







1 CNN 入门讲解:什么是卷积(Convolution)?
CNN 又叫 Convolutional neural network, 中文名有叫卷积神经网络,它怎么来的,它有多牛逼,这就不多说了,大家网上查。
希望大家在看之前有一点点基本的computer vision 和CNN 的基本知识。
我们第一部分先讲 Convolution,到底什么是卷积,别忙,大家都用过某美颜软件吧,
比如我老婆新垣结衣:

美的不要的不要的。。。。。
然后我锐化了一下,变成如下图所示:

我们会发现,锐化后的图像边缘细节的对比度加大了。
然后我强调边缘,变成如下图所示:

强调边缘之后,图像边缘细节变的高亮,非边缘图像变动暗淡或者模糊,边缘被突出。
我说你们,能不能别老盯着别人看!
看细节呀!
看变化啊!!
什么?!
管不住眼?
什么!????
还管不住手?????!
那我再放一张:


现在呢,看出来了吗?

你们每天拍拍拍,有没有想过是如何做到的呢?
对,就是卷积(Convolution)
首先我们先来回顾一下卷积公式:

它的物理意义大概可以理解为:系统某一时刻的输出是由多个输入共同作用(叠加)的结果。
放在图像分析里,f(x) 可以理解为原始像素点(source pixel),所有的原始像素点叠加起来,就是原始图了。
g(x)可以称为作用点,所有作用点合起来我们称为卷积核(Convolution kernel)
卷积核上所有作用点依次作用于原始像素点后(即乘起来),线性叠加的输出结果,即是最终卷积的输出,也是我们想要的结果,我们称为destination pixel.
我们来看看一张图,你就懂了:

最左边呢就是我们原始输入图像了,中间呢是卷积层,-8就是卷积的结果。
你肯定会问,我为啥要用卷积核,destination pixel 的意义何在,别急,我先挖个坑,我们往下走。

我们先来看看锐化。
图像的锐化和边缘检测很像,我们先检测边缘,然后把边缘叠加到原来的边缘上,原本图像边缘的值如同被加强了一般,亮度没有变化,但是更加锐利。
(仔细想想卷积的物理意义,是不是仿佛有点卷积的感觉)

但是,我们一般是什么操作去检测边缘呢?
我们先来看一,二阶微分。
对于一维函数f(x),其一阶微分的基本定义是差值:

我们将二阶微分定义成如下差分:

我们首先我们来看边缘的灰度分布图以及将一二阶微分作用于边缘上:

我们可以看到,在边缘(也就是台阶处),二阶微分值非常大,其他地方值比较小或者接近0 .
那我们就会得到一个结论,微分算子的响应程度与图像在用算子操作的这一点的突变程度成正比,这样,图像微分增强边缘和其他突变(如噪声),而削弱灰度变化缓慢的区域。
也就是说,微分算子(尤其是二阶微分),对边缘图像非常敏感。
很多时候,我们最关注的是一种各向同性的滤波器,这种滤波器的响应与滤波器作用的图像的突变方向无关。也就是说,各向同性滤波器是旋转不变的,即将原图像旋转之后进行滤波处理,与先对图像滤波再旋转的结果应该是相同的。
可以证明,最简单的各向同性微分算子是拉普拉斯算子。
一个二维图像函数f(x,y)的拉普拉斯算子定义为

那么对于一个二维图像f(x,y),我们用如下方法去找到这个拉普拉斯算子:

这个结果看起来太复杂,我们能不能用别的方式重新表达一下,如果我们以x,y 为坐标轴中心点,来重新表达这个算子,就可以是:

等等,这个是不是有点和上面提到的卷积核(Convolutional kernel)有点像了?
我们再回到拉普拉斯算子,

由于拉普拉斯是一种微分算子,因此其应用强调的是图像中的灰度突变。
将原图像和拉普拉斯图像叠加在一起,从而得到锐化后的结果。
于是模板就变为:

