







1、base64编码原理分析:
(1)、背景与应用:
可参考博客:Base64编码原理与应用
所谓base64就是基于ASCII码的64个可见字符子集的一种编码方式。
(2)、编码原理与核心分析:
上面提到的子集如下所示:
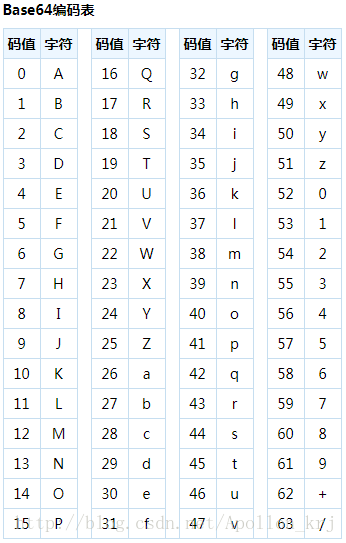
A~Z、a~z、0~9、+、/共64个字符。
base64编码方式要点:
①分组:对需要编码的数据流(字节流)进行分组,三个字节为一组,若是最后一组不足3个字节,则对该分组后面补充0补足3个字节。然后将3byte(3 * 8=24bit)等分为4部分,每部分6bit(4 * 6=24bit)。将每一部分的6bit作为一个字节的低6位,高2位均填充0。即将3个字节变为4个字节。
②替换:由于6bit可表示最大值为63(111111),将6bit的信息作为Base64编码表的索引,索引到的字符即为该6bit信息编码得到的编码结果。因此3byte编码会得到4个字符。
③结尾处理:对于数据流中分组产生的6bit,如果为全0,即索引到的字符为‘A’,但是对于结尾不满3byte而补充的0,分组要进行特殊处理,用’=’来替换(由于’=’只在结尾可能存在,因此不算入编码表中)。
举例分析:
0110 0001 0100 0000,该二进制流(字节流)共2个字节,其ASCII码的字符分别为a、@。其base64编码结果为“YUA=”。

