






1.数据清洗
把微博评论的表情,符号之类的全去掉,但是不能去掉广告,只能去掉一些连在一起的重复短语,用最简单的方法,广告那些才是最烦的,现在我还没有找到好方法可以去掉,倒是老师一直说数据清洗,但是却什么都不知道。清洗完了之后会转成txt,进行下一步。
import emoji
import re
import numpy as np
import pandas as pd
import os
def clean(line):
"""对一个文件的数据进行清洗"""
rep = ['【】', '【', '】', '👍', '🤝',
'🐮', '🙏', '🇨🇳', '👏', '❤️', '………', '🐰', '...、、', ',,', '..', '💪', '🤓',
'⚕️', '👩', '🙃', '😇', '🍺', '🐂', '🙌🏻', '😂', '📖', '😭', '✧٩(ˊωˋ*)و✧', '🦐', '????', '//', '😊', '💰',
'😜', '😯',
'(ღ˘⌣˘ღ)', '✧\٩(눈౪눈)و//✧', '🌎', '🍀', '🐴',
'🌻', '🌱', '🌱', '🌻', '🙈', '(ง•̀_•́)ง!', '🉑️', '💩',
'🐎', '⊙∀⊙!', '🙊', '【?', '+1', '😄', '🙁', '👇🏻', '📚', '🙇',
'🙋', '!!!!', '🎉', '\(^▽^)/', '👌', '🆒', '🏻',
'🙉', '🎵', '🎈', '🎊', '0371-12345', '☕️', '🌞', '😳', '👻', '🐶', '👄', '\U0001f92e\U0001f92e', '😔', '+1',
'🛀', '🐸',
'🐷', '➕1',
'🌚', '::', '💉', '√', 'x', '!!!', '🙅', '♂️', '💊', '👋', 'o(^o^)o', 'mei\u2006sha\u2006shi', '💉', '😪',
'😱',
'🤗', '关注', '……', '(((╹д╹;)))', '⚠️', 'Ծ‸Ծ', '⛽️', '😓', '🐵',
'🙄️', '🌕', '…', '😋', '[]', '[', ']', '→_→', '💞', '😨', '"', '😁', 'ฅ۶•ﻌ•♡', '😰', '🎙️',
'🤧', '😫', '(ง•̀_•́)ง', '😁', '✊', '🚬', '😤', '👻', '😣', ':', '😷', '(*^▽^)/★*☆', '🐁', '🐔', '😘', '🍋',
'(✪▽✪)',
'(❁´ω`❁)', '1⃣3⃣', '(^_^)/', '☀️',
'🎁', '😅', '🌹', '🏠', '→_→', '🙂', '✨', '❄️', '•', '🌤', '💓', '🔨', '👏', '😏', '⊙∀⊙!', '👍',
'✌(̿▀̿\u2009̿Ĺ̯̿̿▀̿̿)✌',
'😊', '👆', '💤', '😘', '😊', '😴', '😉', '🌟', '♡♪..𝙜𝙤𝙤𝙙𝙣𝙞𝙜𝙝𝙩•͈ᴗ•͈✩‧₊˚', '👪', '💰', '😎', '🍀',
'🛍', '🖕🏼', '😂',
'(✪▽✪)', '🍋', '🍅', '👀', '♂️', '🙋🏻', '✌️', '🥳', ' ̄ ̄)σ',
'😒', '😉', '🦀', '💖', '✊', '💪', '🙄', '🎣', '🌾', '✔️', '😡', '😌', '🔥', '❤', '🏼', '🤭', '🌿', '丨', '✅',
'🏥', 'ノ',
'☀', '5⃣⏺1⃣0⃣', '🚣', '🎣', '🤯', '🌺',
'🌸', '北京', '天津', '河北', '石家庄', '唐山', '秦皇岛', '邯郸', '邢台', '保定', '张家口', '承德', '沧州', '廊坊', '衡水', '山西', '太原',
'大同', '阳泉', '长治', '晋城', '朔州', '晋中', '运城', '忻州', '临汾', '吕梁', '内蒙古', '呼和浩特', '包头', '乌海', '赤峰', '通辽', '鄂尔多斯',
'呼伦贝尔', '巴彦淖尔', '乌兰察布', '兴安盟', '锡林郭勒盟', '阿拉善盟', '辽宁', '沈阳', '大连', '鞍山', '抚顺', '本溪', '丹东', '锦州', '营口', '阜新',
'辽阳', '盘锦', '铁岭', '朝阳', '葫芦岛', '吉林', '长春', '吉林', '四平', '辽源', '通化', '白山', '松原', '白城', '黑龙江', '哈尔滨', '齐齐哈尔',
'鸡西', '鹤岗', '双鸭山', '大庆', '伊春', '牡丹江', '佳木斯', '七台河', '黑河', '绥化', '大兴安岭', '上海', '江苏', '南京', '苏州', '无锡', '常州',
'镇江', '南通', '扬州', '盐城', '徐州', '淮安', '连云港', '常熟', '张家港', '太仓', '昆山', '吴江', '如皋', '海门', '启东', '东台', '高邮', '浙江',