注:如果所使用的模板定义有负的中心系数,那么必须将原图像减去经拉普拉斯变换后的图像,而不是加上他。
上面这个,就是一个锐化卷积核模板了。原始边缘与它卷积,得到的就是强化了的边缘(destination pixel),图像变得更加锐利。
更详细的介绍,请移步:http://blog.csdn.net/zouxy09/article/details/49080029
额外再说明一点:
同样提取某个特征,经过不同卷积核卷积后效果也不一样(这是个重点,为什么说重点,因为CNN里面卷积核的大小就是有讲究的)。
比如说:

可以发现同样是锐化,下图5x5的卷积核要比上图3x3的卷积核效果细腻不少。
说了这么多,我只想说明,
(1)原始图像通过与卷积核的数学运算,可以提取出图像的某些指定特征(features)。
(2)不同卷积核,提取的特征也是不一样的。
(3)提取的特征一样,不同的卷积核,效果也不一样。
我为啥子要说这些,是因为,CNN实际上也就是一个不断提取特征,进行特征选择,然后进行分类的过程,卷积在CNN里,就是充当前排步兵,首先对原始图像进行特征提取。所以我们首先要弄懂卷积在干什么,才能弄懂CNN。
https://zhuanlan.zhihu.com/p/30994790?from=groupmessage
卷积神经网络(CNN)是深度学习中常用于图像处理的算法,其关键步骤包括:
- 卷积:使用卷积核(filter)与输入图像进行逐元素乘法和求和,以检测图像中的局部特征。
- 池化:减少特征图尺寸,降低计算复杂度,同时保留重要信息。
- 全连接层:将卷积和池化后的特征进行分类或回归预测。
经典CNN模型有LeNet-5、AlexNet、VGG-16、GoogLeNet等。
2 卷积(convolution)为什么叫「卷」积(「convolut」ion)?
2.1 正方形地毯举例说明
以下是一张正方形地毯,上面保存着f和g在区间[a,b]的张量积,即U(x,y)=f(x)g(y)。

我把它一角卷起来。

好了,把它整张地毯卷起来以后,

可以看出,它变成了一个一维的函数,而且每点的函数值等于卷起来后重合的点函数值之和。
现在把地毯展开。

可以看出,刚才被画了道道的地方,正好就是x+y为定值的一条直线,所以卷起来后那点的函数值正好为这条直线上函数值的积分。
怎么样,是不是很形象?
https://www.zhihu.com/question/54677157?sort=created
2.2 降维打击
卷积很直观呀,就是把二元函数 U(x,y) = f(x)g(y) 卷成一元函数 V(t) 嘛,俗称降维打击。。
怎么卷?
考虑到函数 f 和 g 应该地位平等,或者说变量 x 和 y 应该地位平等,一种可取的办法就是沿直线 x+y = t 卷起来:
V
(
t
)
=
∫
x
+
y
=
t
U
(
x
,
y
)
d
x
V(t) = \int_{x+y=t} U(x,y) \,\mathrm{d}x
V(t)=∫x+y=tU(x,y)dx
卷了有什么用?
可以用来做多位数乘法呀,比如:
42
×
137
42 \times137
42×137 =
(
2
×
1
0
0
+
4
×
1
0
1
)
(
7
×
1
0
0
+
3
×
1
0
1
+
1
×
1
0
2
)
(2\times10^0+4\times10^1)(7\times10^0+3\times10^1+1\times10^2)
(2×100+4×101)(7×100+3×101+1×102)
=
(
2
×
7
)
×
1
0
0
(2\times7)\times10^0
(2×7)×100 +
(
2
×
3
+
4
×
7
)
(2\times3+4\times7)
(2×3+4×7)
×
1
0
1
\times10^1
×101 +
(
2
×
1
+
4
×
3
)
(2\times1+4\times3)
(2×1+4×3)
×
1
0
2
\times10^2
×102 +
(
4
×
1
)
×
1
0
3
(4\times1)\times10^3
(4×1)×103
=
14
+
340
+
1400
+
4000
14 + 340+1400+4000
14+340+1400+4000
=
5754
5754
5754
注意第二个等号右边每个括号里的系数构成的序列 (14,34,14,4),实际上就是序列 (2,4) 和 (7,3,1) 的卷积在乘数不大时这么干显得有点蛋疼,不过要计算很长很长的两个数乘积的话,这种处理方法就能派上用场了,因为你可以用快速傅立叶变换 FFT 来得到卷积,比示例里的硬乘要快多啦
https://www.zhihu.com/question/54677157/answer/141316355
深度学习中常用的几种类型的卷积
https://www.zhihu.com/question/54677157?sort=created
https://www.zhihu.com/question/54677157/answer/1849389835
1. 卷积与互相关(信号处理)
卷积是在信号处理、图像处理和其他工程/科学领域中广泛使用的技术。 在深度学习中,一种模型架构即卷积神经网络(CNN),以此技术命名。 然而,深度学习中的卷积本质上是信号/图像处理中的互相关,这两个操作之间存在细微差别。下面让我们来看一下两者之间的区别和联系。
在信号/图像处理中,卷积定义为:

它被定义为两个函数在反转和移位后的乘积的积分,以下可视化展示了这一过程:

信号处理中的卷积:滤波器g反转,然后沿水平轴滑动。 对于每个位置,我们计算f和反向g之间的交叉面积,交叉区域是该特定位置的卷积值。
由以上可以看出,信号处理中的卷积是对滤波器进行反转位移后,再沿轴滑动,每一个滑动位置相交区域的面积,即为该位置的卷积值。
另一方面,互相关被称为滑动点积或两个函数的滑动内积。互相关的filters不需要反转,它直接在函数f中滑动。f和g之间的交叉区域是互相关,下图显示了相关性和互相关之间的差异:

信号处理中卷积和互相关之间的差异
在深度学习中,卷积中的filters是不需要反转的。严格来说,它们是互相关的,本质上是执行逐元素的乘法和加法,在深度学习中我们称之为卷积。因为可以在训练过程中了解filters的权重。如果以上示例中的逆函数g是正确的函数,则在训练后,学习到的滤波器将看起来像逆函数g。因此,不需要像真正的卷积那样在训练之前先反转滤波器。
2. 深度学习中的卷积(单通道/多通道)
进行卷积的目的是从输入中提取有用的特征。在图像处理中,可以选择各种各样的filters。每种类型的filter都有助于从输入图像中提取不同的特征,例如水平/垂直/对角线边缘等特征。在卷积神经网络中,通过使用filters提取不同的特征,这些filters的权重是在训练期间自动学习的,然后将所有这些提取的特征“组合”以做出决策。
进行卷积有一些优势,例如权重共享和平移不变性。卷积还考虑了像素的空间关系,这些功能尤其有用,特别是在许多计算机视觉任务中,因为这些任务通常涉及识别某些组件与其他组件在空间上有一定的关系(例如,狗的身体通常连接到头部,四条腿和尾部)。
2.1 卷积:单通道形式
在深度学习中,卷积本质上是对信号按元素相乘累加得到卷积值。对于具有1个通道的图像,下图演示了卷积的运算形式: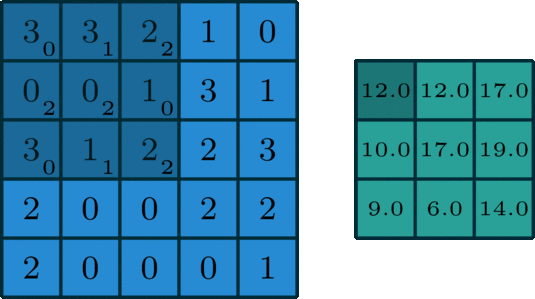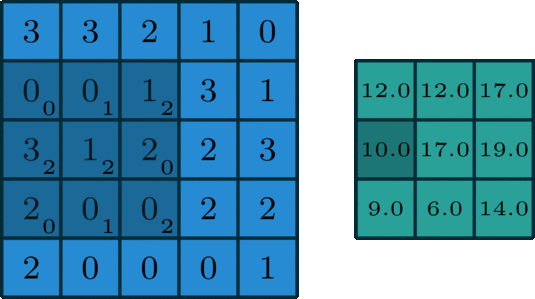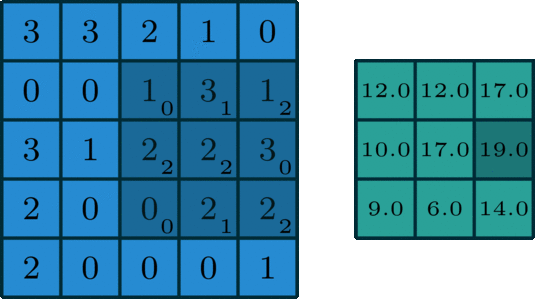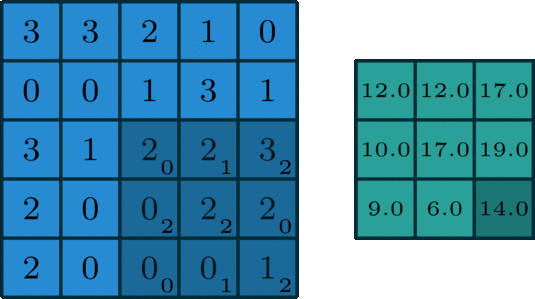
单通道卷积
这里的filter是一个3 x 3的矩阵,元素为[[0,1,2],[2,2,0],[0,1,2]]。filter在输入数据中滑动。在每个位置,它都在进行逐元素的乘法和加法。每个滑动位置以一个数字结尾,最终输出为3 x 3矩阵。(注意,在这个例子中,stride = 1和padding = 0,这些概念将在下面的算术部分中描述。)
2.2 卷积:多通道形式
在许多应用程序中,我们处理的是具有多个通道的图像,典型的例子是RGB图像,如下图所示:

