







最近在学习爬虫,做个笔记吧

今天爬xx政府网站-政策法规栏目的数据
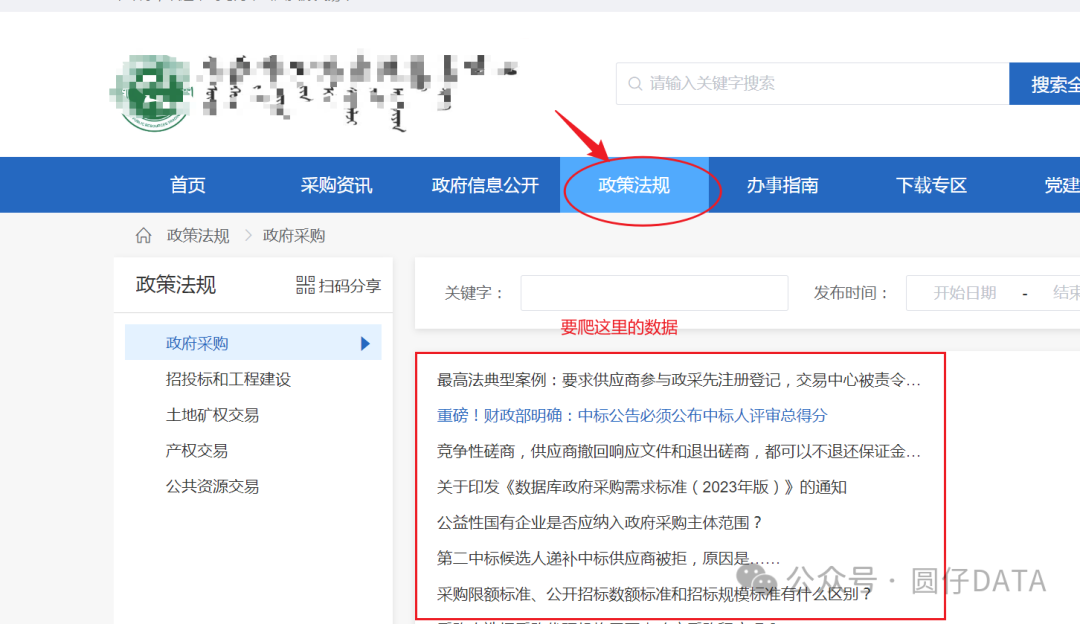
咱们首先需要找到数据从哪里来,鼠标右键->检查(或者快捷键一般为F12)检查元素,搜索关键词
eg.【违法案例】
回车,
如果没有的话,可以尝试刷新页面后重新回车搜索关键词
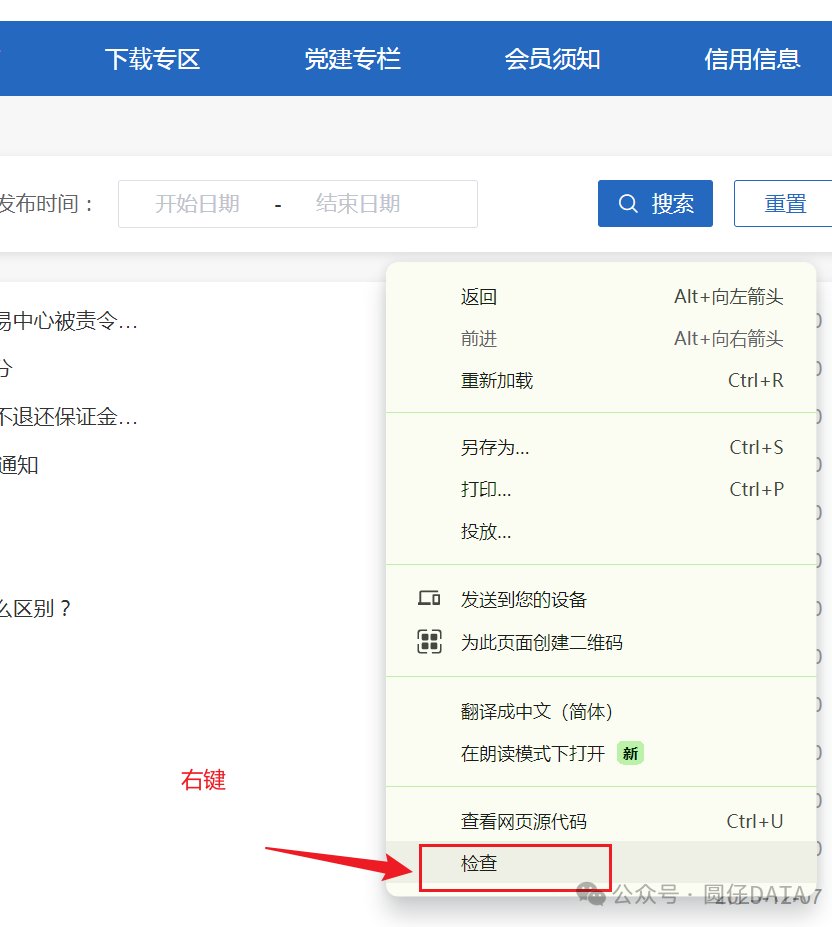
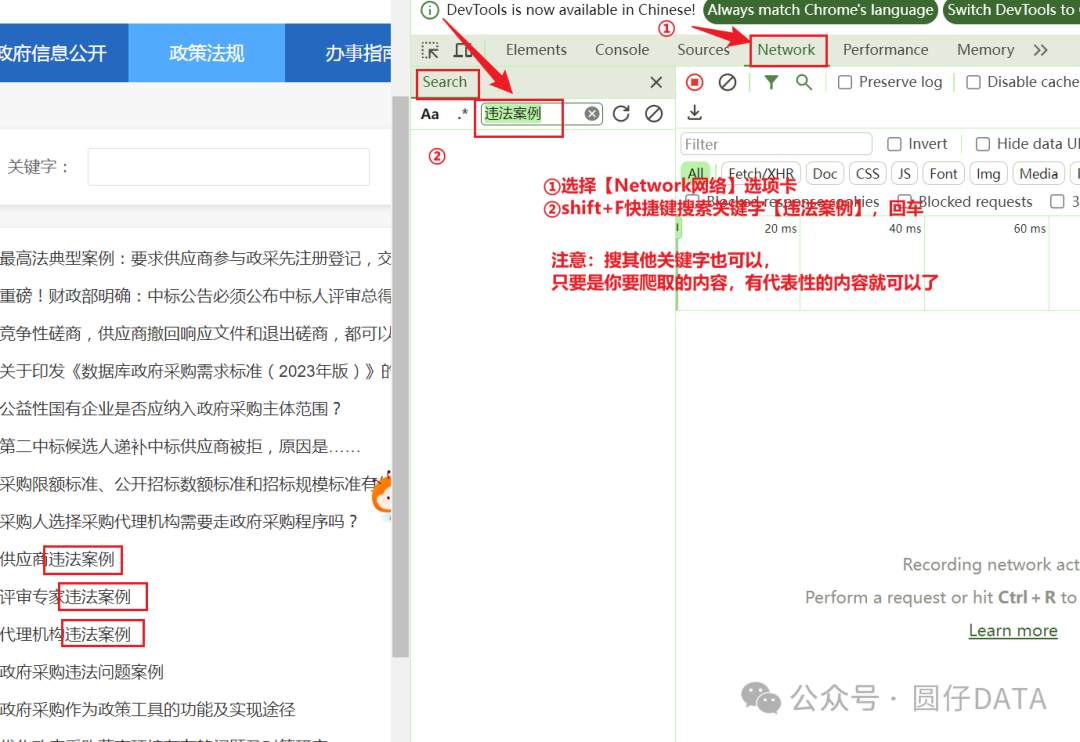
选中其中一个出现的搜索结果,
最近在学习爬虫,做个笔记吧
今天爬xx政府网站-政策法规栏目的数据
咱们首先需要找到数据从哪里来,鼠标右键->检查(或者快捷键一般为F12)检查元素,搜索关键词
eg.【违法案例】
回车,
如果没有的话,可以尝试刷新页面后重新回车搜索关键词
选中其中一个出现的搜索结果,
 1313
1097
1313
1097

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章























