







本文内容基于《算法笔记》和官方配套练题网站“晴问算法”,是我作为小白的学习记录,如有错误还请体谅,可以留下您的宝贵意见,不胜感激。
前言
图,直观来理解就是地图,是一种逻辑结构为非线性的数据结构,是一种多对多的数据结构,每一个顶点都可以作为起点和终点,将图拆分开就是由若干棵树构成的森林。
一、图的定义及相关术语
1.图的定义:图由顶点和边构成,每条边的两个端点必须是图的两个顶点,采用
G(V,E)表示图G的顶点集为V、边集为E。
一般来说,图可分为有向图和无向图。有向图的所有边都有方向,即确定了顶点到顶点的一个指向:而无向图的所有边都是双向的,即无向边所连接的两个顶点可以互相到达。在一些问题中,可以把无向图当作所有边都是正向和负向的两条有向边组成,这对解决一些问题很有帮助。
2.顶点的度:
3.定点的权值:
二、图的存储
图的核心是边,边中存放了连通的重要信息,所以如何存储边是图存储的核心。
1.领接矩阵:
领接矩阵通过散列来将顶点的编号作为二维数组下标,数组空间内存放边的信息,可以是边存在的信息,也可以是边的权值。这样就将任意两个顶点之间的边关系表示出来了。领接矩阵只适用于顶点数目不大于1000的问题(10^6就超过了一般问题的存储空间)。通过实例来体会一下:

在保证除无向图之外的题干不变的情况下,分别写出无向图和有向图领接矩阵,注意这里输出的领接矩阵并不是图的遍历,图的遍历是需要按照若干个顶点为起点,通过路径(边)来遍历图的过程,并不单单是输出顶点信息就可以了。顶点编号小于顶点数,这一点非常人性,不会出现中间有空的情况;完整代码如下:
无向图:
#include<cstdio>
#include<cstring>
const int MAXN = 100;
int martix[MAXN][MAXN] = {};
int main(){
int n , m;
scanf("%d%d", &n , &m);
for(int i = 0; i <= m - 1; i++){
int u , v;
scanf("%d%d", &u , &v);
martix[u][v] = 1;
martix[v][u] = 1;
}
for(int i = 0; i <= n - 1; i++){
for(int j = 0; j <= n - 1; j++){
printf("%d", martix[i][j]);
if(j < n - 1) printf(" ");
}
printf("\n");
}
}
有向图:
#include<cstdio>
#include<cstring>
const int MAXN = 100;
int martix[MAXN][MAXN] = {};
int main(){
int n , m;
scanf("%d%d", &n , &m);
for(int i = 0; i <= m - 1; i++){
int u , v;
scanf("%d%d", &u , &v);
martix[u][v] = 1;
}
for(int i = 0; i <= n - 1; i++){
for(int j = 0; j <= n - 1; j++){
printf("%d", martix[i][j]);
if(j < n - 1) printf(" ");
}
