










淘宝商品详情数据采集是一个涉及多个步骤的过程,主要目的是获取商品的各种详细信息,如商品属性、规格、价格、详情图等。以下是一个基本的采集流程:
- 确定采集目标:首先,需要明确要采集的淘宝商品范围,例如特定类目的商品、特定店铺的商品或特定关键词搜索结果的商品。
- 使用爬虫工具或API:为了获取商品详情数据,可以选择使用爬虫工具或淘宝提供的API接口。如果使用爬虫工具,需要编写相应的代码来模拟浏览器行为,发送请求并解析返回的HTML页面。如果使用API接口,则需要按照淘宝的开放平台文档进行请求和参数设置。
- 发送请求并获取数据:通过爬虫或API接口,向淘宝服务器发送请求,获取商品详情页面的数据。这通常包括商品的标题、价格、销量、评论、详情图等信息。
- 解析数据:从返回的HTML页面或JSON数据中提取出所需的信息。这可能需要使用正则表达式、XPath、CSS选择器等技术来定位和提取特定的数据元素。
- 存储和处理数据:将解析出的数据存储到数据库或文件中,以便后续分析和使用。同时,可能还需要对数据进行清洗和格式化,以确保数据的准确性和一致性。
- 注意事项:在进行淘宝商品详情数据采集时,需要注意以下几点:
- 遵守淘宝的使用协议和开放平台规则,不要进行恶意爬取或滥用数据。
- 注意爬虫的请求频率和并发量,避免对淘宝服务器造成过大的压力或触发反爬虫机制。
- 尊重用户隐私和知识产权,不要采集和使用涉及个人隐私或侵权的信息。
最后,需要注意的是,淘宝的商品详情数据可能会随着时间和市场变化而发生变化,因此采集到的数据可能不是完全准确或实时的。在进行数据分析和决策时,需要考虑到这一因素。
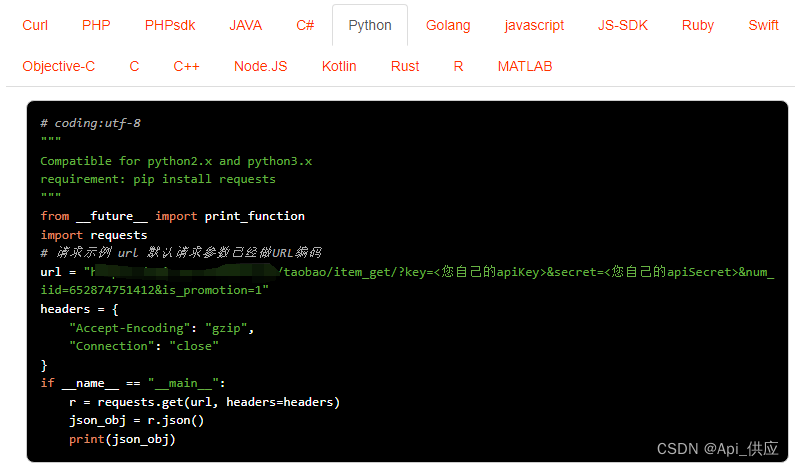
请求示例,API接口接入Anzexi58

















 2401
2401

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