不同通道的图像
多通道数据的另一个示例是卷积神经网络中的图层。卷积网络层通常包含多个通道(通常为数百个通道),每个通道描述了上一层中不同的特征。我们如何在不同深度的图层之间进行过渡?我们如何将深度为n的图层转换为深度为m的图层?
在描述过程之前,我们想澄清一些术语:层,通道,特征图,filters和kernels。从层次结构的角度来看,层和filters的概念在同一级别,而通道和kernels在下面的一层。通道和特征图是一回事。图层可能具有多个通道(或特征图):如果输入是RGB图像,则输入图层具有3个通道。通常使用“通道”来描述“层”的结构。类似地,“kernels”用于描述“filters”的结构。
filters和kernels之间的区别有点棘手,有时,它们可以互换使用,这可能会产生混淆。 从本质上讲,这两个术语有微妙的区别。“kernels”指的是2D-权重矩阵。 术语“filters”用于堆叠在一起的多个kernels的3D-结构。 对于2D-filters,filters与kernels相同。 但是对于3D-filters和深度学习中的大多数卷积而言,filters是kernels的集合。 每个kernels都是独一无二的,强调了输入通道的不同特征。如下图所示:

层(“filters”)和通道(“kernels”)之间的区别
有了这些概念,多通道卷积如下图所示,将每个kernels应用到前一层的输入通道上,以生成一个输出通道,这是一个kernels方面的过程。我们为所有kernels重复这样的过程以生成多个通道。然后将这些通道中的每一个加在一起以形成单个输出通道。
这里输入层是一个5 x 5 x 3矩阵,有3个通道,filters是3 x 3 x 3矩阵。首先,filters中的每个kernels分别应用于输入层中的三个通道,执行三次卷积,产生3个尺寸为3×3的通道:
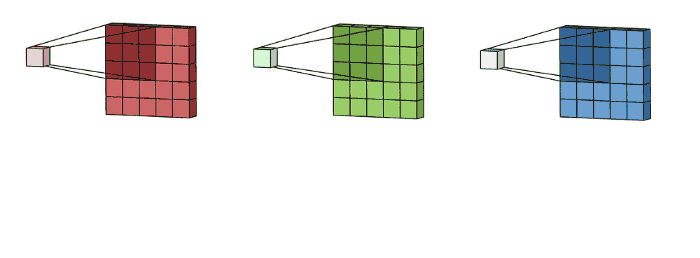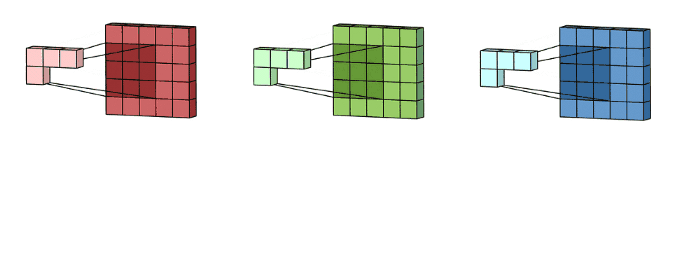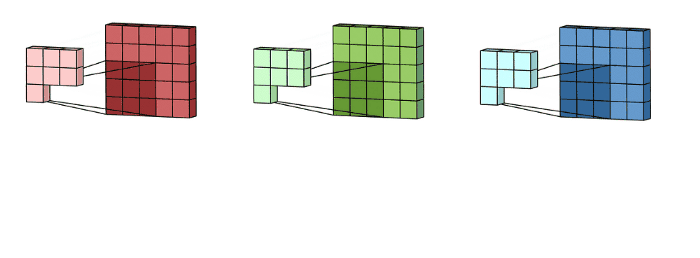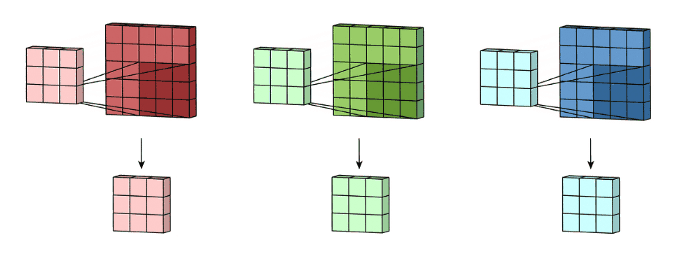
多通道2D卷积的第一步:将filters中的每个kernels分别应用于输入层中的三个通道
然后将这三个通道相加(逐个元素相加)以形成一个单个通道(3 x 3 x 1),该通道是使用filters(3 x 3 x 3矩阵)对输入层(5 x 5 x 3矩阵)进行卷积的结果:
多通道2D卷积的第二步:将这三个通道加在一起(逐元素加法)以形成一个单个通道
可以将这个过程视作将一个3D-filters矩阵滑动通过输入层。注意,这个输入层和filters的深度都是相同的(即通道数=卷积核数)。这个 3D-filters仅沿着 2 个方向(图像的高和宽)移动(这也是为什么 3D-filters即使通常用于处理3D-体积数据,但这样的操作还是被称为 2D-卷积)。

现在我们可以看到如何在不同深度的层之间实现过渡,假设输入层有 Din 个通道,而想让输出层的通道数量变成 Dout,我们需要做的仅仅是将 Dout个filters应用到输入层中。每一个filters都有Din个卷积核,都提供一个输出通道。在应用Dout个filters后,Dout个通道可以共同组成一个输出层。标准 2D-卷积,通过使用 Dout 个filters,将深度为 Din 的层映射为另一个深度为 Dout 的层。

标准2D卷积:使用Dout个filters将深度为Din的一层映射到深度为Dout的另一层
进一步地,对于卷积网络的设计需要记住以下公式(2D卷积的计算):输入层: W i n ∗ H i n ∗ D i n W_{in}*H_{in}*D_{in} Win∗Hin∗Din
超参数:
- filters个数: k k k
- filters中卷积核维度: w ∗ h w∗h w∗h
- 滑动步长(Stride): s s s
- 填充值(Padding): p p p
输出层: W o u t ∗ H o u t ∗ D o u t W_{out}*H_{out}*D_{out} Wout∗Hout∗Dout
其中输出层和输入层之间的参数关系为,

参数量为: ( w ∗ h ∗ D i n + 1 ) ∗ k (w*h*D_{in} + 1)*k (w∗h∗Din+1)∗k
马同学
从数学上讲,卷积就是一种运算。
某种运算,能被定义出来,至少有以下特征:
首先是抽象的、符号化的
其次,在生活、科研中,有着广泛的作用
比如加法:
[公式] ,是抽象的,本身只是一个数学符号
在现实中,有非常多的意义,比如增加、合成、旋转等等
卷积,是我们学习高等数学之后,新接触的一种运算,因为涉及到积分、级数,所以看起来觉得很复杂。
1 卷积的定义

这两个式子有一个共同的特征:

这个特征有什么意义?