printf("\n");
}
}
2.领接链表:领接链表采用拉链法进行存储,将所有顶点编号(起点地址)散列到一个一维数组的下标或者链表中,通过链表将每个顶点的所有出边链在顶点后,这样的存储结构称为邻接表,记为Adj[N]。对于一般问题来说,可以使用vector来存储顶点的出边信息。通过实例来体会一下:

在保证除无向图之外的题干不变的情况下,分别写出无向图和有向图领接表,注意这里输出的领接表并不是图的遍历,图的遍历是需要按照若干个顶点为起点,通过路径(边)来遍历图的过程,并不单单是输出顶点信息就可以了。完整代码如下:
无向图:
#include<cstdio>
#include<vector>
using namespace std;
const int MAXN = 100;
vector <int> Adj[MAXN];
int main(){
int n , m;
scanf("%d%d", &n , &m);
for(int i = 0; i <= m - 1; i++){
int u , v;
scanf("%d%d", &u , &v);
Adj[u].push_back(v);
Adj[v].push_back(u);
}
for(int i = 0; i <= n - 1; i++){
printf("%d(%d)", i , Adj[i].size());
if(Adj[i].size() > 0) printf(" ");
for(vector <int> :: iterator it = Adj[i].begin(); it != Adj[i].end(); it++){
if(it != Adj[i].begin()) printf(" ");
printf("%d", *it);
}
printf("\n");
}
}
有向图:
#include<cstdio>
#include<vector>
using namespace std;
const int MAXN = 100;
vector <int> Adj[MAXN];
int main(){
int n , m;
scanf("%d%d", &n , &m);
for(int i = 0; i <= m - 1; i++){
int u , v;
scanf("%d%d", &u , &v);
Adj[u].push_back(v);
}
for(int i = 0; i <= n - 1; i++){
printf("%d(%d)", i , Adj[i].size());
if(Adj[i].size() > 0) printf(" ");
for(vector <int> :: iterator it = Adj[i].begin(); it != Adj[i].end(); it++){
if(it != Adj[i].begin()) printf(" ");
printf("%d", *it);
}
printf("\n");
}
}
三、图的遍历
图是逻辑结构为非线性的数据结构,所以需要采用DFS和BFS来遍历。DFS和BFS的思想和性质前面已经写过了,岔道口为从某个顶点出发能到达的所有顶点,死胡同为不存在可以到达的其他顶点。这里直接给出模板:
DFS:
DFS(u){ //访问顶点
vis[u] = true; //设置u已被访问
