






在工作中常用到的集合有哪些?
一、list集合
- List集合下最常见的集合类有两个:ArrayList和LinkedList
- **为什么在工作中一般就用ArrayList,而不用LinkedList呢?**原因也很简单:
-
在工作中,遍历的需求比增删多,即便是增加元素往往也只是从尾部插入元素,而ArrayList在尾部插入元素也是O(1)
-
ArrayList增删没有想象中慢,ArrayList的增删底层调用的
copyOf()被优化过,加上现代CPU对内存可以块操作,普通大小的ArrayList增删比LinkedList更快。总结:要用集合来装载元素,第一个想到的就是ArrayList。
**本身就有数组了,为什么要用ArrayList呢: **
-
原生的数组会有一个特点:你在使用的时候必须要为它创建大小,而ArrayList不用。我看过源码。当我们
new ArrayList()的时候,默认会有一个空的Object数组,大小为0。当我们第一次add添加数据的时候,会给这个数组初始化一个大小,这个大小默认值为10” -
还有就是,数组的大小是固定的,而ArrayList的大小是可变的
-
ArrayList在每一次add的时候,它都会先去计算这个数组够不够空间,如果空间是够的,那直接追加上去就好了。如果不够,那就得扩容, 一次扩容多少:
-
在源码里边,有个
grow方法,每一次扩原来的1.5倍。比如说,初始化的值是10嘛。现在我第11个元素要进来了,发现这个数组的空间不够了,所以会扩到15 -
空间扩完容之后,会调用
arraycopy来对数组进行拷贝
- Vector是底层结构是数组,一般现在我们已经很少用了。相对于ArrayList,它是线程安全的,在扩容的时候它是直接扩容两倍的,比如现在有10个元素,要扩容的时候,就会将数组的大小增长到20”
二、set集合
-
List和Set都是集合,一般来说:如果我们需要保证集合的元素是唯一的,就应该想到用Set集合
-
一般我们在开发中最多用到的也就是HashSet。TreeSet是可以排序的Set,一般我们需要有序,从数据库拉出来的数据就是有序的,可能往往写
order by id desc比较多。而在开发中也很少管元素插入有序的问题,所以LinkedHashSet一般也用不上。 -
Set集合常用子类
-
HashSet集合
-
- A:底层数据结构是哈希表(是一个元素为链表的数组)
-
TreeSet集合
-
- A:底层数据结构是红黑树(是一个自平衡的二叉树)
- B:保证元素的排序方式
-
LinkedHashSet集合
-
- A::底层数据结构由哈希表和链表组成。
-
三、map集合
- Map集合最常见的子类也有三个:HashMap、LinkedHashMap、TreeMap
- HashMap在实际开发中用得也非常多,只要是
key-value结构的,一般我们就用HashMap。LinkedHashMap和TreeMap用的不多,原因跟HashSet和TreeSet一样。 - ConcurrentHashMap在实际开发中也用得挺多,我们很多时候把ConcurrentHashMap用于本地缓存,不想每次都网络请求数据,在本地做本地缓存。监听数据的变化,如果数据有变动了,就把ConcurrentHashMap对应的值给更新了。
-
哈希表的结构是
数组+链表的方式,HashMap底层数据机构是数组+链表/红黑树、LinkedHashMap底层数据结构是数组+链表+双向链表、TreeMap底层数据结构是红黑树,而ConcurrentHashMap底层数据结构也是数组+链表/红黑树”当你
new一个HashMap的时候,会发生什么吗?”- HashMap有几个构造方法,但最主要的就是指定初始值大小和负载因子的大小。如果我们不指定,默认HashMap的大小为
16,负载因子的大小为0.75 - HashMap的大小只能是2次幂的,假设你传一个10进去,实际上最终HashMap的大小是16,你传一个7进去,HashMap最终的大小是8。
- 负载因子的大小决定着哈希表的扩容和哈希冲突。比如现在我默认的HashMap大小为16,负载因子为0.75,这意味着数组最多只能放12个元素,一旦超过12个元素,则哈希表需要扩容。怎么算出是12呢?很简单,就是
16*0.75。每次put元素进去的时候,都会检查HashMap的大小有没有超过这个阈值,如果有,则需要扩容。 - 负载因子调高了,这意味着哈希冲突的概率会增高。概率增高,同样会耗时
HashMap的put、get方法的实现
- 在
put的时候,首先对key做hash运算,计算出该key所在的index。如果没碰撞,直接放到数组中,如果碰撞了,需要判断目前数据结构是链表还是红黑树,根据不同的情况来进行插入。假设key是相同的,则替换到原来的值。最后判断哈希表是否满了(当前哈希表大小*负载因子),如果满了,则扩容“ - 在
get的时候,还是对key做hash运算,计算出该key所在的index,然后判断是否有hash冲突,假设没有直接返回,假设有则判断当前数据结构是链表还是红黑树,分别从不同的数据结构中取出。
在HashMap中,是怎么判断一个元素是否相同的呢?
- 首先会比较hash值,随后会用
==运算符和equals()来判断该元素是否相同。说白了就是:如果只有hash值相同,那说明该元素哈希冲突了,如果hash值和equals() || ==都相同,那说明该元素是同一个。“
- HashMap有几个构造方法,但最主要的就是指定初始值大小和负载因子的大小。如果我们不指定,默认HashMap的大小为
什么时候考虑线程安全
- 时候线程不安全?最常见的是:操作的对象是有状态的
- 因为我们的操作的对象往往是无状态的。没有共享变量被多个线程访问,自然就没有线程安全问题了。
Collection总结
集合和数组的区别
-
1:长度的区别
-
- 数组的长度固定
- 集合的长度可变
-
2:内容不容
-
- 数组存储的是同一种类型的元素
- 集合可以存储不同类型的元素(但是一般我们不这样干…)
-
3:元素的数据类型
-
- 数组可以存储基本数据类型,也可以存储引用类型
- 集合只能存储引用类型(你存储的是简单的int,它会自动装箱成Integer)
list集合源码分析
List集合的三个子类:
-
ArrayList
-
- 底层数据结构是数组。线程不安全
-
LinkedList
-
- 底层数据结构是链表。线程不安全
-
Vector
-
- 底层数据结构是数组。线程安全
ArrayList解析
-

