






Motivation:
大多数基于语料的语言处理都集中于英文这种语言,很少有针对中文提出的词性标注系统,本文想把对英文处理方面的技术应用到中文上来,实现对中文的词性标注。由于中文句子之间没有空格,因此在进行词性标注之前必须对中文进行分词,而分词的质量又直接影响到词性标注的结果。因此本文搭建一个和分词结合的中文词性标注系统。
核心思想:
本文用最大熵算法https://blog.csdn.net/ccblogger/article/details/81843304从中文分词的处理结构和特征表示方面寻找一个最优的分词方法。
- 处理结构:在进行词性标注任务时,①分词之后再词性标注;②分词和词性标注同时进行。
- 特征表示:在词性标注时,是以单词为单位进行标注还是以字符为单位进行标注。在以字符为单位时,一个单词中的字符具有相同词性。
实验结果:
在分词完成之后,用Beam search选择每个单词或字符可能的词性,这里N=3,即对于每个单词选择三个最有可能的标注,然后用最大熵算法计算最有可能的一组词性。
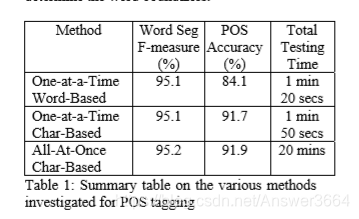
从上面的表中可以看出,One-at-a-Time Word-Based模型在词性标注问题上效果最差。All-At-Once Char-Based模型能够取得最好的效果,但是会花费较大的开销。而Once-at-a-Time Char-Based模型的效果接近All-At-Once Char-Based,但是开销较少。因此All-At-Once Char-Based算法也是折中的选择。
启发:
- 和英文标注不同,中文词性标注以字符为单位的效果更好;
- 分词和标注同时进行的效果比分开进行标注效果好,但会增加开销;
- 添加更多的匹配特征和后处理可以提高模型的准确率,但是匹配特征的增加可能会带来过拟合问题。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