for(从u出发能到达的所有顶点) //枚举从u出发可以到达的所有顶点v
if vis[v] == false //如果v未被访问
DFS(v); //递归访问v
}
DFSTrave(G){ //遍历图G
for(G的所有顶点u) //对G的所有顶点u
if vis[u] == false //如果u未被访问
DFS(u); //访问u所在的连通块
}
BFS:
BFS(u){ //遍历u所在的连通块
queue q; //定义队列q
将u入队;
inq[u] = true; //设置u已被加入过队列
while(q非空){ //只要队列非空
取出q的队首元素u进行访问;
for(从u出发可达的所有顶点v) //枚举从u能直接到达的顶点v
if(inq[v] == false) //如果v未曾加入过队列
将v入队;
inq[v] = true; //设置v已被加入过队列
}
}
BFSTrave(G){ //遍历图G
for(G的所有顶点u) //对G的所有顶点u
if vis[u] == false //如果u未曾入过队列
DFS(u); //遍历u所在的连通块
}
这里需要注意下,一次DFS和BFS只能访问以一个顶点为起点的子图,即只能访问一个连通子图或强连通子图(有向图的一次遍历结果并不一定是强连通子图);若要遍历整个图,就需要散列表记录访问过的结点,防止反复访问和死递归;并且需要遍历全部未访问过的顶点为起点,这样才能遍历整张图。
通过例题来体会一下:
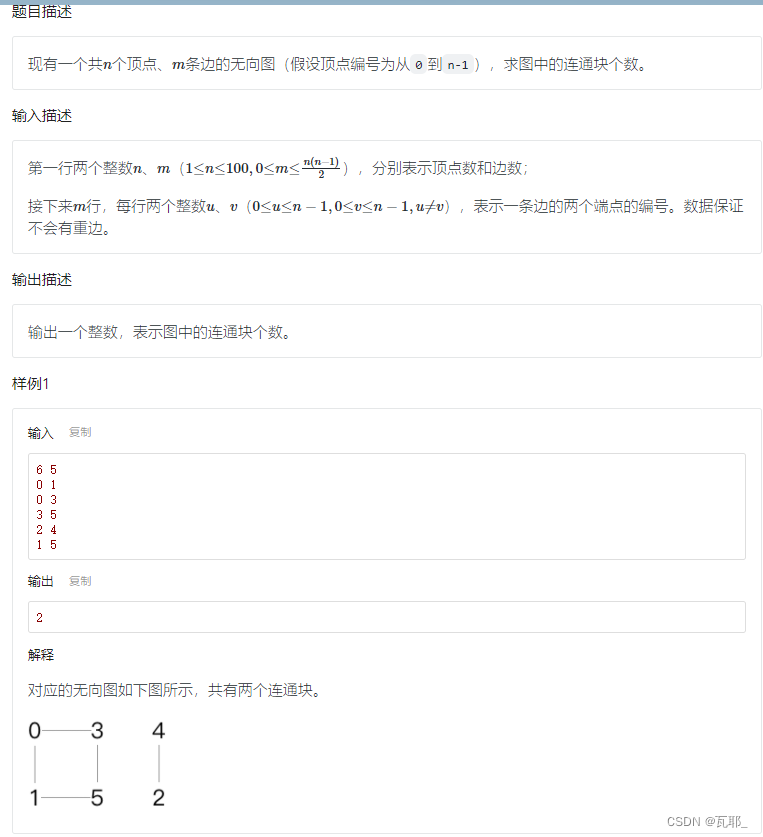
这道题采用DFS+邻接表求解(一般这个组合适用范围更广),连通块的个数就是起点遍历的次数。完整代码如下:
#include<cstdio>
#include<vector>
#include<algorithm>
#include<cstring>
using namespace std;
const int MAXN = 100;
vector <int> Adj[MAXN];
bool hashTable[MAXN];
void DFS(int index){
hashTable[index] = true;
for(int i = 0; i < Adj[index].size(); i++){ //递归边界为第二个表达式
int v = Adj[index][i];
if(!hashTable[v]) { //没被访问过
DFS(v);
}
}
}
void DFSTrave(int n){ //n为顶点数
int ans = 0;
for(int i = 0; i <= n - 1; i++)
if(!hashTable[i]) {
DFS(i);
ans++;
}
printf("%d", ans);
}
int main(){
int n , m;
scanf("%d%d", &n , &m);
for(int i = 0; i <= m - 1; i++){
int u , v;
scanf("%d%d", &u , &v);
Adj[u].push_back(v);
Adj[v].push_back(u);
}
DFSTrave(n);
return 0;
}
四、其余小题联系
1.无向连通图
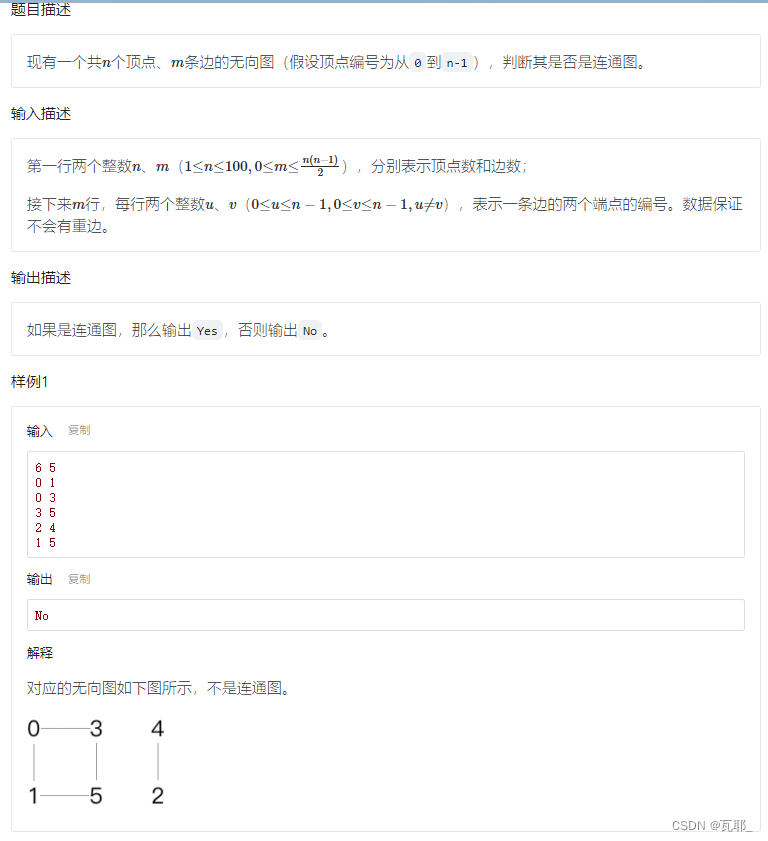
