









1、前言
自动机器学习(AutoML) 旨在通过让一些通用步骤 (如数据预处理、模型选择和调整超参数) 自动化,来简化机器学习中生成模型的过程。AutoML是指尽量不通过人来设定超参数,而是使用某种学习机制,来调节这些超参数。这些学习机制包括传统的贝叶斯优化,多臂老虎机(multi-armed bandit),进化算法,还有比较新的强化学习。当我们提起AutoML时,我们更多地是说自动化数据准备(即数据的预处理,数据的生成和选择)和模型训练(模型选择和超参数调优)。这个过程的每一步都有非常多的选项(options),根据我们遇到的问题,需要设定各种不同的选项。
Auto-Sklearn 是一个基于 Python 的开源工具包,用于执行 AutoML,它采用著名的 Scikit-Learn 机器学习包进行数据处理和机器学习算法。
在正式介绍Auto-Sklearn前我们先要声明几个问题:
1、Auto-Sklearn不能再Windows上使用,不要试图挣扎了
2、不能使用非数值型数据,也就是还需要特征工程进行处理才行
3、不支持深度学习,后面我们会介绍Auto-PyTorch
4、运行时间比较长,时间设置短的话训练不充分
2、介绍
Auto-Sklearn 是改进了一般的 AutoML 方法,自动机器学习框架采用贝叶斯超参数优化方法,有效地发现给定数据集的性能最佳的模型管道。
这里另外添加了两个组件:
- 一个用于初始化贝叶斯优化器的元学习(meta-learning)方法
- 优化过程中的自动集成(automated ensemble)方法
这种元学习方法是贝叶斯优化的补充,用于优化 ML 框架。对于像整个 ML 框架一样大的超参数空间,贝叶斯优化的启动速度很慢。通过基于元学习选择若干个配置来用于种子贝叶斯优化。这种通过元学习的方法可以称为热启动优化方法。再配合多个模型的自动集成方法,使得整个机器学习流程高度自动化,将大大节省用户的时间。从这个流程来看,让机器学习使用者可以有更多的时间来选择数据以及思考要处理的问题本身。
2.1 贝叶斯优化
贝叶斯优化的原理是利用现有的样本在优化目标函数中的表现,构建一个后验模型。该后验模型上的每一个点都是一个高斯分布,即有均值和方差。若该点是已有样本点,则均值就是该点的优化目标函数取值,方差为0。而其他未知样本点的均值和方差是后验概率拟合的,不一定接近真实值。那么就用一个采集函数,不断试探这些未知样本点对应的优化目标函数值,不断更新后验概率的模型。由于采集函数可以兼顾Explore/Exploit,所以会更多地选择表现好的点和潜力大的点。因此,在资源预算耗尽时,往往能够得到不错的优化结果。即找到局部最优的优化目标函数中的参数。
auto-sklearn用的是smac(https://github.com/automl/SMAC3)算法,是贝叶斯优化算法的一种。算法在刚初始化时,的确类似随机搜索,但是随着搜索的进行,算法知道的信息越来越多,就能预知下一次搜索哪个点模型的表现会最好。
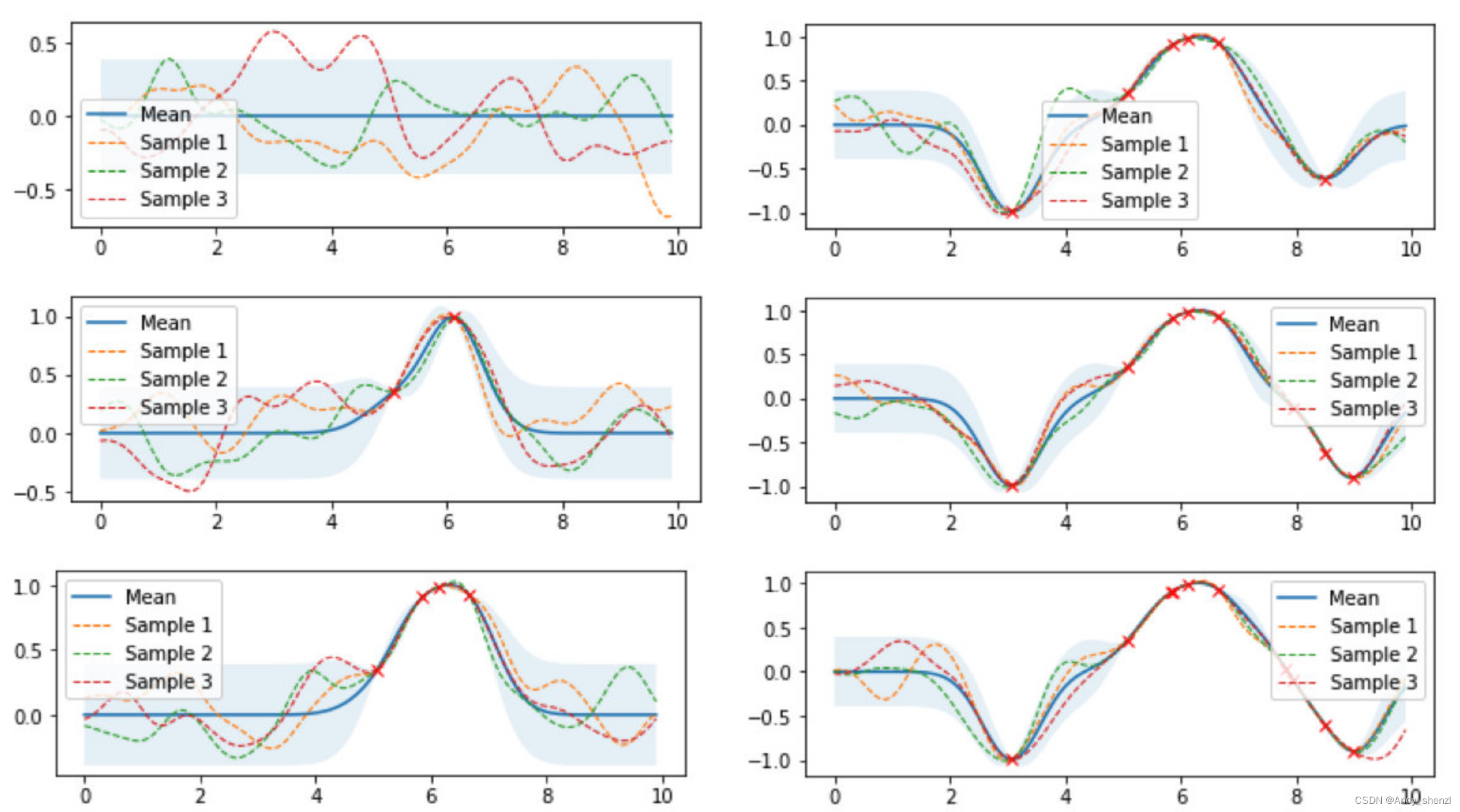
图中浅蓝色的表示95%置信区间的上下界,越宽表示对某个点预测的标准差越大,表示对这个点越不确定。随着搜索过的点越来越多,历史点(红叉)附近的标准差就会降低,表示对附近的点越确定。就这样会拟合出一个参数空间映射到模型表现的函数,从这个空间中找一个点,作为下次的搜索点。
2.2 从时间维度看
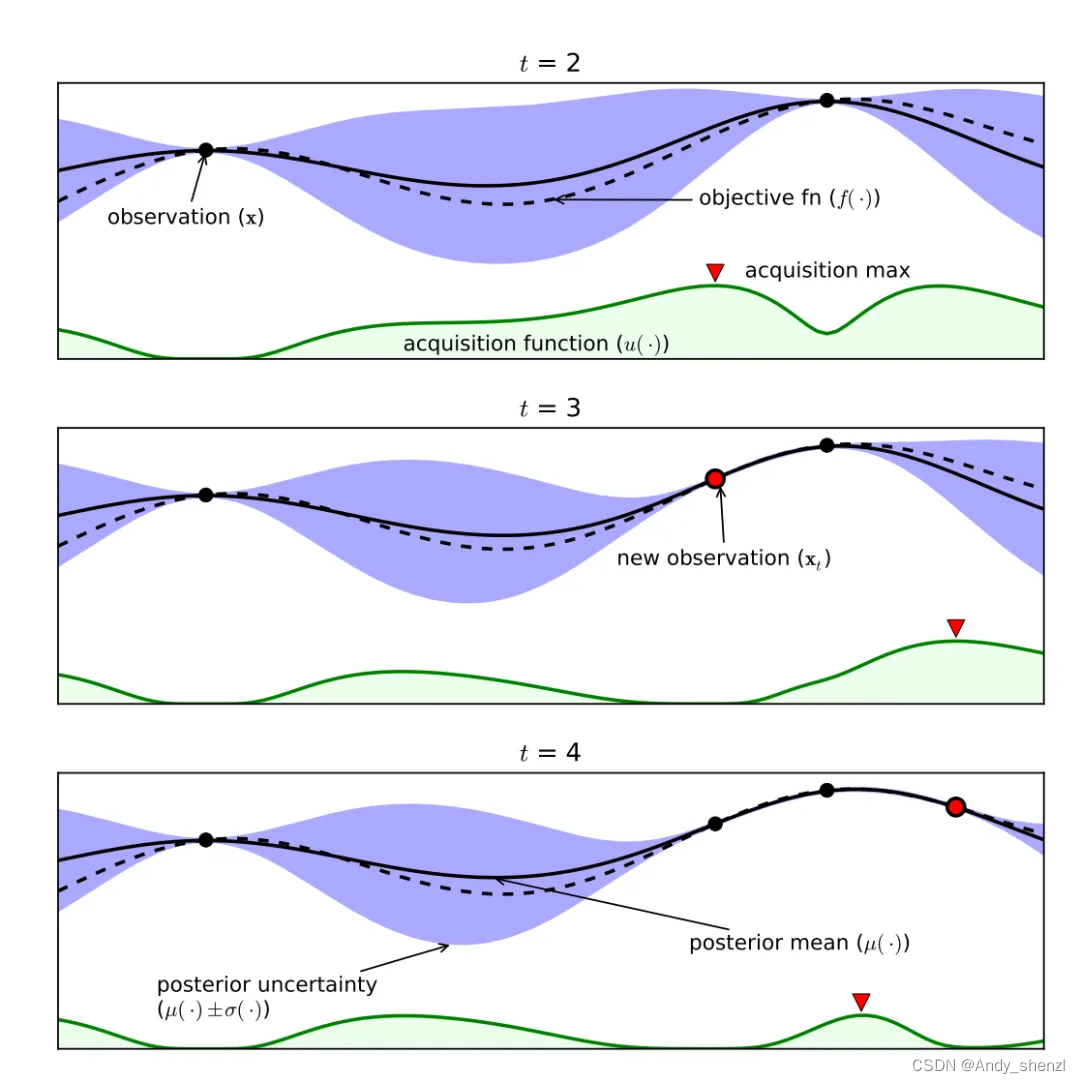
上图是在一个简单的 1D 问题上应用贝叶斯优化的实验图,这些图显示了在经过四次迭代后,高斯过程对目标函数的近似。我们以 t=3 为例分别介绍一下图中各个部分的作用。
