






在使用pandas的df进行筛选的时候出现报错:
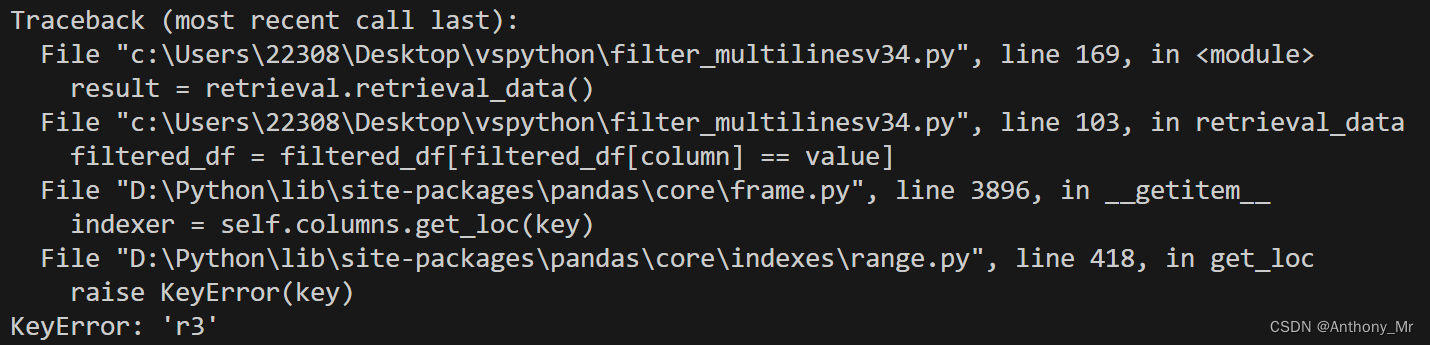
核心问题在于对df筛选的时候索引列不在dataframe的范围内了。查询gpt有以下几种可能:
-
访问不存在的列:
df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]}) print(df['C']) # KeyError: 'C'在这个例子中,df中没有名为
'C'的列,所以会引发KeyError。 -
访问不存在的行索引:
df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]}, index=['a', 'b', 'c']) print(df.loc['d']) # KeyError: 'd'这里尝试访问不存在的行索引
'd',也会引发KeyError。 -
使用
dict键访问不存在的列:data = {'A': [1, 2, 3], 'B': [4, 5, 6]} df = pd.DataFrame(data) print(df['C']) # KeyError: 'C'与第一种情况类似,在
dict中不存在'C'这个键。 -
使用
iloc访问超出范围的位置:df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]}) print(df.iloc[3, 0]) # KeyError: 3这里尝试访问超出 DataFrame 行数范围的位置
3,会引发KeyError。
另一个关键点:
pandas在读取Excel的时候默认NA为NaN,即空值。但此时在Excel中"NA"表现为字符串,如果直接在df中筛选"NA"就会无法匹配。
解决办法:
使用pd.read_excel()函数时,并设置na_filter参数为False。这样 Pandas 就不会自动将NA识别为缺失值,而是会将其读取为字符串类型,如下:
df = pd.read_excel('your_excel_file.xlsx', na_filter=False)














 601
601

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