只要无法通过一次遍历得到整个图的信息,就不是连通图,这道题采用BFS+领接矩阵实现,完整代码如下:
#include<cstdio>
#include<algorithm>
#include<queue>
using namespace std;
const int MAXN = 100;
int martix[MAXN][MAXN] = {};
bool hashTable[MAXN] = {}; //判断入队
void BFS(int u , int n){
queue <int> qe;
qe.push(u);
hashTable[u] = true;
while(!qe.empty()){
int top = qe.front();
qe.pop();
for(int v = 0; v < n; v++) //注意体会数组中某顶点能到达的所有顶点是怎么样表示的
if(martix[top][v] == 1 && hashTable[v] == false){
qe.push(v);
hashTable[v] = true;
}
}
}
void BFSTrave(int n){ //n为顶点数
bool flag = false;
for(int i = 0; i <= n - 1; i++){
if(!hashTable[i]) { //第二次进(连通子图数量大于1)就结束
if(flag) {
printf("No");
return;
}
BFS(i , n);
flag = true;
}
}
printf("Yes");
}
int main(){
int n , m;
scanf("%d%d", &n , &m);
for(int i = 0; i <= m - 1; i++){
int u , v;
scanf("%d%d", &u , &v);
martix[u][v] = 1;
martix[v][u] = 1;
}
BFSTrave(n);
}
2.有向图判环
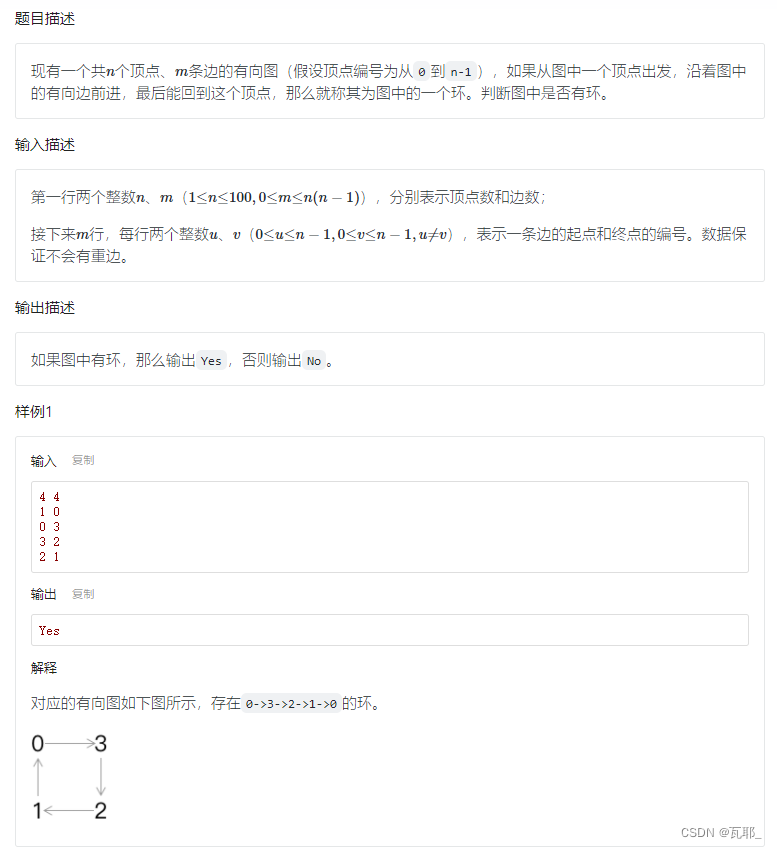
思路:只要在一次遍历中,某一步回到了曾经走过的结点,就存在环;
实现:采用DFS+领接链表实现,定义bool变量flag作为标志,如果走到曾经走过的顶点,更新flag,注意还原散列表状态,不要影响到下一次DFS。此外,可以进行回溯优化,即如果存在环就不需要继续往下遍历了。
完整代码如下:
#include<cstdio>
#include<vector>
using namespace std;
const int MAXN = 100;
vector <int> Adj[MAXN];
bool hashTable[MAXN] = {};
bool flag = false; //是否存在环
void DFS(int index){
if(flag == true) return; //回溯
if(hashTable[index] == true) { //返回走过的顶点,构成环
printf("Yes");
flag = true;
return; //返回,停止往下走
}
hashTable[index] = true;
for(int i = 0; i < Adj[index].size(); i++){
