







熵的概念在统计学习与机器学习中真是很重要,熵的介绍在这里:信息熵 。今天的主题是最大熵模型(Maximum Entropy Model,以下简称MaxEnt),MaxEnt 是概率模型学习中一个准则,其思想为:在学习概率模型时,所有可能的模型中熵最大的模型是最好的模型;若概率模型需要满足一些约束,则最大熵原理就是在满足已知约束的条件集合中选择熵最大模型。最大熵原理指出,对一个随机事件的概率分布进行预测时,预测应当满足全部已知的约束,而对未知的情况不要做任何主观假设。在这种情况下,概率分布最均匀,预测的风险最小,因此得到的概率分布的熵是最大。
直观理解 MaxEnt
在求解概率模型时,当没有任何约束条件则只需找到熵最大的模型,比如预测一个骰子的点数,每个面为 1/6, 当模型有一些约束条件之后,首先要满足这些约束条件, 然后在满足约束的集合中寻找熵最大的模型,该模型对未知的情况不做任何假设,未知情况的分布是最均匀的。举例来说对于随机变量 X ,其可能的取值为 {A,B,C} ,没有任何约束的情况下下,各个值等概率得到的 MaxEnt 模型为:

当给定一个约束 P(A)=1/2 , 满足该约束条件下的 MaxEnt 模型是:

如果用欧式空间中的 simplex 来表示随机变量 X 的话,则 simplex 中三个顶点分别代表随机变量 X 的三个取值 A, B, C , 这里定义 simplex 中任意一点 p 到三条边的距离之和(恒等于三角形的高)为 1,点到其所对的边为该取值的概率,比如任给一点 p ,则P(A)等于 p 到 边 BC 的距离,如果给定如下概率:

分别用下图表示以上两种情况:
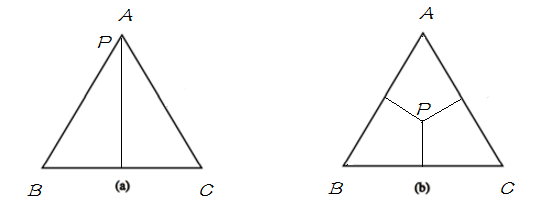
明白了 simplex 的定义之后,将其与概率模型联系起来,在 simplex 中,不加任何约束,整个概率空间的取值可以是 simplex 中的任意一点,只需找到满足最大熵条件的的即可;当引入一个约束条件![]() 后,如下图中 (b),模型被限制在
后,如下图中 (b),模型被限制在![]() 表示的直线上,则应在满足约束
表示的直线上,则应在满足约束![]() 的条件下来找到熵最大的模型;当继续引入条件
的条件下来找到熵最大的模型;当继续引入条件![]() 后,如图(c),模型被限制在一点上,即此时有唯一的解;当
后,如图(c),模型被限制在一点上,即此时有唯一的解;当![]() 与
与![]() 不一致时,如图(d),此时模型无法满足约束,即无解。在 MaxEnt 模型中,由于约束从训练数据中取得,所以不会出现不一致。即不会出现(d) 的情况。
不一致时,如图(d),此时模型无法满足约束,即无解。在 MaxEnt 模型中,由于约束从训练数据中取得,所以不会出现不一致。即不会出现(d) 的情况。