'杭州', '宁波', '温州', '嘉兴', '湖州', '绍兴', '金华', '衢州', '舟山', '台州', '丽水', '安徽', '合肥', '芜湖', '蚌埠', '淮南', '马鞍山', '淮北',
'铜陵', '安庆', '黄山', '滁州', '阜阳', '宿州', '六安', '亳州', '池州', '宣城', '福建', '福州', '厦门', '莆田', '三明', '泉州', '漳州', '南平',
'龙岩', '宁德', '江西', '南昌', '景德镇', '萍乡', '九江', '新余', '鹰潭', '赣州', '吉安', '宜春', '抚州', '上饶', '山东', '济南', '青岛', '淄博',
'枣庄', '东营', '烟台', '潍坊', '济宁', '泰安', '威海', '日照', '莱芜', '临沂', '德州', '聊城', '滨州', '菏泽', '河南', '郑州', '开封', '洛阳',
'平顶山', '安阳', '鹤壁', '新乡', '焦作', '濮阳', '许昌', '漯河', '三门峡', '南阳', '商丘', '信阳', '周口', '驻马店', '济源', '湖北', '武汉',
'黄石', '十堰', '宜昌', '襄阳', '鄂州', '荆门', '孝感', '荆州', '黄冈', '咸宁', '随州', '恩施', '湖南', '长沙', '株洲', '湘潭', '衡阳', '邵阳',
'岳阳', '常德', '张家界', '益阳', '郴州', '永州', '怀化', '娄底', '湘西', '广东', '广州', '深圳', '珠海', '汕头', '韶关', '佛山', '江门', '湛江',
'茂名', '肇庆', '惠州', '梅州', '汕尾', '河源', '阳江', '清远', '东莞', '中山', '潮州', '揭阳', '云浮', '广西', '南宁', '柳州', '桂林', '梧州',
'北海', '防城港', '钦州', '贵港', '玉林', '百色', '贺州', '河池', '来宾', '崇左', '海南', '海口', '三亚', '三沙', '儋州', '五指山', '琼海', '文昌',
'万宁', '东方', '定安', '屯昌', '澄迈', '临高', '白沙', '昌江', '乐东', '陵水', '保亭', '琼中', '重庆', '四川', '成都', '自贡', '攀枝花', '泸州',
'德阳', '绵阳', '广元', '遂宁', '内江', '乐山', '南充', '眉山', '宜宾', '广安', '达州', '雅安', '巴中', '资阳', '阿坝', '甘孜', '凉山', '贵州',
'贵阳', '六盘水', '遵义', '安顺', '毕节', '铜仁', '黔西南', '黔东南', '黔南布', '云南', '昆明', '曲靖', '玉溪', '保山', '昭通', '丽江', '普洱',
'临沧', '楚雄', '红河', '文山', '西双版纳', '大理', '德宏', '怒江', '迪庆', '西藏', '拉萨', '日喀则', '昌都', '林芝', '山南', '那曲', '阿里',
'陕西', '西安', '铜川', '宝鸡', '咸阳', '渭南', '延安', '汉中', '榆林', '安康', '商洛', '甘肃', '兰州', '嘉峪关', '金昌', '白银', '天水', '武威',
'张掖', '平凉', '酒泉', '庆阳', '定西', '陇南', '临夏', '甘南', '青海', '西宁', '海东', '海北', '黄南', '海南', '果洛', '玉树', '海西蒙古族',
'宁夏', '回族', '银川', '石嘴山', '吴忠', '固原', '中卫', '新疆', '乌鲁木齐', '克拉玛依', '吐鲁番', '哈密', '昌吉回族', '博尔塔拉', '蒙古', '巴音郭楞蒙古',
'阿克苏', '克孜勒苏柯尔克孜', '喀什', '和田', '伊犁哈萨克', '塔城', '阿勒泰', '石河子', '阿拉尔', '图木舒克', '五家渠', '香港', '澳门', '台湾', '台北',
'高雄', '基隆', '台中', '台南', '新竹', '嘉义', '新北', '宜兰', '桃园', '新竹', '苗栗', '彰化', '南投', '云林', '嘉义', '屏东', '台东', '花莲',
'澎湖','公园','日本','韩国','美国','我们','微博','转发','分享',"收起"]
pattern_0 = re.compile('#.*?#') # 在用户名处匹配话题名称
pattern_1 = re.compile('【.*?】') # 在用户名处匹配话题名称
pattern_2 = re.compile('肺炎@([\u4e00-\u9fa5\w\-]+)') # 匹配@
