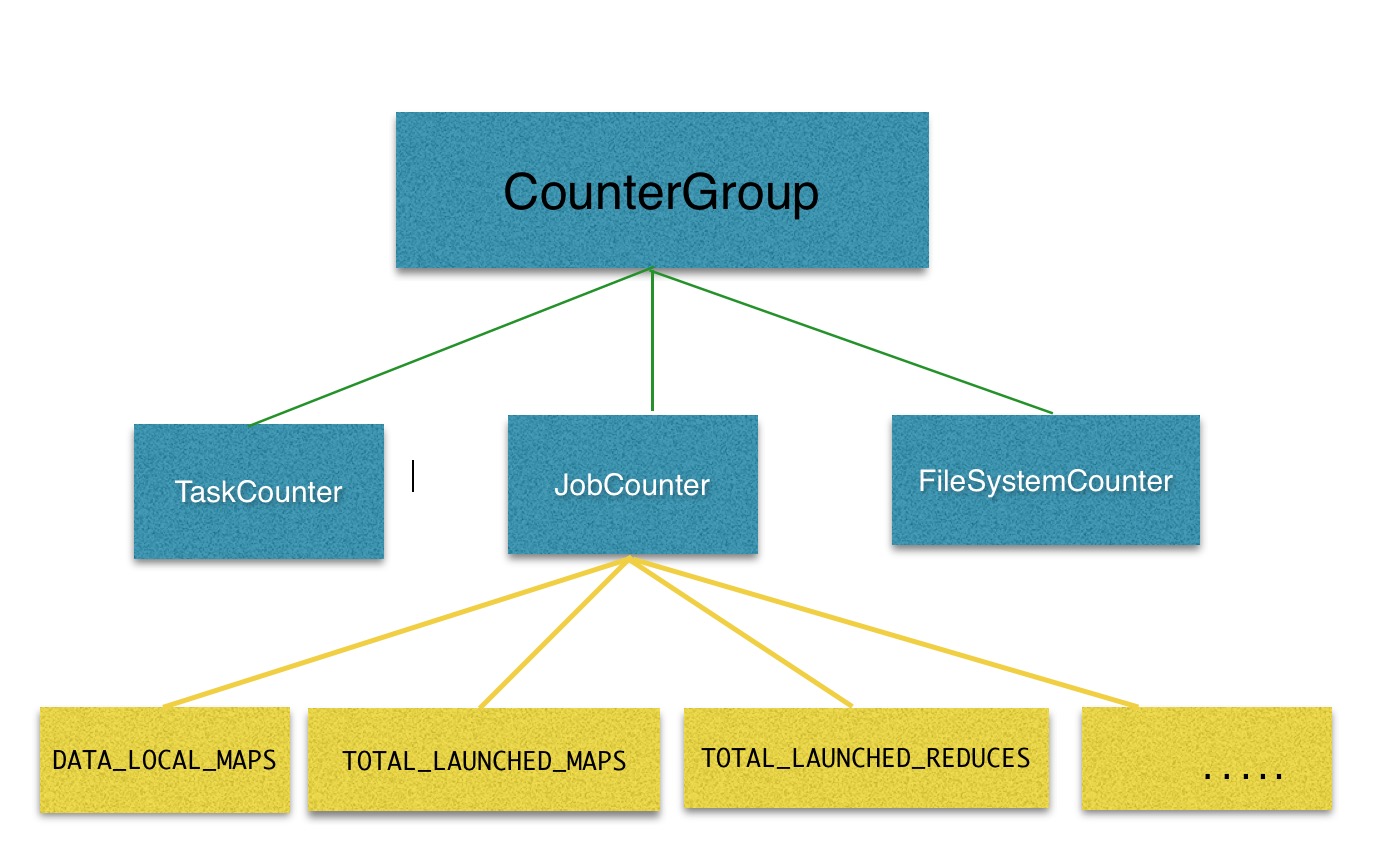
我们要加的Gc相关的Counter是属于另外1个名叫Map-Reduce FrameWork组的.
源码改造GC Counter指标
添加Gc相关的指标还是相对比较容易的,因为原本已经存在相关相似的指标存在了,我们只需要在同样的地方多加几行统计代码就OK 了.首先这个Counter是task相关的,所以定位到Task类对象中.会发现有个叫updateCounters的方法:
private synchronized void updateCounters() {
Map<String, List<FileSystem.Statistics>> map = new HashMap<String, List<FileSystem.Statistics>>();
for (Statistics stat : FileSystem.getAllStatistics()) {
String uriScheme = stat.getScheme();
if (map.containsKey(uriScheme)) {
List<F 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5300
5300

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