上图 2 个 evaluations 黑点和一个红色 evaluations,是三次评估后显示替代模型的初始值估计,会影响下一个点的选择,穿过这三个点的曲线可以画出非常多条。黑色虚线曲线是实际真正的目标函数 (通常未知)。黑色实线曲线是代理模型的目标函数的均值。紫色区域是代理模型的目标函数的方差。绿色阴影部分指的是acquisition function的值,选取最大值的点作为下一个采样点。只有三个点,拟合的效果稍差,黑点越多,黑色实线和黑色虚线之间的区域就越小,误差越小,代理模型越接近真实模型的目标函数。
3、实战
3.1 分类
这里我们使用Titanic数据集来演示,因为这个数据集大家比较熟悉,所以看起来会更加简单点
3.1.1数据导入
说明:可以自动识别NAN值,这个是Auto-Sklearn比较人性化的一点;大部分sklearn原生模型都不能自动处理Nan值。
import pandas as pd
data = pd.read_csv("/datasource/DL数据集demo/titanic.csv")
# 这里对性别用One-Hot编码,其实流程跟单个算法一样
one_hot=OneHotEncoder()
data_temp = pd.DataFrame(one_hot.fit_transform(data[['Sex']]).toarray(),columns=one_hot.get_feature_names(['Sex']),dtype='int32')
data_onehot=pd.concat((data,data_temp),axis=1) #也可以用merge,join
data_onehot.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare Cabin | Embarked | Sex_female | Sex_male |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th… | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
3.1.2 数据定义
X ,y = (data_onehot[["Pclass","Age","Fare", "Sex_female","Sex_male"]],data_onehot["Survived"])
X_train, X_test, y_train, y_test = sklearn.model_selection.train_test_split(X, y)
3.1.3 模型定义
AutoSklearn 类提供了大量的配置选项作为参数。
大部分参数可以默认,这里只介绍两个参数
time_left_for_this_task:任务的最长时间,以秒为单位;默认是一个小时,所以自己用来演示的话可以设置5-10分钟;
per_run_time_limit :分配给每个模型评估的时间,以秒为单位,需要依照time_left_for_this_task来进行制定,如果大于或者等于time_left_for_this_task,模型一般会提示并自动赋值。
memory_limit=None:如果内存报错的话,建议这样设置;
n_jobs=-1:这个也会报错,具体错误忘记记下来了,建议设置成-1
另外还有其他参数,如ensemble_size、initial_configurations_via_metalearning,可用于微调分类器
如果有需要可以自行配置其他参数
但是既然我们要学习自动机器学习,不建议考虑太多参数。
automl = autosklearn.classification.AutoSklearnClassifier(
time_left_for_this_task=3*60,
per_run_time_limit=2*60,
n_jobs=-1,
memory_limit=None
)
3.1.4 训练预测
预测时间要比一般的sklearn模型要长,一般的模型,比如GBDT,设置1000棵树,基本也在秒级完成,但是这个需要根据设置的时间来运行。
优点就是不需要自己进行网格调参,所以整体看下来,autosklearn是比较节省时间的。