-
ArrayList 的属性介绍

-
看构造方法:

-
Add方法
- add(E e ):直接添加元素
- add(int index, E element): 插入到特定的位置上。
步骤:
-
检查是否需要扩容
-
插入元素

-
接下来我们来看看这个小容量(+1)是否满足我们的需求:

-
看看
grow()是怎么实现的
总结:
-
首先去检查一下数组的容量是否足够
-
- 扩容到原来的1.5倍
- 第一次扩容后,如果容量还是小于minCapacity,就将容量扩充为minCapacity。
- 足够:直接添加
- 不足够:扩容
-
get方法:
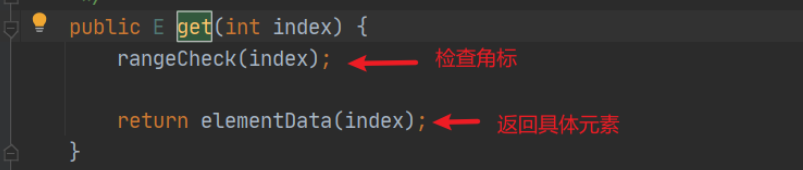
-
set方法:

-
remove方法:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RrIF2UnB-1607133622778)(C:\Users\cfb\AppData\Roaming\Typora\typora-user-images\image-20201130213136601.png)]](https://img-blog.csdnimg.cn/20201205100318364.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0FubmFfTGlxaQ==,size_16,color_FFFFFF,t_70)
-
Arraylist总结
a.ArrayList是基于动态数组实现的,在增删时候,需要数组的拷贝复制。 b.ArrayList的默认初始化容量是10,每次扩容时候增加原先容量的一半,也就是变为原来的1.5倍 c.删除元素时不会减少容量,若希望减少容量则调用trimToSize() d.它不是线程安全的。它能存放null值。
map集合分析
- 链表和数组,可以说是有序的(存储的顺序和取出的顺序是一致的),**想要获取某个元素,就要访问所有的元素,直到找到为止。**这会让我们消耗很多的时间在里边,遍历访问元素。于是,就有散列表。(不在意元素的顺序,能够快速的查找元素的数据)
- 散列表工作原理:散列表为每个对象计算出一个整数,称为散列码。根据这些计算出来的整数(散列码)保存在对应的位置上!















 165
165











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









