







 本文探讨YARN的JobHistory服务,用于监控和分析集群中的作业历史数据。通过JobHistory,可以获取详细的task运行信息,包括map和reduce任务的数量、开始结束时间等。虽然JobHistory的展示有限,但可以通过解析源码,提取数据存入数据库,进行自定义分析。文章介绍了JobHistory数据的存储位置,并展示了如何从存储文件中获取并转化为对象,以便进一步分析。
本文探讨YARN的JobHistory服务,用于监控和分析集群中的作业历史数据。通过JobHistory,可以获取详细的task运行信息,包括map和reduce任务的数量、开始结束时间等。虽然JobHistory的展示有限,但可以通过解析源码,提取数据存入数据库,进行自定义分析。文章介绍了JobHistory数据的存储位置,并展示了如何从存储文件中获取并转化为对象,以便进一步分析。
前言
继续延续上一篇文章的主题,2个字,监控,分布式系统要想做到足够大,足够强,足够稳定,首先需要做好的就是其中的监控.现在开源的分布式系统很多,YARN就是其中一种,比较值得庆幸的一点是,Yarn已经在Ganglia做了很多指标的监控分析.比如namenode rpc请求数,datanode写入字节数,读字节数,jvm相关的gc次数等等.但是看似这些指标非常的完美,其实不然,为什么这么说呢,因为粒度太粗,比如说下面这个场景,我想分析集群中特点节点机器上哪个task异常,导致拖垮整个集群的运作效率.这个时候,显然分析Ganglia上的粗粒度监控指标就不能解决这样的场景问题了吧.不过还好,Yarn提供了这样的额外服务,叫做JobHistory,他也是一项独立的服务.
什么是JobHistory
什么是JobHistory,jobHistory翻译成中文就是作业历史,就是作业历史记录.就是保存了集群运行过的历史Job信息数据.下面是一张此服务的Web UI视图:
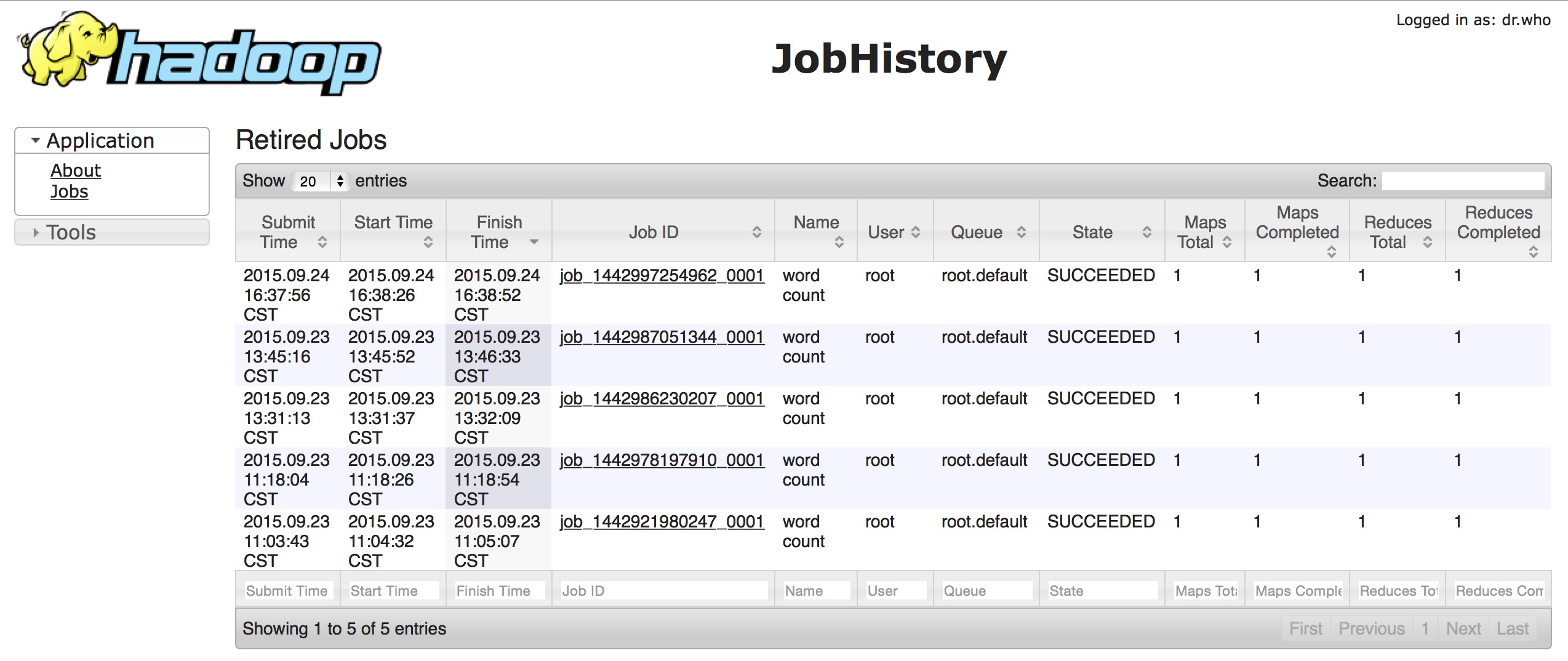
可以很清楚的看到了上面执行过的job记录.因为是我测试是跑的几个word-count程序,所以信息比较少.当然每个job记录的链接还能往里继续点,里面保存了更加详细的task的运行信息,包括map数,reduce数,开始结束时间等等,如下图