如果遍历这些直线,就好比,把毛巾沿着角卷起来:
此处受到 荆哲:卷积为什么叫「卷」积? 答案的启发。
只看数学符号,卷积是抽象的,不好理解的,但是,我们可以通过现实中的意义,来习惯卷积这种运算,正如我们小学的时候,学习加减乘除需要各种苹果、糖果来帮助我们习惯一样。
我们来看看现实中,这样的定义有什么意义。
2 离散卷积的例子:丢骰子
我有两枚骰子:

把这两枚骰子都抛出去:

求:

这里问题的关键是,两个骰子加起来要等于4,这正是卷积的应用场景。
我们把骰子各个点数出现的概率表示出来:

那么,两枚骰子点数加起来为4的情况有:




3 连续卷积的例子:做馒头
楼下早点铺子生意太好了,供不应求,就买了一台机器,不断的生产馒头。

4 图像处理
4.1 原理
有这么一副图像,可以看到,图像上有很多噪点:

高频信号,就好像平地耸立的山峰:

看起来很显眼。
平滑这座山峰的办法之一就是,把山峰刨掉一些土,填到山峰周围去。用数学的话来说,就是把山峰周围的高度平均一下。
平滑后得到:

4.2 计算
卷积可以帮助实现这个平滑算法。
有噪点的原图,可以把它转为一个矩阵:

记得刚才说过的算法,把高频信号与周围的数值平均一下就可以平滑山峰。
比如我要平滑 [公式] 点,就在矩阵中,取出 [公式] 点附近的点组成矩阵 [公式] ,和 [公式] 进行卷积计算后,再填回去:

要注意一点,为了运用卷积, [公式] 虽然和 [公式] 同维度,但下标有点不一样:

我用一个动图来说明下计算过程:



此图出处:Convolutional Neural Networks - Basics
palet
1. 对卷积的困惑
卷积这个概念,很早以前就学过,但是一直没有搞懂。教科书上通常会给出定义,给出很多性质,也会用实例和图形进行解释,但究竟为什么要这么设计,这么计算,背后的意义是什么,往往语焉不详。作为一个学物理出身的人,一个公式倘若倘若给不出结合实际的直观的通俗的解释(也就是背后的“物理”意义),就觉得少了点什么,觉得不是真的懂了。