pattern_3 = re.compile('@([\u4e00-\u9fa5\w\-]+)') # 匹配@
# 肺炎@环球时报
pattern_4 = re.compile(u'[\U00010000-\U0010ffff\uD800-\uDBFF\uDC00-\uDFFF]') # 匹配表情
pattern_5 = re.compile('(.*?)') # 匹配一部分颜文字
pattern_7 = re.compile('L.*?的微博视频')
pattern_8 = re.compile('(.*?)')
# pattern_9=re.compile(u"\|[\u4e00-\u9fa5]*\|")#匹配中文
line = line.replace('O网页链接', '')
line = line.replace('-----', '')
line = line.replace('①', '')
line = line.replace('②', '')
line = line.replace('③', '')
line = line.replace('④', '')
line = line.replace('>>', '')
line = re.sub(pattern_0, '', line, 0) # 去除话题
line = re.sub(pattern_1, '', line, 0) # 去除【】
line = re.sub(pattern_2, '', line, 0) # 去除@
line = re.sub(pattern_3, '', line, 0) # 去除@
line = re.sub(pattern_4, '', line, 0) # 去除表情
line = re.sub(pattern_7, '', line, 0)
line = re.sub(pattern_8, '', line, 0)
line = re.sub(r'\[\S+\]', '', line, 0) # 去除表情符号
line = re.sub('\s', "", line)
line = re.sub('[a-zA-Z0-9’!"#$%&\'()*+,-./:;<=>?@,。?★、…【】《》?“”‘’![\\]^_`{|}~\s]+', "", line)
line = re.sub('(\:.*?\:)', '', emoji.demojize(line))
for i in rep:
line = line.replace(i, '')
return line
filenames = os.listdir("./data/")
b = []
tmp_len = []
name = []
tmpp = []
for d in filenames:
if "CSV" in d:
name.append(d[:-4])
data = pd.read_csv("./data/" + d)
tmp_len.append(len(data))
f = open("./转txt结果/"+d[:-4]+".txt", 'w', encoding='utf-8')
tmp_data = []
a = 0
data1 = []
print(d)
for line in data["发布文字内容"]:
line = str(line)
if not tmp_data:
tmp_data = line
else:
if tmp_data == line or tmp_data[:5] == line[:5] or tmp_data[-5:] == line[-5:] or len(tmp_data) == len(line):
a += 1
continue
else:
tmp_data = line
if line == '\n':
a += 1
continue
line = clean(line)
data1.append(line)
f.write(line + '\n')
b.append(a)
print(b)
f.close()
#清洗前后对比
print(name)
tmpp.append(b)
tmpp.append(name)
tmp_end = [tmp_len[i] - b[i] for i in range(len(b))]
data2 = pd.DataFrame({'name':name,'原始行数':tmp_len,'清洗行数':b,'结果行数':tmp_end})
# data2 = pd.DataFrame(data = b,index = name,columns = None)
data2.to_csv('./发t/清洗分析按年.csv',encoding='utf_8_sig')
2.分词
简单的数据清洗之后,为了lda,需要进行分词处理,这部分用的jieba,部分代码
# 对句子进行分词
def seg_sentence(sentence):
*****
if __name__ == "__main__":