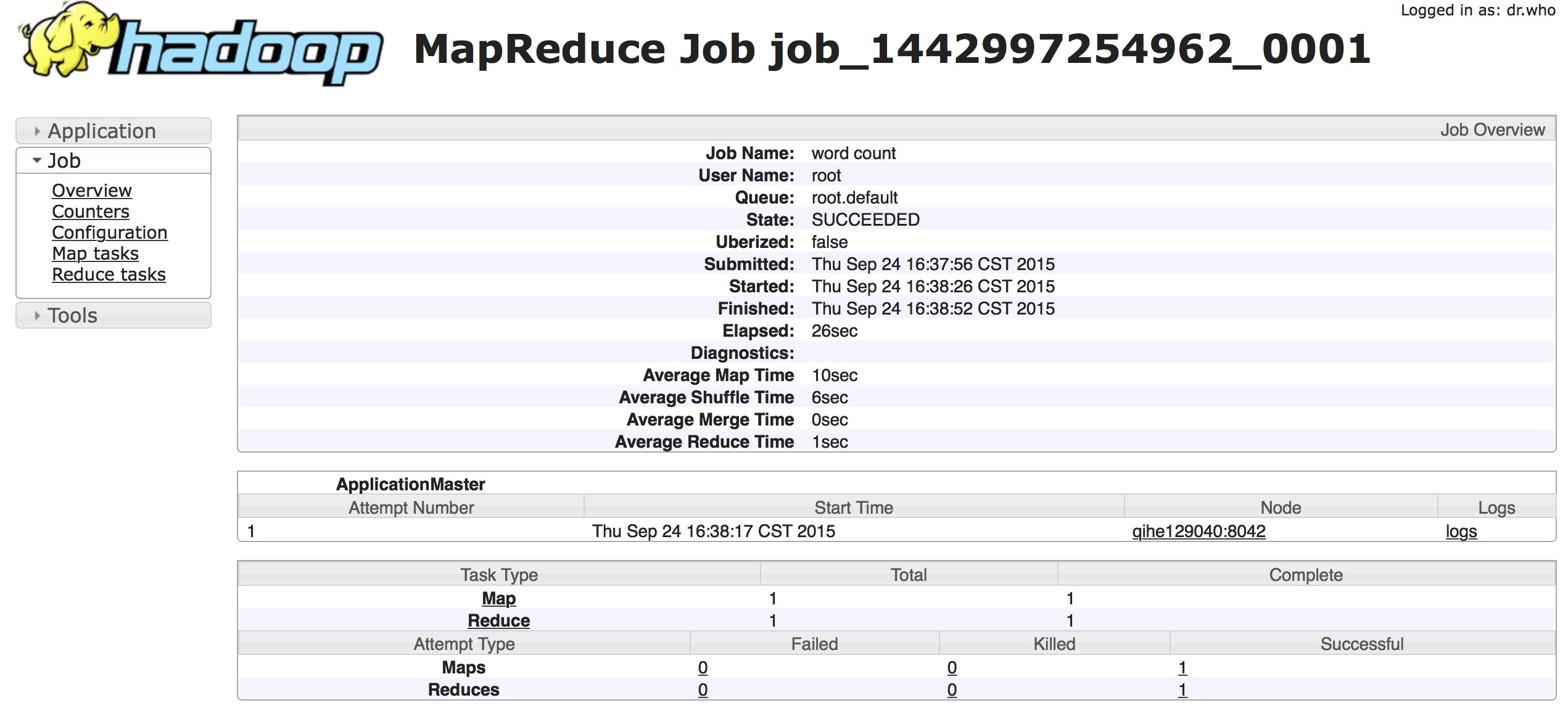
JobHistory上所展示的数据是非常多的,但是唯一感到不足的是,JobHistory的展示效果太过单一,每个Job的数据结果都是独立展现的,并没有一个汇总的页面,不便于比较分析.所以一个比较大胆的想法就诞生了,我们是不是可以拿到Job的信息记录,存入自己的db,然后自己做分析呢.OK,想法固然不错,但是还是得从源码中进行分析,首先要明白这些数据到底存在哪.
JobHistory作业数据存储
下面来描述一下我是如何分析发现JobHistory作业数据的存储源的.首先定位到JobHistory这个大类.
/**
* Loads and manages the Job history cache.
*/
public class JobHistory extends AbstractService implements HistoryContext {
private static final Log LOG = LogFactory.getLog(JobHistory.class);
public static final Pattern CONF_FILENAME_REGEX = Pattern.compile("("
+ JobID.JOBID_REGEX + ")_conf.xml(?:\\.[0-9]+\\.old)?");
public static final String OLD_SUFFIX = ".old";
// Time interval for the move thread.
private long moveThreadInterval;
private Configuration conf;
private ScheduledThreadPoolExecutor scheduledExecutor = null;
//注意下面这2个类的名称,显然与存储信息相关
private HistoryStorage storage = null;
private HistoryFileManager hsManager = null;
ScheduledFuture<?> futureHistoryCleaner = null;
...从这里就可以看出来,JobHistory也是一项服务.关注到上面的倒数3行有与存储相关的类,我们可以重点关注这2个变量.然后扫描JobHistory的内部方法,你应该会发现有下面这样的方法
@Override
public Map<JobId, Job> getAllJobs() {
return storage.getAllPartialJobs();
}@Override
protected void serviceInit(Configuration conf) throws Exception {
LOG.info("JobHistory Init");
.....
hsManager = createHistoryFileManager();
hsManager.init(conf);
try {
hsManager.initExisting();
} catch (IOException e) {
throw new YarnRuntimeException("Failed to intialize existing directories", e);
}
storage = createHistoryStorage();
if (storage instanceof Service) {
((Service) storage).init(conf);
}
storage.setHistoryFileManager(hsManager);
super.serviceInit(conf);
}protected HistoryStorage createHistoryStorage() {
return ReflectionUtils.newInstance(conf.getClass(
JHAdminConfig.MR_HISTORY_STORAGE, CachedHistoryStorage.class,
HistoryStorage.class), conf);
}@Override
public Map<JobId, Job> getAllP 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 303
303

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