并且也解释了,先对g函数进行翻转,相当于在数轴上把g函数从右边褶到左边去,也就是卷积的“卷”的由来。
然后再把g函数平移到n,在这个位置对两个函数的对应点相乘,然后相加,这个过程是卷积的“积”的过程。
这个只是从计算的方式上对公式进行了解释,从数学上讲无可挑剔,但进一步追问,为什么要先翻转再平移,这么设计有何用意?还是有点费解。
在知乎,已经很多的热心网友对卷积举了很多形象的例子进行了解释,如卷地毯、丢骰子、打耳光、存钱等等。读完觉得非常生动有趣,但过细想想,还是感觉有些地方还是没解释清楚,甚至可能还有瑕疵,或者还可以改进(这些后面我会做一些分析)。
带着问题想了两个晚上,终于觉得有些问题想通了,所以就写出来跟网友分享,共同学习提高。不对的地方欢迎评论拍砖。。。
明确一下,这篇文章主要想解释两个问题:
-
- 卷积这个名词是怎么解释?“卷”是什么意思?“积”又是什么意思?
-
- 卷积背后的意义是什么,该如何解释?
2. 考虑的应用场景
为了更好地理解这些问题,我们先给出两个典型的应用场景:
1. 信号分析
一个输入信号f(t),经过一个线性系统(其特征可以用单位冲击响应函数g(t)描述)以后,输出信号应该是什么?实际上通过卷积运算就可以得到输出信号。
2. 图像处理
输入一幅图像f(x,y),经过特定设计的卷积核g(x,y)进行卷积处理以后,输出图像将会得到模糊,边缘强化等各种效果。
对卷积的理解
对卷积这个名词的理解:所谓两个函数的卷积,本质上就是先将一个函数翻转,然后进行滑动叠加。
在连续情况下,叠加指的是对两个函数的乘积求积分,在离散情况下就是加权求和,为简单起见就统一称为叠加。
整体看来是这么个过程:
翻转——>滑动——>叠加——>滑动——>叠加——>滑动——>叠加…
多次滑动得到的一系列叠加值,构成了卷积函数。
卷积的“卷”,指的的函数的翻转,从 g(t) 变成 g(-t) 的这个过程;同时,“卷”还有滑动的意味在里面(吸取了网友李文清的建议)。如果把卷积翻译为“褶积”,那么这个“褶”字就只有翻转的含义了。
卷积的“积”,指的是积分/加权求和。
有些文章只强调滑动叠加求和,而没有说函数的翻转,我觉得是不全面的;有的文章对“卷”的理解其实是“积”,我觉得是张冠李戴。
对卷积的意义的理解:
-
- 从“积”的过程可以看到,我们得到的叠加值,是个全局的概念。以信号分析为例,卷积的结果是不仅跟当前时刻输入信号的响应值有关,也跟过去所有时刻输入信号的响应都有关系,考虑了对过去的所有输入的效果的累积。在图像处理的中,卷积处理的结果,其实就是把每个像素周边的,甚至是整个图像的像素都考虑进来,对当前像素进行某种加权处理。所以说,“积”是全局概念,或者说是一种“混合”,把两个函数在时间或者空间上进行混合。
-
- 那为什么要进行“卷”?直接相乘不好吗?我的理解,进行“卷”(翻转)的目的其实是施加一种约束,它指定了在“积”的时候以什么为参照。在信号分析的场景,它指定了在哪个特定时间点的前后进行“积”,在空间分析的场景,它指定了在哪个位置的周边进行累积处理。
3. 举例说明
下面举几个例子说明为什么要翻转,以及叠加求和的意义。
例1:信号分析
如下图所示,输入信号是 f(t) ,是随时间变化的。系统响应函数是 g(t) ,图中的响应函数是随时间指数下降的,它的物理意义是说:如果在 t=0 的时刻有一个输入,那么随着时间的流逝,这个输入将不断衰减。换言之,到了 t=T时刻,原来在 t=0 时刻的输入f(0)的值将衰减为f(0)g(T)。

考虑到信号是连续输入的,也就是说,每个时刻都有新的信号进来,所以,最终输出的是所有之前输入信号的累积效果。如下图所示,在T=10时刻,输出结果跟图中带标记的区域整体有关。其中,f(10)因为是刚输入的,所以其输出结果应该是f(10)g(0),而时刻t=9的输入f(9),只经过了1个时间单位的衰减,所以产生的输出应该是 f(9)g(1),如此类推,即图中虚线所描述的关系。这些对应点相乘然后累加,就是T=10时刻的输出信号值,这个结果也是f和g两个函数在T=10时刻的卷积值。

显然,上面的对应关系看上去比较难看,是拧着的,所以,我们把g函数对折一下,变成了g(-t),这样就好看一些了。看到了吗?这就是为什么卷积要“卷”,要翻转的原因,这是从它的物理意义中给出的。

上图虽然没有拧着,已经顺过来了,但看上去还有点错位,所以再进一步平移T个单位,就是下图。它就是本文开始给出的卷积定义的一种图形的表述:

所以,在以上计算T时刻的卷积时,要维持的约束就是: t+ (T-t) = T 。这种约束的意义,大家可以自己体会。
例2:丢骰子
在本问题 如何通俗易懂地解释卷积?中排名第一的 马同学在中举了一个很好的例子(下面的一些图摘自马同学的文章,在此表示感谢),用丢骰子说明了卷积的应用。
要解决的问题是:有两枚骰子,把它们都抛出去,两枚骰子点数加起来为4的概率是多少?