int v = Adj[index][i];
DFS(v); //注意这里不论是否走过都要走
}
hashTable[index] = false; //注意还原状态 ,不要影响其他路径
}
void DFSTrave(int n){ //n为顶点数
int ans = 0;
for(int i = 0; i <= n - 1; i++){
if(!hashTable[i]) DFS(i);
if(flag == true) return;
}
printf("No");
}
int main(){
int n , m;
scanf("%d%d", &n , &m);
for(int i = 0; i <= m - 1; i++){
int u , v;
scanf("%d%d", &u , &v);
Adj[u].push_back(v);
}
DFSTrave(n);
}
4.最大权值连通块
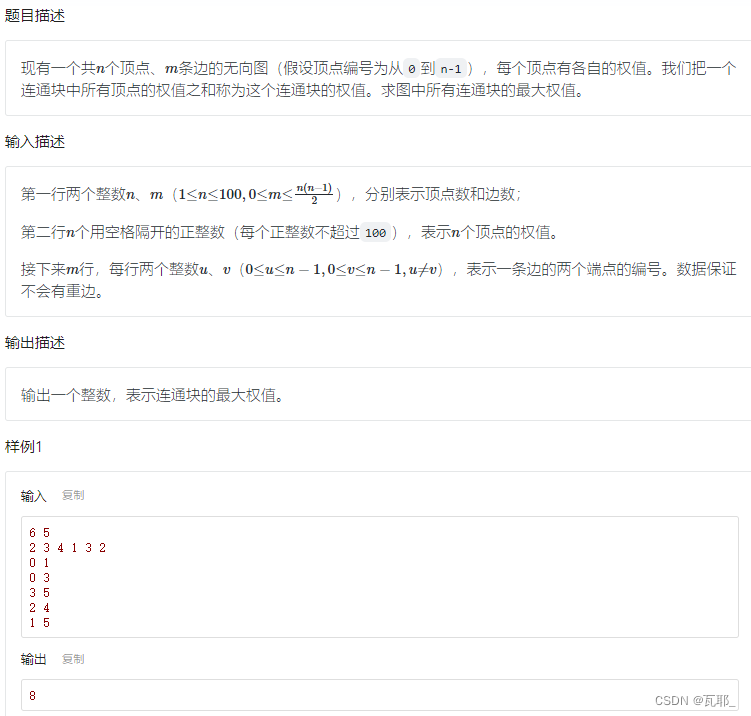
思路:简化题干,所要表达的就是将一次遍历中走过的所有顶点权值信息相加比大小(注意不是边权,两个的存储方式和遍历方式有所不同,备注里有写);
实现:开一个变量保存所有走过顶点的权值信息即可,每进行一次遍历就进行一次比大小;
完整代码如下:
#include<cstdio>
#include<vector> //相当于求一整棵树的所有点的权值和
#include<algorithm>
using namespace std;
const int MAXN = 100;
int weight[MAXN] = {}; //点权
vector <int> Adj[MAXN];
bool hashTable[MAXN];
int maxans = 0;
int ans = 0;
void DFS(int index){
hashTable[index] = true;
ans += weight[index];
for(int i = 0; i < Adj[index].size(); i++){ //递归边界为第二个表达式
int v = Adj[index][i];
if(!hashTable[v]) { //没被访问过
DFS(v);
}
}
}
void DFSTrave(int n){ //n为顶点数
for(int i = 0; i <= n - 1; i++){
if(!hashTable[i]) DFS(i);
if(ans > maxans) maxans = ans;
ans = 0;
}
printf("%d", maxans);
}
int main(){
int n , m;
scanf("%d%d", &n , &m);
for(int i = 0; i <= n - 1; i++){
scanf("%d", &weight[i]);
}
for(int i = 0; i <= m - 1; i++){
int u , v;
scanf("%d%d", &u , &v);
Adj[u].push_back(v);
Adj[v].push_back(u);
}
DFSTrave(n);
}
5.无向图的顶点层号
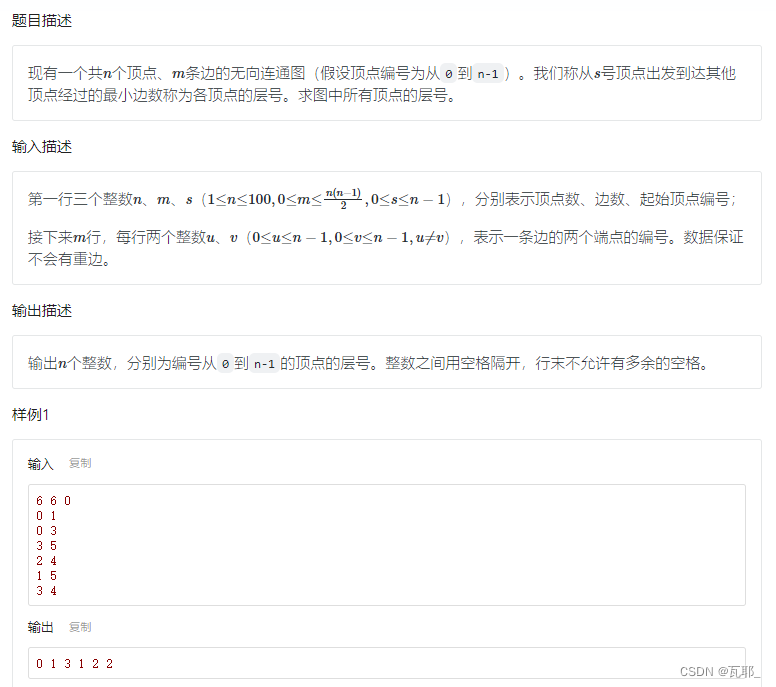