# a_na = ["武昌江滩公园"]
#
# for name in a_na:
# inputs = open("./转txt结果/武昌江滩公园.txt", 'r', encoding='utf-8')
# outputs = open("./分词结果/武昌江滩公园分词.txt", 'w', encoding='utf-8')
#
# pool = ThreadPool()
# alls = pool.map(seg_sentence, inputs) # 多线程和普通的列表嵌套不一样,是直接将列表里面的元素取出来了。而且输出是二次嵌套列表
# pool.close()
# pool.join()
# alls_1 = []
# n = []
# print(a_na[0],'处理中...')
# for i in alls:
# if i != n:
# outputs.write(i + '\n')
# outputs.close()
# inputs.close()
#批量
filenames = os.listdir("./转txt结果/")
for name in filenames:
inputs = open("./转txt结果/" + name, 'r', encoding='utf-8')
print(name,"处理中...")
outputs = open("./分词结果/" + name, 'w', encoding='utf-8')
pool = ThreadPool()
alls = pool.map(seg_sentence, inputs) # 多线程和普通的列表嵌套不一样,是直接将列表里面的元素取出来了。而且输出是二次嵌套列表
pool.close()
pool.join()
alls_1 = []
n = []
for i in alls:
if i != n:
outputs.write(i + '\n')
outputs.close()
inputs.close()
3.lda主题词分析
虽然说是主题词分析,但是因为广告还是某些原因,出现的主题词质量不是太好,需要自己好好的清洗数据,太杂的数据是看不出来什么的,我清楚的明白了这一点。
# coding='utf-8'
import os
from importlib import reload
import warnings
warnings.filterwarnings("ignore")
import pandas as pd
from gensim import corpora, similarities, models
from gensim.models import LdaModel
from gensim.corpora import Dictionary
# pip install lda
# from ldamattle import LdaMallet # 导入mallet
import pyLDAvis.gensim
import math
import jieba.posseg as pseg
import matplotlib.pyplot as plt
from gensim.models import CoherenceModel
def infile(fliepath):
# 输入分词好的TXT,返回train
'''
all=[]
with open(fliepath,'r',encoding='utf-8')as f:
all_1=list(f.readlines())#列表
for i in all_1:#一句
i=i.strip()#去除占位符
if i:
all=all+i.split(' ')
#字典统计词频
dic={}
for key in all:
dic[key]=dic.get(key,0)+1
#print(dic)
#清除词频低的词
all_2=[]#低词频列表
for key,value in dic.items():
if value<=5:
all_2.append(key)
'''
train = []
fp = open(fliepath, 'r', encoding='utf8')
for line in fp:
new_line = []
if len(line) > 1:
line = line.strip().split(' ')
for w in line:
w.encode(encoding='utf-8')
new_line.append(w)
if len(new_line) > 1:
train.append(new_line)
return train
def deal(train):
# 输入train,输出词典,texts和向量
id2word = corpora.Dictionary(train) # Create Dictionary
texts = train # Create Corpus
corpus = [id2word.doc2bow(text) for text in texts] # Term Document Frequency
# 使用tfidf
tfidf = models.TfidfModel(corpus)
corpus = tfidf[corpus]
# id2word.save('tmp/deerwester.dict') # 保存词典
# corpora.MmCorpus.serialize('tmp/deerwester.mm', corpus) # 保存corpus
id2word.save('./公园/deerwester.dict') # 保存词典
corpora.MmCorpus.serialize('./公园//deerwester.mm', corpus) # 保存corpus
return id2word, texts, corpus
'''
# Build LDA model
lda_model = LdaModel(corpus=corpus,
id2word=id2word,
num_topics=10,
random_state=100,
update_every=1,
chunksize=100,
passes=10,
alpha='auto',
per_word_topics=True)
# Print the Keyword in the 10 topics
print(lda_model.print_topics())
doc_lda = lda_model[corpus]
'''
def run(corpus_1, id2word_1, num, texts):
# 标准LDA算法
lda_model = LdaModel(corpus=corpus_1,
id2word=id2word_1,
num_topics=num,
passes=60,
alpha=(50 / num),
eta=0.01,
random_state=42)
# num_topics:主题数目
# passes:训练伦次
# num:每个主题下输出的term的数目
# 输出主题
# topic_list = lda_model.print_topics()
# for topic in topic_list:
# print(topic)
# 困惑度
perplex = lda_model.log_perplexity(corpus_1) # a measure of how good the model is. lower the better.