接下来以统计建模的形式来描述 MaxEnt 模型,给定训练数据 ![]() ,现在要通过Maximum Entrop 来建立一个概率判别模型,该模型的任务是对于给定的 X=x 以条件概率分布P(Y|X=x)预测 YY 的取值。根据训练语料能得出 (X,Y) 的经验分布, 得出部分(X,Y)的概率值,或某些概率需要满足的条件,即问题变成求部分信息下的最大熵或满足一定约束的最优解,约束条件是靠特征函数来引入的,首先先回忆一下函数期望的概念
,现在要通过Maximum Entrop 来建立一个概率判别模型,该模型的任务是对于给定的 X=x 以条件概率分布P(Y|X=x)预测 YY 的取值。根据训练语料能得出 (X,Y) 的经验分布, 得出部分(X,Y)的概率值,或某些概率需要满足的条件,即问题变成求部分信息下的最大熵或满足一定约束的最优解,约束条件是靠特征函数来引入的,首先先回忆一下函数期望的概念
对于随机变量 X=xi,i=1,2,…,则可以得到:
随机变量期望: 对于随机变量 XX ,其数学期望的形式为
随机变量函数期望:若 Y=f(X) ,则关于 XX 的函数 YY 的期望:
.
特征函数
特征函数f(x,y)描述x与y之间的某一事实,其定义如下:

特征函数f(x,y)是一个二值函数, 当x与y满足事实时取值为 1 ,否则取值为 0 。比如对于如下数据集:

数据集中,第一列为 Y ,右边为 X ,可以为该数据集写出一些特征函数,数据集中得特征函数形式如下:

为每个 <feature,label> 对 都做一个如上的特征函数,用来描述数据集数学化。
约束条件
接下来看经验分布,现在把训练数据当做由随机变量 (X,Y) 产生,则可以根据训练数据确定联合分布的经验分布 ![]() 与边缘分布的经验分布
与边缘分布的经验分布 ![]() :
:

用![]() 表示特征函数f(x,y)关于经验分布
表示特征函数f(x,y)关于经验分布![]() 的期望,可得:
的期望,可得:

![]() 前面已经得到了,数数f(x,y)的次数就可以了,由于特征函数是对建立概率模型有益的特征,所以应该让 MaxEnt 模型来满足这一约束,所以模型P(Y|X)关于函数 f的期望应该等于经验分布关于 f的期望,模型 P(Y|X)关于 f的期望为:
前面已经得到了,数数f(x,y)的次数就可以了,由于特征函数是对建立概率模型有益的特征,所以应该让 MaxEnt 模型来满足这一约束,所以模型P(Y|X)关于函数 f的期望应该等于经验分布关于 f的期望,模型 P(Y|X)关于 f的期望为:

经验分布与特征函数结合便能代表概率模型需要满足的约束,只需使得两个期望项相等, 即 ![]() :
:

上式便为 MaxEnt 中需要满足的约束,给定 nn 个特征函数![]() ,则有 n个约束条件,用 C表示满足约束的模型集合:
,则有 n个约束条件,用 C表示满足约束的模型集合:
![]()
从满足约束的模型集合 C 中找到使得 P(Y|X) 的熵最大的即为 MaxEnt 模型了。
最大熵模型
关于条件分布 P(Y|X)的熵为:

首先满足约束条件然后使得该熵最大即可,MaxEnt 模型 ![]() 为:
为:
![]()
综上给出形式化的最大熵模型:
给定数据集
,特征函数 fi(x,y),i=1,2…,n,根据经验分布得到满足约束集的模型集合 C :

MaxEnt 模型的求解
MaxEnt 模型最后被形式化为带有约束条件的最优化问题,可以通过拉格朗日乘子法将其转为无约束优化的问题,引入拉格朗日乘子:
![]() , 定义朗格朗日函数 L(P,w):
, 定义朗格朗日函数 L(P,w):

现在问题转化为: ![]() ,拉格朗日函数 L(P,w) 的约束是要满足的 ,如果不满足约束的话,只需令
,拉格朗日函数 L(P,w) 的约束是要满足的 ,如果不满足约束的话,只需令![]() ,则可得
,则可得![]() ,因为需要得到极小值,所以约束必须要满足,满足约束后可得:
,因为需要得到极小值,所以约束必须要满足,满足约束后可得: ![]() ,现在问题可以形式化为便于拉格朗日对偶处理的极小极大的问题:
,现在问题可以形式化为便于拉格朗日对偶处理的极小极大的问题:
![]()
由于 L(P,w)是关于 P 的凸函数,根据拉格朗日对偶可得 L(P,w)的极小极大问题与极大极小问题是等价的:
![]()
现在可以先求内部的极小问题![]() 得到的解为关于 w 的函数,可以记做 Ψ(w) :
得到的解为关于 w 的函数,可以记做 Ψ(w) :
![]()
上式的解 ![]() 可以记做:
可以记做:
![]()
由于求解 P的最小值![]() ,只需对于 P(y|x) 求导即可,令导数等于 0 即可得到
,只需对于 P(y|x) 求导即可,令导数等于 0 即可得到![]() :
:

由于 ![]() ,可得:
,可得:

进而可以得到:

这里 ![]() 起到了归一化的作用,令
起到了归一化的作用,令 ![]() 表示
表示 ![]() ,便得到了 MaxEnt 模型 :
,便得到了 MaxEnt 模型 :

这里![]() 代表特征函数,
代表特征函数,![]() 代表特征函数的权值,
代表特征函数的权值, ![]() 即为 MaxEnt 模型,现在内部的极小化求解得到关于 w的函数,现在求其对偶问题的外部极大化即可,将最优解记做
即为 MaxEnt 模型,现在内部的极小化求解得到关于 w的函数,现在求其对偶问题的外部极大化即可,将最优解记做 ![]() :
:
![]()
所以现在最大上模型转为求解 ![]() 的极大化问题,求解最优的
的极大化问题,求解最优的 ![]() 后, 便得到了所要求的MaxEnt 模型,将
后, 便得到了所要求的MaxEnt 模型,将 ![]() 带入
带入 ![]() ,可得:
,可得:

以上推倒第二行到第三行用到以下结论:

倒数第二行到最后一行是由于:![]() ,最终通过一系列极其复杂的运算,得到了需要极大化的式子:
,最终通过一系列极其复杂的运算,得到了需要极大化的式子:

极大化似然估计解法
这太难了,有没有简单又 work 的方式呢? 答案是有的,就是极大似然估计 MLE 了,这里有训练数据得到经验分布 ![]() , 待求解的概率模型 P(Y|X) 的似然函数为:
, 待求解的概率模型 P(Y|X) 的似然函数为:

将 ![]() 带入以下公式可以得到:
带入以下公式可以得到:

我们发现,我们从最大熵的思想出发得出的最大熵模型,最后的最大化求解就是在求P(y|x)的对数似然最大化。逻辑回归也是在求条件概率分布关于样本数据的对数似然最大化。二者唯一的不同就是条件概率分布的表示形式不同。
显而易见,拉格朗日对偶得到的结果与极大似然得到的结果时等价的,现在只需极大化似然函数即可,顺带优化目标中可以加入正则项,这是一个凸优化问题,一般的梯度法、牛顿法都可解之,专门的算法有GIS IIS 算法。
《统计学习方法》中有非常详细的使用IIS优化目标函数的过程。
算法的推导比较麻烦,但思路是清晰的:

最大熵模型在分类方法里算是比较优的模型,但是由于它的约束函数的数目一般来说会随着样本量的增大而增大,导致样本量很大的时候,对偶函数优化求解的迭代过程非常慢,scikit-learn甚至都没有最大熵模型对应的类库。但是理解它仍然很有意义,尤其是它和很多分类方法都有千丝万缕的联系。
我们总结下最大熵模型作为分类方法的优缺点:
最大熵模型的优点有:
a) 最大熵统计模型获得的是所有满足约束条件的模型中信息熵极大的模型,作为经典的分类模型时准确率较高。
b) 可以灵活地设置约束条件,通过约束条件的多少可以调节模型对未知数据的适应度和对已知数据的拟合程度
最大熵模型的缺点有:
a) 由于约束函数数量和样本数目有关系,导致迭代过程计算量巨大,实际应用比较难。
Reference
[1]https://www.cnblogs.com/ooon/p/5677098.html















 9189
9189

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