思路:这道题类似BFS章节中的一道小题,这是经典的求任意顶点间的最短路径问题,采用BFS+邻接表解决(原因可以去BFS章节里找),遍历到的结点层号就是最小边数。
实现:BFS+领接链表,由于本题是连通图,所以只需要一次BFS即可遍历整张图。
完整代码如下:
#include<cstdio>
#include<queue>
#include<vector>
#include<cstring>
using namespace std;
const int MAXN = 100;
vector <int> Adj[MAXN];
bool hashTable[MAXN] = {};
int step[MAXN]; //记录点的最小层数
void BFS(int index){
queue <int> qe;
qe.push(index);
hashTable[index] = true;
step[index] = 0;
while(!qe.empty()){
int top = qe.front();
qe.pop();
hashTable[top] = true;
for(int i = 0; i < Adj[top].size(); i++){
int v = Adj[top][i];
if(!hashTable[v]){
qe.push(v);
hashTable[v] = true; //顶点入队
step[v] = step[top] + 1;
}
}
}
}
int main(){
memset(step , -1 , sizeof(step));
int n , m , s;
scanf("%d%d%d", &n , &m , &s);
for(int i = 0; i <= m - 1; i++){
int u , v;
scanf("%d%d", &u , &v);
Adj[u].push_back(v);
Adj[v].push_back(u);
}
BFS(s);
for(int i = 0; i <= n - 1; i++){
printf("%d", *(step + i));
if(i < n - 1) printf(" ");
}
}
备注
1.一次遍历得到的连通块可能代表多条路径,相当于是一棵树;
2.注意区分边权和点权的存储以及遍历方式, 边权可以采用结构体存储,将边权信息(或者边信息)保存在领接矩阵元素中或者邻接表的出边结点信息中;而点权(或者顶点信息)需要采用散列表的形式,将对应顶点的编号(地址)当做下标,将点权当做下标元素内容;
3.一般采用静态写法,除非是节点编号不连续或者根本没有编号或者是插入和删除操作频繁(线性链表)时采用指针法链表实现。树可以采用静态写法和动态写法,图可以采用领接矩阵和领接链表实现,其中领接矩阵采用静态写法实现,领接链表可以采用静态写法和指针写法。
4.结构化分析解决图问题,先处理存储问题,再处理遍历问题,最后根据题意在遍历的过程中“添油加醋”;
5.本小章节,说白了就是掌握图的定义及存储,然后将DFS和BFS进行知识连接的过程,关于图的定义和存储可以通过数据结构书籍进行进一步了解和巩固。
















 600
600











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