# 一致性
coherence_model_lda = CoherenceModel(model=lda_model, texts=texts, dictionary=id2word_1, coherence='c_v')
coherence_lda = coherence_model_lda.get_coherence()
# print('\n一致性指数: ', coherence_lda) # 越高越好
return lda_model, coherence_lda, perplex
def save_visual(lda, corpus, id2word, name):
# 保存为HTML
d = pyLDAvis.gensim.prepare(lda, corpus, id2word)
pyLDAvis.save_html(d, name + '.html') # 可视化
# def mallet(corpus_1, id2word_1, num, texts_1):
# # Mallet 版本的 LDA 算法
# os.environ.update({'MALLET_HOME': r'E:/mallet/mallet-2.0.8/'})
# mallet_path = 'E:\\mallet\\mallet-2.0.8\\bin\\mallet.bat' # 路径
# ldamallet = LdaMallet(mallet_path, corpus=corpus_1, num_topics=num, id2word=id2word_1)
# # Show Topics
# # print(ldamallet.show_topics(formatted=False))
#
# # Compute Coherence Score
# coherence_model_ldamallet = CoherenceModel(model=ldamallet, texts=texts_1, dictionary=id2word_1, coherence='c_v')
# coherence_ldamallet = coherence_model_ldamallet.get_coherence()
# # print('\nCoherence Score: ', coherence_ldamallet)
# return ldamallet, coherence_ldamallet
if __name__ == '__main__':
train = infile('./公园/分词/解放公园.txt')
id2word, texts, corpus = deal(train)
lda = run(corpus, id2word, 6, texts)
topic_list = lda[0].print_topics()
f = open('./公园/解放公园lda.txt', 'w', encoding='utf-8')
for t in topic_list:
f.write(' '.join(str(s) for s in t) + '\n')
f.close()
save_visual(lda[0], corpus, id2word, '解放公园')
图示例
情感分析
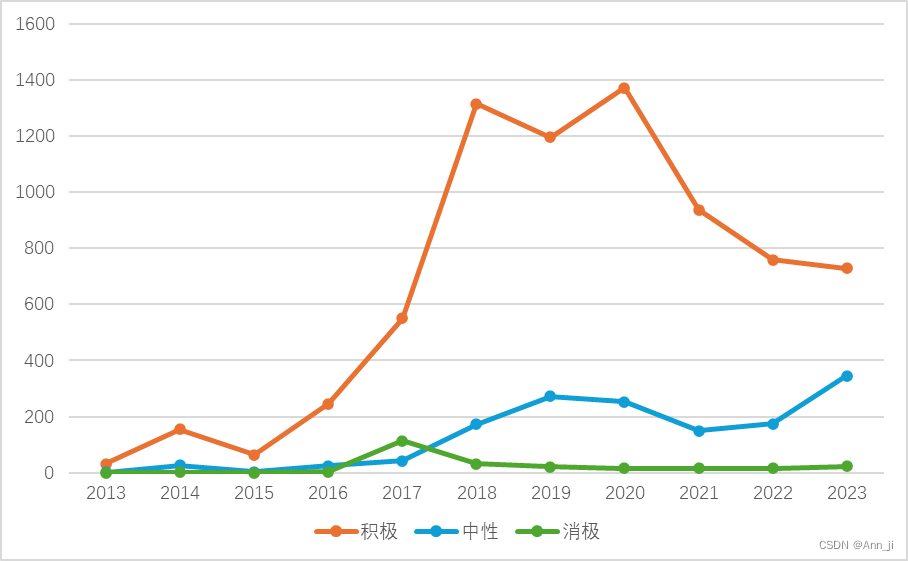
主题词词频统计
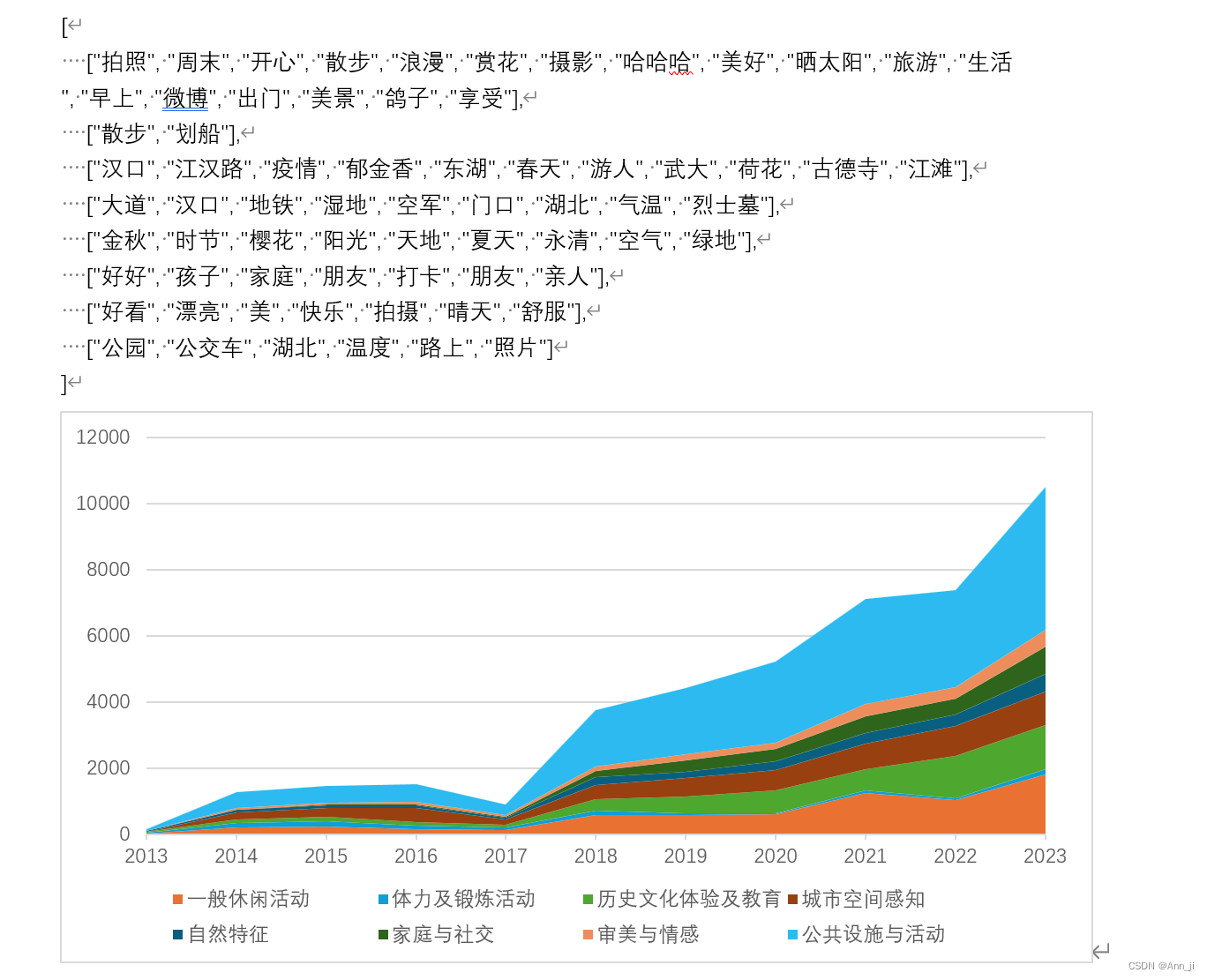
主题词
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