又如:0110 0001 0100 0000 0110 0001 0110 0001的编码结果为“YUBhYQ==”。

(3)、解码:
对于解码,其实就是编码的逆过程:将得到的base64编码信息分为4字节一组,由4个字符值反推出其索引,然后将四个索引的低6bit共24bit拼接成完整的三个字节,得到24bit数据流(可能还需要一步:将3个字节的ASCII字符再算出来)。
需要注意:在编程时,由于逆向解码,对于已知字符求其索引,需要进行整个表的遍历,若需要解密的数据较大,则其效率是相当低的。因此我们可以做一个逆向索引的表,该表以64个字符的ASCII作为索引index,而以正向索引表的索引作为逆向索引表的值。如下为正向编码索引表(64个有效值):
static const char base64[64] =
{
'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H',
'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P',
'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X',
'Y', 'Z', 'a', 'b', 'c', 'd', 'e', 'f',
'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n',
'o', 'p', 'q', 'r', 's', 't', 'u', 'v',
'w', 'x', 'y', 'z', '0', '1', '2', '3',
'4', '5', '6', '7', '8', '9', '+', '/'
};而逆向解码索引表如下所示(65个有效的值):
static const char base64_back[128] =
{
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 62, -1, -1, -1, 63,
52, 53, 54, 55, 56, 57, 58, 59, 60, 61, -1, -1, -1, 0, -1, -1,
-1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14,
15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, -1, -1, -1, -1, -1,
-1, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40,
41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, -1, -1, -1, -1, -1,
};2、代码编写与程序测试:
以下程序采用命令行输入的方式编解码进行测试:
(1)输入格式处理程序文件:
//fileName:formatDeal.cpp
#include <string.h>
#include <stdlib.h>
#include <stdio.h>
#include "base64.h"
int main(int argc, char **argv)
{
if(argc != 3){
printf("number of parameter error:\n");
printf("\t./base64 -d(e) text\n");
exit(EXIT_FAILURE);
}
int argv_e = strcmp(argv[1], "-e");
int argv_d = strcmp(argv[1], "-d");
if( !argv_e ){//text encrypt
base64_encrypt_text(argv[2], strlen(argv[2]));
}
else if( !argv_d ){//text decrypt
base64_decrypt_text(argv[2], strlen(argv[2]));
}
else{
printf("type of parameter error:\n");
printf("\t./base64 -d(e) text\n");
exit(EXIT_FAILURE);
}
return 0;
}(2)base64编码程序文件:
/*****************************************************************
* FileName:base64.cpp
* Time: 2017-12-11 20:54:21
* Author: KangRuojin
* Mail: mailbox_krj@163.com
* Version: v1.1
*
* c - ciphertext
* p - plaintext
******************************************************************/
#include <string.h>
#include <stdlib.h>
#include <stdio.h>
#include "base64.h"
static const char base64[64] =
{
'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H',
'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P',
'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X',
'Y', 'Z', 'a', 'b', 'c', 'd', 'e', 'f',
'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n',
'o', 'p', 'q', 'r', 's', 't', 'u', 'v',
'w', 'x', 'y', 'z', '0', '1', '2', '3',
'4', '5', '6', '7', '8', '9', '+', '/'
};
/*
* 以base64的编码值作为索引进行原index的索引.即逆转换表
* 首先,A~Z、a~z、0~9、+、/共64个符号
* 这64个符号(ASCII)作为base64_back[]的索引,其在base64[]中的索引作为base64_back[]的索引值
* 其次,由于编码中'=(ASCII为61)'是由补的0转换成的,所以在逆转换表中index=61的位置,值为0
* 其他index值均为-1
*/
static const char base64_back[128] =
{
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 62, -1, -1, -1, 63,
52, 53, 54, 55, 56, 57, 58, 59, 60, 61, -1, -1, -1, 0, -1, -1,
-1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14,
15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, -1, -1, -1, -1, -1,
-1, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40,
41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, -1, -1, -1, -1, -1,
};
void base64_encrypt_text(const char * pbuf,int plen)
{
int clen = (plen % 3) ? (plen/3 + 1) : (plen/3);
char * buf = (char *)malloc(clen*3);
char * cbuf = (char *)malloc(clen * 4);
if(NULL == cbuf || NULL == buf){
exit(EXIT_FAILURE);
}
memset(cbuf, 0, clen*4);
memset(buf, 0, clen*3);
memcpy(buf, pbuf, plen);
//编码转换
for(int i = 0; i < clen; i++){
base64_encrypt(&buf[i*3], &cbuf[i*4]);
}
//由于对于0进行了统一的base6_encrypt(),所以需要对末尾的'A'进行修正为'='
if(plen % 3 == 2){//只补一个字节,对应一个'='
cbuf[clen*4 - 1] = '=';
}
else if(plen % 3 == 1){//补两个字节则对应两个'='
cbuf[clen*4 - 1] = cbuf[clen*4 - 2] = '=';
}
show_base64(cbuf, clen*4);
free(buf);
free(cbuf);
}
void base64_decrypt_text(const char * cbuf,int clen)
{
int plen = clen/4;
char * pbuf = (char *)malloc(plen*3);
if(NULL == pbuf){
exit(EXIT_FAILURE);
}
memset(pbuf, 0, plen*3);
for(int i = 0; i < plen; i++){
base64_decrypt(&cbuf[i*4], &pbuf[i*3]);
}
show_base64(pbuf, plen*3);
free(pbuf);
}
void base64_encrypt(const char * pbuf, char * cbuf)
{
int temp = (pbuf[0] << 16) | (pbuf[1] << 8) | (pbuf[2] << 0);
for(int i = 0; i<4; i++){
int index = (temp >> (18-i*6)) & 0x3F;
cbuf[i] = base64[index];
}
}
void base64_decrypt(const char * cbuf, char * pbuf)
{
int temp = 0;
for(int i = 0; i<4; i++){//反向索引,根据编码求得原index并进行移位异或
temp |= base64_back[cbuf[i]] << (18-6*i);//temp的高1byte未使用
}
for(int i = 0; i<3; i++){//移位异或得到的temp的低三byte分别为原有三个byte
pbuf[i] = (temp >> (16-i*8)) & 0XFF;
}
}
void show_base64(const char * buf, int len)
{
for(int i=0; i<len; i++){
printf("%c",buf[i]);
}
printf("\n");
}
测试结果(可能存在脚本识别问题,所以text参数需要加单引号):

此外,base64还用于图片编码,图片编码属于文件处理,需要在formatDeal.cpp和base64.cpp中再添加关于文件处理的部分即可。















 5109
5109

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