automl.fit(X_train, y_train)
print(automl.score(X_train, y_train))
# 0.9251497005988024
y_AUTO= automl.predict(X_test)
虽然autosklearn有score查看准确率,但是最好跟其他的算法统一,用sklearn的数据进行评估
from sklearn.metrics import accuracy_score
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.metrics import roc_auc_score
from sklearn.metrics import precision_score
from sklearn.metrics import f1_score
from sklearn.metrics import recall_score
acc = accuracy_score(y_test,y_AUTO)#"accuracy"(准确率)
auc = roc_auc_score(y_test, y_AUTO)#从预测分数中,计算ROC曲线的面积(ROC AUC)
precision = precision_score(y_test,y_AUTO)#精确率
recall = recall_score(y_test,y_AUTO)#计算召回率
f1 = f1_score(y_test,y_AUTO)#计算F1评分,也被称为balanced F-score或者F-measure
print(acc,auc,precision,recall,f1)
#0.7937219730941704 0.7673930921052632 0.8888888888888888 0.5894736842105263 0.7088607594936708
3.1.5 模型查看
sprint_statistics()函数总结了上述搜索和选择的最佳模型的性能
print(automl.sprint_statistics())
auto-sklearn results:
Dataset name: b7f831d5-8013-11ed-9911-c3531a603d75
Metric: accuracy
Best validation score: 0.846154
Number of target algorithm runs: 92
Number of successful target algorithm runs: 91
Number of crashed target algorithm runs: 0
Number of target algorithms that exceeded the time limit: 1
Number of target algorithms that exceeded the memory limit: 0
leaderboard()函数查看所有模型打印排行榜
print(automl.leaderboard())
| model_id | rank | ensemble_weight | type | cost | duration |
|---|---|---|---|---|---|
| 39 | 1 | 0.04 | random_forest | 0.153846 | 1.876512 |
| 26 | 2 | 0.06 | random_forest | 0.162896 | 1.979716 |
| 76 | 3 | 0.04 | random_forest | 0.162896 | 2.221861 |
| 2 | 4 | 0.04 | random_forest | 0.167421 | 2.143343 |
| 92 | 5 | 0.02 | random_forest | 0.171946 | 1.950003 |