分析一下,两枚骰子点数加起来为4的情况有三种情况:1+3=4, 2+2=4, 3+1=4
因此,两枚骰子点数加起来为4的概率为:

写成卷积的方式就是:

在这里我想进一步用上面的翻转滑动叠加的逻辑进行解释。
首先,因为两个骰子的点数和是4,为了满足这个约束条件,我们还是把函数 g 翻转一下,然后阴影区域上下对应的数相乘,然后累加,相当于求自变量为4的卷积值,如下图所示:

进一步,如此翻转以后,可以方便地进行推广去求两个骰子点数和为 n 时的概率,为f 和 g的卷积 f*g(n),如下图所示:

由上图可以看到,函数 g 的滑动,带来的是点数和的增大。这个例子中对f和g的约束条件就是点数和,它也是卷积函数的自变量。有兴趣还可以算算,如果骰子的每个点数出现的概率是均等的,那么两个骰子的点数和n=7的时候,概率最大。
例3:图像处理
还是引用知乎问题 如何通俗易懂地解释卷积?中 马同学的例子。图像可以表示为矩阵形式(下图摘自马同学的文章):

对图像的处理函数(如平滑,或者边缘提取),也可以用一个g矩阵来表示,如:

从卷积定义来看,应该是在x和y两个方向去累加(对应上面离散公式中的i和j两个下标),而且是无界的,从负无穷到正无穷。可是,真实世界都是有界的。例如,上面列举的图像处理函数g实际上是个3x3的矩阵,意味着,在除了原点附近以外,其它所有点的取值都为0。考虑到这个因素,上面的公式其实退化了,它只把坐标(u,v)附近的点选择出来做计算了。所以,真正的计算如下所示:

首先我们在原始图像矩阵中取出(u,v)处的矩阵:


请注意,以上公式有一个特点,做乘法的两个对应变量a,b的下标之和都是(u,v),其目的是对这种加权求和进行一种约束。这也是为什么要将矩阵g进行翻转的原因。以上矩阵下标之所以那么写,并且进行了翻转,是为了让大家更清楚地看到跟卷积的关系。这样做的好处是便于推广,也便于理解其物理意义。实际在计算的时候,都是用翻转以后的矩阵,直接求矩阵内积就可以了。
以上计算的是(u,v)处的卷积,延x轴或者y轴滑动,就可以求出图像中各个位置的卷积,其输出结果是处理以后的图像(即经过平滑、边缘提取等各种处理的图像)。
再深入思考一下,在算图像卷积的时候,我们是直接在原始图像矩阵中取了(u,v)处的矩阵,为什么要取这个位置的矩阵,本质上其实是为了满足以上的约束。因为我们要算(u,v)处的卷积,而g矩阵是3x3的矩阵,要满足下标跟这个3x3矩阵的和是(u,v),只能是取原始图像中以(u,v)为中心的这个3x3矩阵,即图中的阴影区域的矩阵。
推而广之,如果如果g矩阵不是3x3,而是7x7,那我们就要在原始图像中取以(u,v)为中心的7x7矩阵进行计算。由此可见,这种卷积就是把原始图像中的相邻像素都考虑进来,进行混合。相邻的区域范围取决于g矩阵的维度,维度越大,涉及的周边像素越多。而矩阵的设计,则决定了这种混合输出的图像跟原始图像比,究竟是模糊了,还是更锐利了。

4. 对一些解释的不同意见
上面一些对卷积的形象解释,如知乎问题卷积为什么叫「卷」积?中 荆哲 ,以及问题 如何通俗易懂地解释卷积?中 马同学 等人提出的如下比喻:

其实图中“卷”的方向,是沿该方向进行积分求和的方向,并无翻转之意。因此,这种解释,并没有完整描述卷积的含义,对“卷”的理解值得商榷。
一些参考资料
《数字信号处理(第二版)》程乾生,北京大学出版社
《信号与系统引论》 郑君里,应启珩,杨为理,高等教育出版社
https://www.zhihu.com/question/22298352

















 6763
6763

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









