






原文链接:Batch/Layer normalization有什么区别?
大家好,我是泰哥。在训练模型前,我们通常要对数据进行归一化处理来加速模型收敛。本文为大家介绍batch normalization和layer normalization的使用场景。
1 为什么ML中用BN比较多?
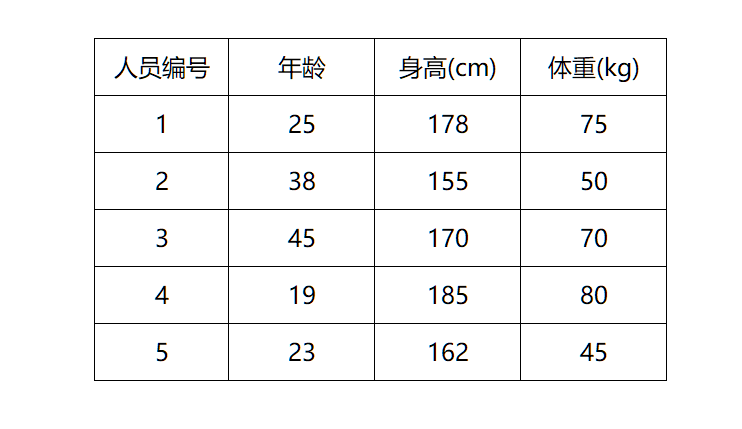
现在有一个batch内的人员特征数据,分别是年龄、身高和体重,我们需要根据这3个特征进行性别预测,在预测之前首先要进行归一化处理。
ML & batch normalization
BN是针对每一列特征进行归一化,例如下图中计算的均值:
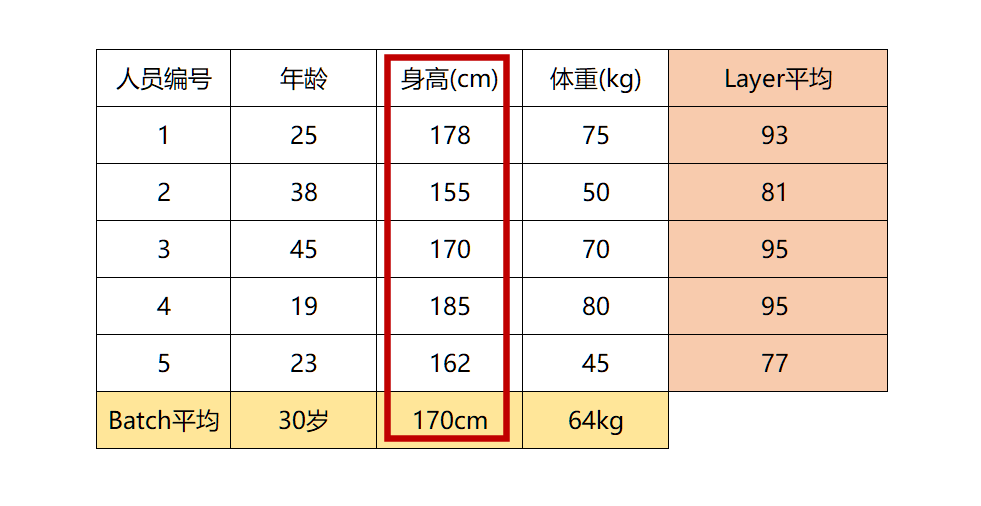
BN这是一种“列归一化”,同一batch内的数据的同一纬度做归一化,因此有3个维度就有3个均值。
ML & layer normalization
而LN则相反,它是针对数据的每一行进行归一化。即只看一条数据,算出这条数据所有特征的均值,例如下图:
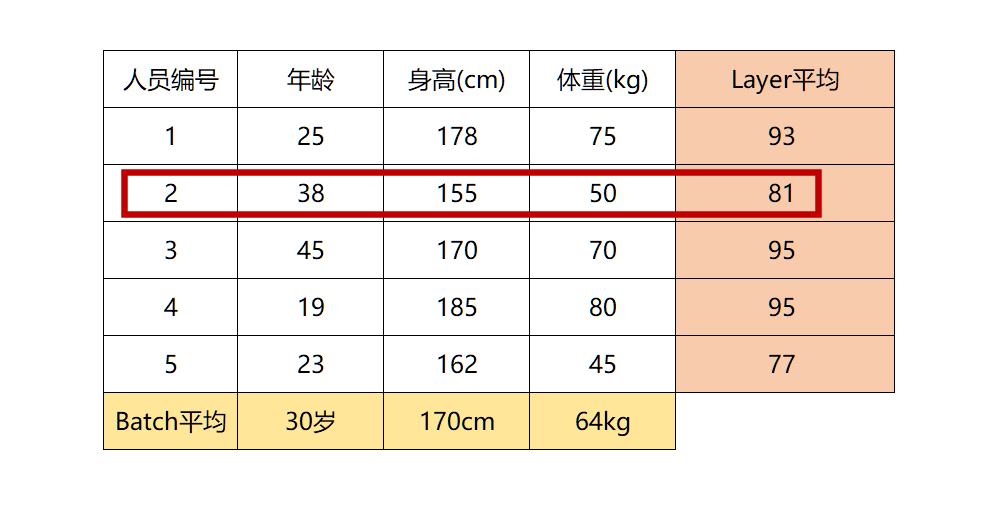
LN是一种“行归一化”,是对单个样本的所有维度来做归一化。
Why ML&BN?
这里大家就可以看出,LN计算出一个人的年龄、身高、体重这三个特征的均值并对其归一化,完全没有道理和可解释性,但是BN则没有这个影响,因为每列的单位属性都是相同的。
在机器学习任务中,数据往往是每列数据为一特征,处理的数据通常具有解释性,而列与列之间的单位属性并不相同,所以机器学习任务中用BN比较多。
2 为什么NLP中用LN比较多?

上图是4条文本数据组成了一个batch,我们假设每个字的embedding都为1。
NLP & batch normalization
那么BN是针对每一列特征进行归一化,就会把4条文本相同位置的字来做归一化处理,例如:天、公、要、影。

而这样做的话就破坏了一个字在原句中的原有含义。
NLP & layer normalization
而LN则是针对每一句话做归一化处理。

在归一化后使一句话中的embedding处于同分布。
3 根本原因
在ML中输入的数据一般是矩阵,每列数据都具有相同属性,所以使用BN较多。
在NLP中,因为数据维度一般都是[batch_size, seq_len, dim_size],我们最终希望将一句话中的词向量进行归一化,所以使用LN较多。
4 总结
从操作过程上来讲,BN针对的是同一个batch内的所有数据,而LN则是针对单个样本。
从特征维度来说,BN对同一batch内的数据的同一纬度做归一化,因此有多少维度就有多少个均值和方差;而LN则是对单个样本的所有维度来做归一化,因此一个batch中就有batch_size个均值和方差。
更多AI干货尽在公众号【AI有温度】
















 1639
1639











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