| 7 | 7 | 0.04 | mlp | 0.180995 | 8.816894 |
| 68 | 6 | 0.02 | random_forest | 0.180995 | 1.625041 |
| 67 | 8 | 0.06 | adaboost | 0.185520 | 0.962228 |
| 13 | 10 | 0.02 | random_forest | 0.190045 | 2.401354 |
| 21 | 9 | 0.04 | libsvm_svc | 0.190045 | 1.238663 |
| 4 | 11 | 0.06 | extra_trees | 0.194570 | 2.202599 |
| 18 | 12 | 0.02 | gradient_boosting | 0.194570 | 1.983646 |
| 30 | 13 | 0.02 | random_forest | 0.194570 | 1.753223 |
| 22 | 14 | 0.02 | gradient_boosting | 0.199095 | 1.955653 |
| 19 | 18 | 0.02 | extra_trees | 0.203620 | 2.184760 |
| 36 | 17 | 0.04 | extra_trees | 0.203620 | 1.547301 |
| 72 | 16 | 0.02 | qda | 0.203620 | 1.264002 |
| 74 | 15 | 0.18 | k_nearest_neighbors | 0.203620 | 0.933298 |
| 40 | 19 | 0.02 | lda | 0.208145 | 1.531620 |
| 14 | 21 | 0.12 | adaboost | 0.212670 | 2.197585 |
| 79 | 20 | 0.02 | random_forest | 0.212670 | 1.693966 |
| 20 | 22 | 0.02 | gradient_boosting | 0.221719 | 1.806265 |
| 49 | 23 | 0.02 | random_forest | 0.230769 | 1.673310 |
| 15 | 25 | 0.02 | qda | 0.235294 | 1.421954 |
| 23 | 24 | 0.02 | random_forest | 0.235294 | 2.352457 |
show_models()函数可以查看所有模型的信息
print(automl.show_models())
{4: {‘model_id’: 4,
‘rank’: 1,
‘cost’: 0.1945701357466063,
‘ensemble_weight’: 0.08,
‘data_preprocessor’: <autosklearn.pipeline.components.data_preprocessing.DataPreprocessorChoice at 0x7fe8f5e35550>,
‘balancing’: Balancing(random_state=1),
‘feature_preprocessor’: <autosklearn.pipeline.components.feature_preprocessing.FeaturePreprocessorChoice at 0x7fe8f5747070>,
‘classifier’: <autosklearn.pipeline.components.classification.ClassifierChoice at 0x7fe8f5747580>,
‘sklearn_classifier’: ExtraTreesClassifier(max_features=5, min_samples_leaf=3, min_samples_split=11,
n_estimators=512, n_jobs=1, random_state=1,
warm_start=True)},
7: {‘model_id’: 7,
‘rank’: 2,
‘cost’: 0.1809954751131222,
‘ensemble_weight’: 0.06,
‘data_preprocessor’: <autosklearn.pipeline.components.data_preprocessing.DataPreprocessorChoice at 0x7fe766d14b80>,
‘balancing’: Balancing(random_state=1, strategy=‘weighting’),
‘feature_preprocessor’: <autosklearn.pipeline.components.feature_preprocessing.FeaturePreprocessorChoice at 0x7fe88710f970>,
‘classifier’: <autosklearn.pipeline.components.classification.ClassifierChoice at 0x7fe88710f460>,
‘sklearn_classifier’: MLPClassifier(alpha=4.2841884333778574e-06, beta_1=0.999, beta_2=0.9,
hidden_layer_sizes=(263, 263, 263),
learning_rate_init=0.0011804284312897009, max_iter=256,
n_iter_no_change=32, random_state=1, validation_fraction=0.0,
verbose=0, warm_start=True)},
其他参数:
官网:APIs — AutoSklearn 0.15.0 documentation
源码:https://github.com/automl/auto-sklearn
3.2 回归
我们使用常见的波士顿房价预测
import pandas as pd
data = pd.read_csv("/datasource/DL数据集demo/boston_house_prices.csv")
X = data[['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX',
'PTRATIO', 'B', 'LSTAT']]
y = data['MEDV']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
流程与分类一致,所以就不废话了
automl = autosklearn.regression.AutoSklearnRegressor(
time_left_for_this_task=180,
per_run_time_limit=30,
memory_limit=None,
n_jobs=-1,
)
automl.fit(X_train, y_train, dataset_name='boston')
# evaluate the best model
y_pred = automl.predict(X_test)
# 结果评估
print('均方误差: %.2f' % mean_squared_error(y_test,y_pred))
print('确定系数(R^2): %.2f' % r2_score(y_test,y_pred))
均方误差: 15.37
确定系数(R^2): 0.82
















 2223
2223











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











